【强化学习】QAC、A2C、A3C学习笔记
强化学习算法:QAC vs A2C vs A3C
引言
经典的REINFORCE算法为我们提供了一种直接优化策略的方式,它通过梯度上升方法来寻找最优策略。然而,REINFORCE算法也有其局限性,采样效率低、高方差、收敛性差、难以处理高维离散空间。
为了克服这些限制,研究者们引入了Actor-Critic框架,它结合了价值函数和策略梯度方法的优点(适配连续动作空间和随机策略),旨在提升学习效率和稳定性。
QAC(Quality Actor-Critic)
实现原理
QAC算法通过结合Actor-Critic架构的优势,实现了策略和价值函数的有效融合。在此框架中,Actor基于策略梯度法选择动作,而Critic组件评估这些动作的价值,以指导Actor的策略更新。
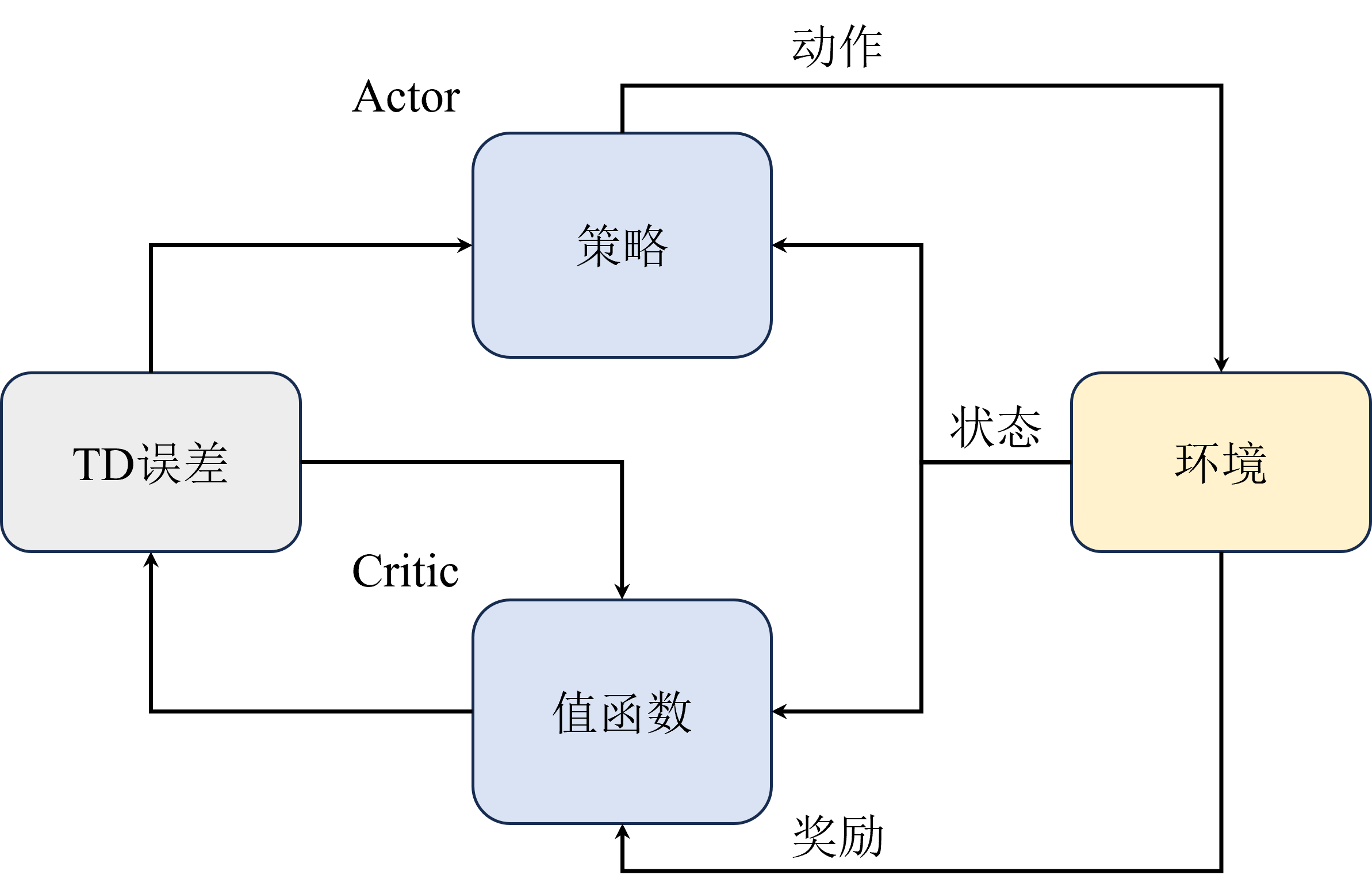
由图可知,在Actor-Critic算法中,TD Error用于更新Critic的价值函数,也用来指导Actor的策略梯度更新。简单来说,如果TD Error较大,意味着当前策略对于该状态-动作对的价值预测不准确,需要更大的调整。
优势与局限
QAC的主要优势在于其将策略探索与价值评估相结合,旨在提升决策质量与学习速度。然而,由于依赖样本来更新策略,它可能会面临高方差问题,尤其是在样本数量较少或者环境噪声较大的情况下。 这要求在实际应用中进行适当的调整和优化,以实现最佳性能。
A2C(Advantage Actor-Critic)
实现原理
A2C通过引入advantage函数 A π ( s t , a t ) A^\pi(s_t,a_t) Aπ(st?,at?),来指导策略更新。这个函数评估执行某个动作相比平均水平好多少,旨在减少方差并提高策略的学习效率。
