C#中常见集合类的底层原理与时间复杂度
目录
一、System.Collections中的接口
1、接口的继承关系
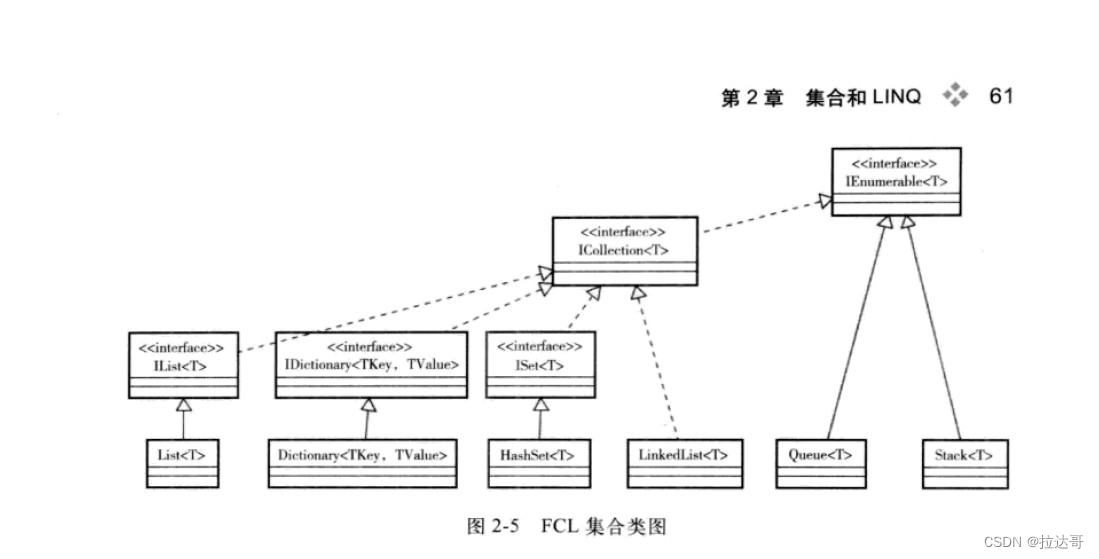
所有接口都有泛型和非泛型的版本,继承关系一致
2、接口的作用
| 接口 | 作用 |
|---|---|
| IEnumerable | 该接口定义了一个用于循环访问集合的枚举器。它是所有集合类的基本接口。需要实现IEnumerator GetEnumerator()方法,返回一个迭代器 |
| ICollection | 添加了用于操作集合的方法,如添加、删除、清空等。 |
| IList | 添加了对集合中元素进行索引访问和排序的方法。 |
| IDictionary | 与 IList 接口提供的功能类似,但集 合中的项是以键值对的形式存取的 |
| IEnumerator | 迭代器接口,需要实现MoveNext,Current,Reset,实现迭代器具体操作 |
| IDictionaryEnumerator | 迭代器接口,用来迭代IDictionary类型 |
一、线性表
对应C++的Array,Vector,List
1、Array(数组),ArrayList(动态数组),List<>(泛型集合)
Array:最基本的数组,长度固定,C#中有多维数组和交错数组。
ArrayList:在Array的基础上添加了自动扩容和常用增删操作,内部用object存储,存在装箱拆箱。
List<>:在ArrayList的基础上添加了泛型,避免了装箱拆箱,是最常用的集合。
底层原理:每次容量不够的时候,声明一个容量翻倍的新数组,并且把原来的内容复制到新数组中
Clear原理:将数组的Count设为0,然后将所有元素的属性设为默认值(值类型为0,引用类型为null),Capacity不变,也就是说栈内存保持不变,释放的堆内存需要等下次GC时回收。
List:
添加元素:Add:O(1)(内部记录了size,扩容时为O(n))、Insert:O(n)(内部用Copy方法实现)
删除元素:Remove、RemoveAt:O(n)(内部用Copy方法实现)
查找元素:Contains、IndexOf:O(n)(线性检索)
获取元素:索引访问:O(1)
排序:Sort:O(n log n) (快速排序情况下)
清空集合:Clear:O(n)
注意:Sort并不是简单的快速排序,它对普通的快速排序进行了优化,它还结合了插入排序和堆排序。系统会根据你的数据形式和数据量自动选择合适的排序方法,这并不是说它每次排序只选择一种方法,它是在一次完整排序中不同的情况选用不同方法,比如给一个数据量较大的数组排序,开始采用快速排序,分段递归,分段之后每一段的数据量达到一个较小值后它就不继续往下递归,而是选择插入排序,如果递归的太深,他会选择堆排序。
2、LinkedList<>(双向链表)
LinkedList<>:双向链表是一种数据结构,它与单向链表相似,但每个节点除了包含指向下一个节点的指针外,还包含指向前一个节点的指针。
底层原理:内部定义了LinkedListNode<>节点类,记录上一个节点和下一个节点位置
Clear原理:将所有节点的值设为默认值
LinkedList:
添加元素:AddLast、AddFirst:O(1)
删除元素:Remove:O(n)、
RemoveFirst、RemoveLast:O(1)
查找元素:Find、FindLast:O(n)
清空集合:Clear:O(n)
与单向链表的时间复杂度对比
单向链表(C#中无此类型数据结构类)
添加元素:O(n)
删除元素:O(n)
查找元素:O(n)
二、哈希表
对应C++的Map和Set
1、DIctionary<,>(字典),HashTable(哈希表)
HashTable:表示键值对的集合,其键值对根据键的哈希代码进行组织,哈希表的每个元素都是存储在DictionaryEntry对象中的键值对,存在装箱拆箱。
DIctionary<,>:哈希表的泛型版本
底层原理:内部定义了一个结构体Entry或bucket,用来存储value和key,并用数组存储结构体,哈希碰撞时使用拉链法解决
private struct bucket
{
public object key;
public object val;
public int hash_coll;
}
private struct Entry
{
public int hashCode;
public int next;
public TKey key;
public TValue value;
}
Dictionary<TKey, TValue>:
添加元素:Add:平均情况 O(1),最坏情况 O(n)(平均时通过size索引,扩容时最坏)
删除元素:Remove:平均情况 O(1),最坏情况 O(n)
查找元素:
ContainsKey:平均情况 O(1),最坏情况 O(n)(通过hash查找)
ContainsValue:O(n)(通过key查找)
获取元素:索引访问:平均情况 O(1),最坏情况 O(n)
清空集合:Clear:O(n)
注意:
为什么最坏情况下时间复杂度从O(1)变成O(n)?
