基于YOLOv8的NEU-DET钢材表面缺陷检测任务,加入DCNv4和SPPF结合DCNv4提升检测精度
?💡💡💡本文主要内容:通过实战NEU-DET钢材表面缺陷检测任务,验证DCNv4和SPPF结合DCNv4的可行性
实验结果表明:原始YOLOv8n map0.5为?0.768,DCNv4为0.774?,SPPF结合DCNv4为0.775
1.NEU-DET钢材表面缺陷检测任务
由中国东北大学(NEU)发布的表面缺陷数据库,收集了热轧钢带的六种典型表面缺陷,即轧制氧化皮(RS),斑块(Pa),开裂(Cr),点蚀表面( PS),内含物(In)和划痕(Sc)。该数据库包括1,800个灰度图像:六种不同类型的典型表面缺陷,每一类缺陷包含300个样本。对于缺陷检测任务,数据集提供了注释,指示每个图像中缺陷的类别和位置。

数据集大小1800,按照train、val、test随机划分为0.7:0.2:0.1
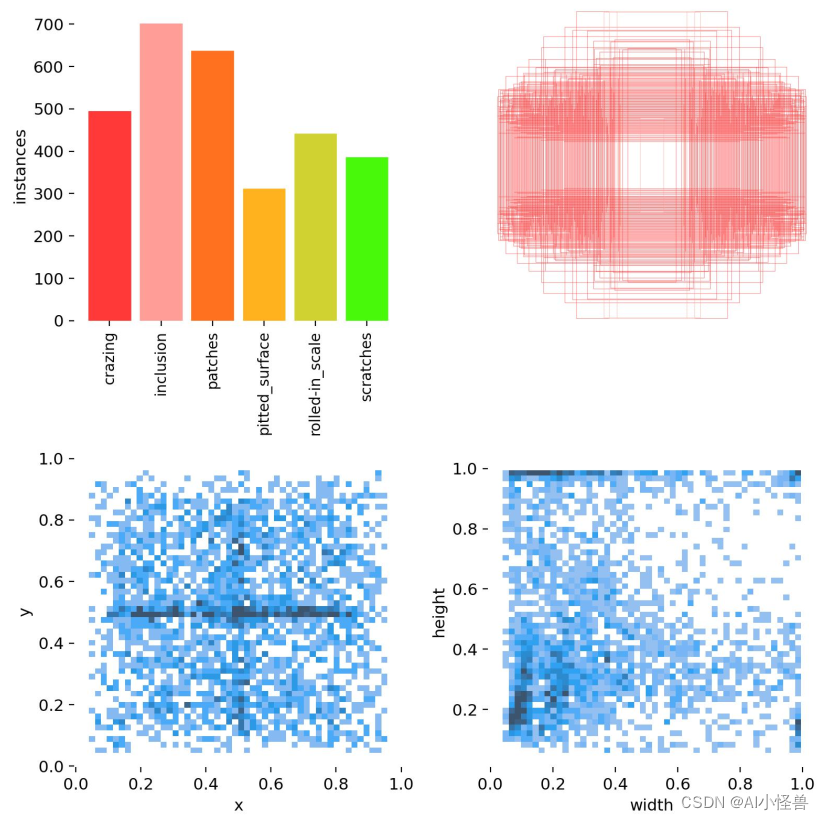
 ?
?

2.DCNv4原理介绍

论文:?https://arxiv.org/pdf/2401.06197.pdf
摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。
图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。

????????为了克服这些挑战,我们提出了可变形卷积v4 (DCNv4),这是一种创新的进步,用于优化稀疏DCN算子的实际效率。DCNv4具有更快的实现速度和改进的操作符设计,以增强其性能,我们将详细说明如下:
????????首先,我们对现有实现进行指令级内核分析,发现DCNv3已经是轻量级的。计算成本不到1%,而内存访问成本为99%。这促使我们重新审视运算符实现,并发现DCN转发过程中的许多内存访问是冗余的,因此可以进行优化,从而实现更快的DCNv4实现。
????????其次,从卷积的无界权值范围中得到启发,我们发现在DCNv3中,密集关注下的标准操作——空间聚合中的softmax归一化是不必要的,因为它不要求算子对每个位置都有专用的聚合窗口。直观地说,softmax将有界的0 ~ 1值范围放在权重上,并将限制聚合权重的表达能力。这一见解使我们消除了DCNv4中的softmax,增强了其动态特性并提高了其性能。
因此,DCNv4不仅收敛速度明显快于DCNv3,而且正向速度提高了3倍以上。这一改进使DCNv4能够充分利用其稀疏特性,成为最快的通用核心视觉算子之一。
????????我们进一步将InternImage中的DCNv3替换为DCNv4,创建FlashInternImage。值得注意的是,与InternImage相比,FlashInternImage在没有任何额外修改的情况下实现了50 ~ 80%的速度提升。这一增强定位FlashInternImage作为最快的现代视觉骨干网络之一,同时保持卓越的性能。在DCNv4的帮助下,FlashInternImage显著提高了ImageNet分类[10]和迁移学习设置的收敛速度,并进一步提高了下游任务的性能。
图2。(a)注意力(Attention)和(b) DCNv3使用有限的(范围从0 ~ 1)动态权值来聚合空间特征,而注意力的窗口(采样点集)是相同的,DCNv3为每个位置使用专用的窗口。(c)卷积对于聚合权值具有更灵活的无界值范围,并为每个位置使用专用滑动窗口,但窗口形状和聚合权值是与输入无关的。(d) DCNv4结合两者的优点,采用自适应聚合窗口和无界值范围的动态聚合权值。