优势与局限
A2C的同步框架减少了策略更新中的噪声,提升了学习稳定性。作为on-policy算法,它直接在策略路径上进行更新,保证了策略的一致性。
好像基本上能搜的资料都没有说这个方法的局限。
从经验上看,这个方法的样本利用率不高(会比DQN还要难收敛一点),而且对超参数敏感(这算是强化学习的通病了)。
A3C(Asynchronous Advantage Actor-Critic)
实现原理
A3C通过多个并行的Actor-Critic实例进行学习,这些实例独立探索并异步更新主策略。每个实例有自己的环境副本,降低了策略更新中的相关性。
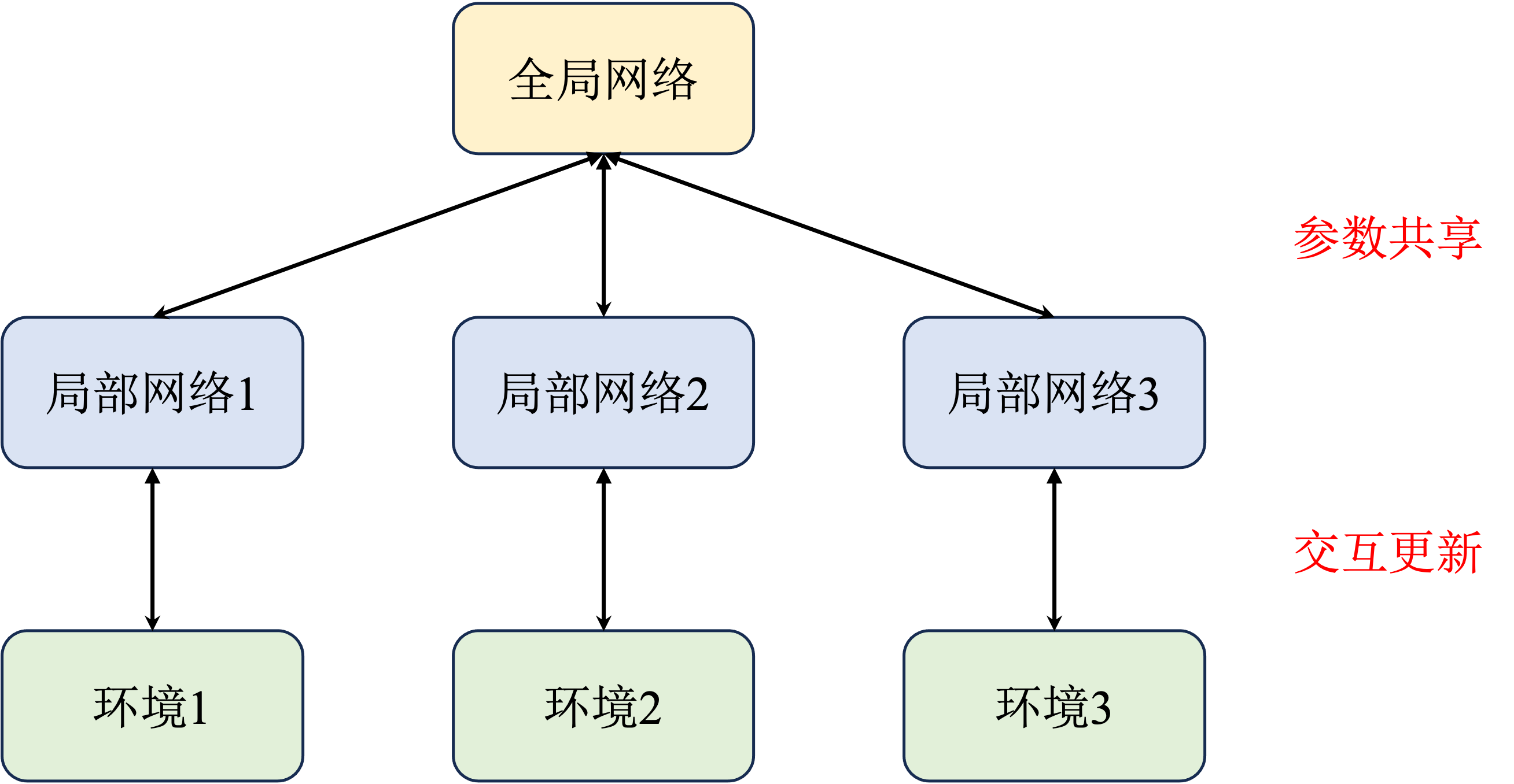
优势与局限
A3C的异步更新可以在多个环境副本上并行处理,加快学习速度,同时保持了策略的多样性。
但是这就要看你的计算资源够不够了🤣
小结(比较)
- QAC:一种基本的Actor-Critic方法,通过Q值来指导策略的更新。
- A2C:利用advantage function代替Q值,减少了方差并可能加速了学习过程。它通常在一个单一的环境中运行,这意味着它在更新策略时会等待每一步都完成。
- A3C:在A2C的基础上添加异步执行,允许多个agents并行探索和学习,这样不同的agent可以探索不同的策略空间,增加样本的多样性并加速学习过程。
A2C和A3C的核心区别在于A3C的异步更新机制,它允许并行处理多个环境实例,从而提高了算法的效率和鲁棒性。而QAC则为这些更先进的算法提供了基础框架。在实际应用中,选择哪种算法取决于计算资源、环境的复杂度以及所需的学习效率。
