协同过滤源代码在真实数据集上运行及优化
最近在做推荐算法相关研究,
先拿一个协同过滤代码练手。
网上找代码很容易,但是大多是讲原理的示例代码,在真实数据集上运行问题特别多。
以一个2w节点的开源数据集为例(baby.inter)
https://github.com/enoche/MMRec/
https://drive.google.com/drive/folders/13cBy1EA_saTUuXxVllKgtfci2A09jyaG?usp=sharing
列举一些我遇到的问题:
1.稀疏矩阵占用内存过大,使用coo_matrix可以极大减少占用
2.矩阵类型转换过程中维度经常出错,矩阵读取某列的方法和稀疏矩阵读某列的方法返回格式不同
3.使用多线程提速的过程中内存溢出,导致部分线程崩溃,运行结束后只得到一半结果。
4.获取结果的语句嵌套过多难以理解,例如:recommendations = unrated_items[np.argsort(-pred[unrated_items])][0:top_k]
5.格式转换不当导致内存溢出(64g内存的电脑啊,直接蓝屏了)
6.np.save np.savez不会用。
下面直接上代码
1.读取数据,这里数据的最后一位是训练集、验证集、测试集的划分标签。chatGPT写了几遍也不对,还是自己写的。
# 数据读取
def load_data(file_path):
train_data_u = []
train_data_i = []
train_data_r = []
val_data_u = []
val_data_i = []
val_data_r = []
test_data_u = []
test_data_i = []
test_data_r = []
with open(file_path) as file:
next(file) # 跳过第一行
for line in file:
line = line.strip().split("\t")
userID = int(line[0])
itemID = int(line[1])
rating = float(line[2])
x_label = line[4]
if x_label == '0':
train_data_u.append(userID)
train_data_i.append(itemID)
train_data_r.append(rating)
elif x_label == '1':
val_data_u.append(userID)
val_data_i.append(itemID)
val_data_r.append(rating)
elif x_label == '2':
test_data_u.append(userID)
test_data_i.append(itemID)
test_data_r.append(rating)
num_users = max(train_data_u) + 1
num_items = max(train_data_i) + 1
train_data_matrix = coo_matrix((train_data_r, (train_data_u,train_data_i)), shape=(num_users, num_items))
val_data_matrix = coo_matrix((val_data_r, (val_data_u,val_data_i)), shape=(num_users, num_items))
test_data_matrix = coo_matrix((test_data_r, (test_data_u,test_data_i)), shape=(num_users, num_items))
return train_data_matrix, val_data_matrix,test_data_matrix2.训练模型,这里很多代码都只获取用户相似度,然后在预测过程中用户相似度乘评分矩阵得到相似用户的评分和。但是把矩阵乘法运算放在这里只需要计算1次,减少了约2w次的大规模矩阵乘法运算。
函数返回的矩阵每行表示某个用户对所有物品的评分。(这里把每个矩阵的维度都列举出来就能分析清楚了,我只是做笔记,懒得写。)矩阵每列表示一个商品。
# 模型训练
def train_model(data_matrix):
similarity_matrix = cosine_similarity(data_matrix, dense_output=False)
pred=similarity_matrix.dot(data_matrix)
print(pred)
return pred3.预测用户评分,这里注意tocsr(),被坑了好久,coo_matrix可以直接进行点乘运算,但是不能做切片运算,切片出来某一行也和普通矩阵索引出来某行不一样。
然后就是非常复杂的排序运算,这里实在无法优化,也是整个代码最耗时的部分,因为要执行大约2w次。
def predict(ratings,pred, user_id, top_k):
pred1=pred.tocsr()[user_id].toarray()[0]
ratings1=ratings.tocsr()[user_id].toarray()[0]
unrated_items = np.where(ratings1 == 0)[0]
sort_index=np.argsort(-pred1[unrated_items])
sort_items=unrated_items[sort_index]
# 根据预测评分生成推荐列表
recommendations =sort_items [0:top_k]
return recommendations4.评价函数,没什么说的,gpt写的直接拿来用
# 评估指标
def evaluate_recommendations(recommendations, test_matrix, k):
num_users, num_items = test_matrix.shape
recall = 0.0
ndcg = 0.0
precision = 0.0
map_value = 0.0
for user_id in range(num_users):
test_ratings = test_matrix[user_id]
if np.sum(test_ratings) > 0:
relevant_items = np.where(test_ratings > 0)[0]
recall += len(set(recommendations[user_id]) & set(relevant_items)) / len(relevant_items)