这是因为Dictionary内部采用拉链法解决哈希碰撞,极端情况下所有元素存储在一个单向链表中,此时增删查获取元素都需要从头遍历链表,故时间复杂度为O(n)
查找键和值的时间复杂度解释
Containskey方法是O(1),原因是通过hash来查找元素而不是遍历元素。ContainsValue方法的时间复杂度是O(N),原因是内部通过遍历key来查找value,而不是通过hash来查找。Item[Key]属性根据key来检索value,其时间复杂度也是O(1)。==
2、HashSet<>(无序集),SortedSet<>(有序集)
HashSet<>:一种无序、不重复的集合。
底层原理:基于哈希表实现,内部维护一个泛型数组,数组的每个元素称为桶,细节与字典类似
HashSet<>:
添加元素:Add:平均情况 O(1),最坏情况 O(n)
删除元素:Remove:平均情况 O(1),最坏情况 O(n)
查找元素:Contains:平均情况 O(1),最坏情况 O(n)
清空集合:Clear:O(n)
注意:出现最坏情况的原理与DIctionary相同
SortedSet<>:一种有序、不重复的集合。
底层原理:基于红黑树实现
SortedSet<>
添加元素:Add:O(logn)
删除元素:Remove:O(logn)
查找元素:Contains:O(logn)
清空集合:Clear:O(n)
获取最大最小元素:Min,Max:O(1)
三、队列
1、Queue,Queue<>
Queue:一种表示对象的先进先出集合,只能从头部取出元素,从尾部添加元素,存在装箱拆箱
Queue<>:Queue的泛型版本
底层原理:动态循环数组。内部用_head和_tail两个指针来标记头和尾,移除元素时只需要移动移动头和尾指针,并将原位置标记为null
Queue:
添加元素:Enqueue:O(1)
删除元素:Dequeue:O(1)
获取元素:Peek:O(1)
查找元素:Contains:O(n)
清空集合:Clear:O(n)
与List对比,添加和删除元素时间复杂度降低为O(1)
List:
添加元素:Add、Insert:O(n)
删除元素:Remove、RemoveAt:O(n)
查找元素:Contains、IndexOf:O(n)
获取元素:索引访问:O(1)
排序:Sort:O(n log n)
清空集合:Clear:O(n)
四、栈
1、Stack,Stack<>
Stack:一种表示对象的后进先出集合,只能从栈顶取出元素,存在装箱拆箱
Stack<>:Stack的泛型版本
底层原理:内部用一个泛型数组存储元素,添加元素时直接从尾部添加,当容量不够时进行扩容,扩容方式与List相同
Stack<>:
添加元素:Push:O(1),进行扩容时为O(n)
删除元素:Pop:O(1)
查找元素:Contains:O(n)
清空集合:Clear:O(n)
五、总结
了解常用数据结构类的底层原理和时间复杂度有助于我们进行性能优化,C++的STL还提供优先队列,双向队列,单向链表等类,相较起来C#提供的集合类没有C++强大。注意:ChatGPT提供的时间复杂度分析有错误,它认为Clear操作只是将Cout设为0,所以得出O(1)的结论,实际上需要遍历一遍元素,将所有元素设为默认值,时间复杂度应该是O(n),切记不能盲目依赖ChatGPT。我以为只是人文方面的回答比较垃圾,没想到编程方面的也会出错,而且还是低级错误。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Java万花筒】通往高效通信的道路:揭秘Java网络库的奥秘
- 【c语言】飞机大战(1)
- 力扣labuladong一刷day42天图的遍历
- crmeb v5新增一个功能的完整示例记录
- 【2019】360Java工程师客观题总结
- 企业门户平台:八项必备功能助力业务升级
- 中仕公考:2024年上半年中小学教师资格考试(笔试)报名已开始
- PNG免抠素材库,免费下载,可商用~
- 厚积薄发11年,鸿蒙究竟有多可怕
- 文本翻译GUI程序,实现简单的英汉互译