A2C提供了同步更新的稳定性,而A3C通过异步更新增加了学习效率。
两者都采用了advantage函数改善策略梯度,但A3C在多核心或多处理器系统上更具优势。
最后的问答
- 相比REINFORCE算法,为什么A2C可以提升速度?
A2C增加了Critic组件用于估计状态价值,这样Actor可以利用Critic提供的价值信息来更新策略,使得学习过程更加高效。
- A2C、A3C是on-policy的吗?
A2C算法是on-policy的,因为它根据当前策略生成的样本来更新这个策略,这意味着它评估和改进的是同一个策略。
A3C算法虽然采用了异步的更新机制,但它本质上仍然是on-policy的。尽管这些更新是异步发生的,但每个actor的策略更新都是基于其自身的经验,而这些经验是根据各自的当前策略产生的。
PS:后面有个最大熵的Soft Acotr Critic,这个就是off-policy。
参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 高颜值第三方网易云播放器R3PLAYX
- 【已解决】js定义对象属性是.如何访问
- 学校安全:这个门禁监控技术,速来码住!
- Java刷题错题笔记-day06-集合
- 人工智能_机器学习080_KMeans聚类算法原理和流程_KMeans损失函数_随机聚类中心_对异常值_初始值敏感---人工智能工作笔记0120
- 字体图标操作步骤
- MySQL是什么?它有什么功能?值不值得我们去学习?我们该如何去学习呢?
- 区间DP详解,思路分析,OJ详解
- 深入了解WPF控件:基础概念与用法(四)
- c语言错误总结