dcg = 0.0
idcg = np.log2(2)
for i in range(k):
item_id = recommendations[user_id][i]
if item_id in relevant_items:
dcg += 1 / np.log2(i + 2)
ndcg += dcg / idcg
precision += len(set(recommendations[user_id]) & set(relevant_items)) / k
ap = 0.0
for i in range(k):
item_id = recommendations[user_id][i]
if item_id in relevant_items:
ap += len(set(recommendations[user_id]) & set(relevant_items)) / (i + 1)
ap /= len(relevant_items)
map_value += ap
recall /= num_users
ndcg /= num_users
precision /= num_users
map_value /= num_users
return recall, ndcg, precision, map_value5.主函数,写主函数一部分是c语言的习惯,另一部分是随时可以用return打断,否则当执行到thread.join时代码无法ctrl+c打断,只能直接关控制台。(哦,我都是记事本写代码,在控制台执行,没有IDE)
def printTime():
print(f"[{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]}]")
def main():
print('start')
printTime()
# 数据路径
file_path = "..\\MMRec-master\\data\\baby\\baby.inter"
# 加载数据
train_matrix, val_matrix,test_matrix = load_data(file_path)
# 训练
pred = train_model(train_matrix)
print(pred.toarray()[0])
# 生成推荐
top_k = 10
recommendations = {}
recommendations[0]=(predict(train_matrix,pred,0, top_k))
print(recommendations[0])
print(len(recommendations))
#return
# 创建一个线程列表
threads = []
num_threads=16
# 将用户数量按照线程数进行划分
user_per_thread = test_matrix.shape[0] // num_threads
# 定义一个函数,用于并行计算推荐结果
def calculate_recommendations(start, end):
print(start,end)
for user_id in range(start, end):
recommendations[user_id] = predict(train_matrix, pred, user_id, top_k)#2.82G
if(user_id%500==0):
print(user_id)
for i in range(num_threads):
start = i * user_per_thread
end = (i+1) * user_per_thread
# 创建并启动一个新线程
t = threading.Thread(target=calculate_recommendations, args=(start, end))
t.start()
threads.append(t)
# 等待所有线程完成
for t in threads:
t.join()
start= int( test_matrix.shape[0] // num_threads)*num_threads
end=test_matrix.shape[0]
calculate_recommendations(start, end)
printTime()
np.savez('data.npz',recommendations=recommendations,test_matrix=test_matrix)
'''data=np.load('data.npz',allow_pickle=True)
recommendations=data['recommendations'].item();
test_matrix=data['test_matrix'].item();'''
# 评估指标
recall, ndcg, precision, map_value = evaluate_recommendations(recommendations, test_matrix.toarray(), top_k)
printTime()
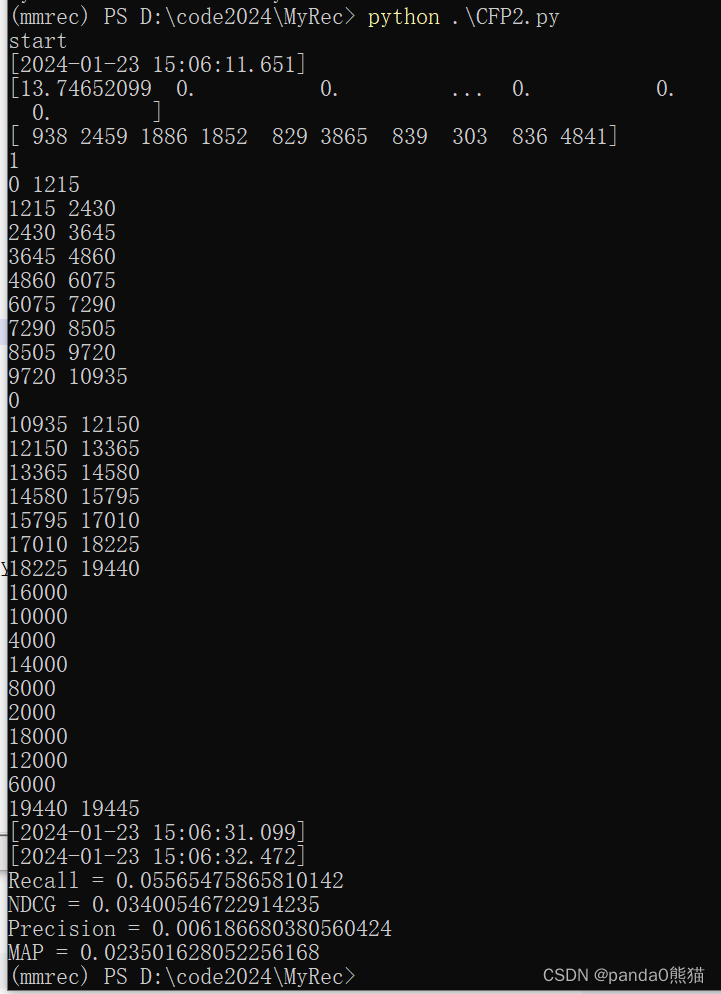
print("Recall =", recall)
print("NDCG =", ndcg)
print("Precision =", precision)
print("MAP =", map_value)
main()6.上面的np.savez是因为在花费了11个小时运行完代码后在评分环节可能崩溃,为了避免重新运行11个小时,第一时间保存结果。
后记:
这个代码在单线程第一次跑通时占用2.8g内存,11个小时。
后来4个线程,2.8*4+2.8+2=16,刚好让一台16g内存的电脑随时崩溃,4个子线程,1个主线程,2g系统占用。
后来换了一台电脑8个线程占用1个半小时,内存占用25g。
现在这版同时开16个线程,只需要20秒,
我去挑战更大的数据集了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LeetCode三数之和
- 代码随想录算法训练营第8天|字符串1 344.反转字符串 541. 反转字符串II 卡码网:54.替换数字 151.翻转字符串里的单词 卡码网:55.右旋转字符串
- dubbo的基础知识
- git在本地创建dev分支并和远程的dev分支关联起来
- 运行jar包文件cmd窗口中文乱码
- linux脚本中 #!/bin/sh、#!/bin/bash
- 金蝶Apusic应用服务器 loadTree JNDI注入漏洞
- ObjectArx调用cad内部命令
- c语言:链表
- 【笔记】Spring的循环依赖