图3。说明我们的优化。在DCNv4中,我们使用一个线程来处理同一组中的多个通道,这些通道共享采样偏移量和聚合权重。可以减少内存读取和双线性插值系数计算等工作负载,并且可以合并多个内存访问指令。
 ?表2。具有各种下采样率的标准输入形状的运算级基准。当实现可用时报告FP32/FP16结果。在不同的输入分辨率下,我们的DCNv4可以超越所有其他常用运算符。
?表2。具有各种下采样率的标准输入形状的运算级基准。当实现可用时报告FP32/FP16结果。在不同的输入分辨率下,我们的DCNv4可以超越所有其他常用运算符。
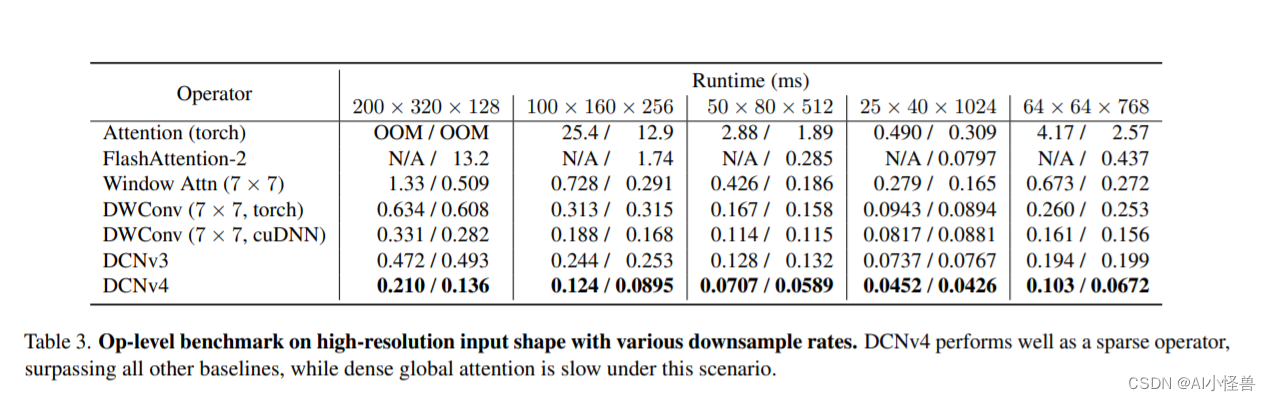
 表3。具有各种下采样率的高分辨率输入形状的运算级基准。DCNv4作为稀疏算子表现良好,优于所有其他基线,而密集的全局关注在这种情况下速度较慢。
表3。具有各种下采样率的高分辨率输入形状的运算级基准。DCNv4作为稀疏算子表现良好,优于所有其他基线,而密集的全局关注在这种情况下速度较慢。
 ?表4。ImageNet-1K上的图像分类性能。我们展示了FlashInternImage w/ DCNv4和它的InternImage对应版本之间的相对加速。DCNv4显着提高了速度,同时显示了最先进的性能。
?表4。ImageNet-1K上的图像分类性能。我们展示了FlashInternImage w/ DCNv4和它的InternImage对应版本之间的相对加速。DCNv4显着提高了速度,同时显示了最先进的性能。

3.DCNv4加入YOLOv8
3.1?yolov8_DCNV4.yaml
详细原理见:YOLOv8全网首发:DCNv4更快收敛、更高速度、更高性能,效果秒杀DCNv3、DCNv2等 ,助力检测-CSDN博客
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [15, 1, DCNV4, [256,3, 1]]
- [18, 1, DCNV4, [512,3, 1]]
- [21, 1, DCNV4, [1024,3, 1]]
- [[22, 23, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.2?yolov8-DCNv4_SPPF.yaml
YOLOv8全网首发:新一代高效可形变卷积DCNv4如何做二次创新?高效结合SPPF-CSDN博客
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, DCNv4_SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.结果分析
原始YOLOv8
YOLOv8 summary (fused): 168 layers, 3006818 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:03<00:00, 3.19it/s]
all 324 732 0.745 0.706 0.768 0.433
crazing 324 121 0.52 0.296 0.406 0.16
inclusion 324 175 0.731 0.806 0.819 0.475
patches 324 147 0.826 0.81 0.907 0.592
pitted_surface 324 78 0.822 0.718 0.794 0.472
rolled-in_scale 324 107 0.741 0.71 0.766 0.361
scratches 324 104 0.827 0.894 0.917 0.539
4.1 加入DCNv4性能分析
?
YOLOv8_DCNV4 summary (fused): 174 layers, 3093282 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:03<00:00, 2.87it/s]
all 324 732 0.703 0.744 0.774 0.442
crazing 324 121 0.548 0.397 0.446 0.17
inclusion 324 175 0.695 0.834 0.83 0.454
patches 324 147 0.862 0.847 0.929 0.62
pitted_surface 324 78 0.813 0.705 0.803 0.503
rolled-in_scale 324 107 0.571 0.71 0.695 0.34
scratches 324 104 0.73 0.971 0.94 0.563 4.2 SPPF结合DCNv4
4.2 SPPF结合DCNv4
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 环信服务端下载消息文件---菜鸟教程
- 在统信UOS Linux下用opencv-python捕获摄像头输入保存到视频文件
- 掌握C++11标准库(STL):理解STL的核心概念
- Vue创建项目配置情况
- python:for循环 实现FizzBuzz
- 如何安装docker
- 50天精通Golang(第18天)
- discard long time none received connection
- Python语法进阶——函数
- js将数组对象中某个值相同的对象合并成一个新对象