【大数据实战】亿级数据量: 检索一个元素是否在一个集合中 [bloom过滤器及其应用]
目录
亿级数据量: 检索一个元素是否在一个集合中 [bloom过滤器]
问题描述
在实际项目中,我们经常会遇到判断单个元素是否在一个集合中的情况,比如:网页URL去重、垃圾邮件识别、大集合中重复元素、海量数据去重和缓存穿透(本来要查数据库,但如果我们可以提前感知这个元素是否在数据库中,就可以减少数据库的压力)等问题。在数据量很小(几千或者几万)的时候,利用一些常见的数据结构,比如Set, HashSet等,可以比较轻易的判断,但是当数据规模达到亿级别的情况下,想要在s甚至ms级别返回结果的话,就比较捉襟见肘了。此时,bloom过滤器这个利器就登场了,bloom过滤器主要解决的就是 海量数据的存在性问题
bloom过滤器简介
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
传统方法
当你往简单数组或列表中插入新数据时,将不会根据插入项的值来确定该插入项的索引值。这意味着新插入项的索引值与数据值之间没有直接关系。这样的话,当你需要在数组或列表中搜索相应值的时候,你必须遍历已有的集合。若集合中存在大量的数据,就会影响数据查找的效率。(缺点:慢&&存储大)
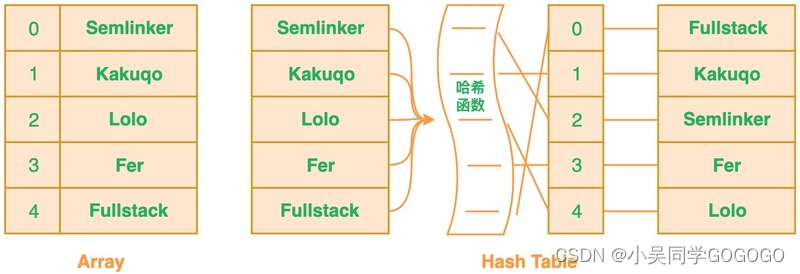
哈希表
针对这个问题,你可以考虑使用哈希表。利用哈希表你可以通过对 “值” 进行哈希处理来获得该值对应的键或索引值,然后把该值存放到列表中对应的索引位置。这意味着索引值是由插入项的值所确定的,当你需要判断列表中是否存在该值时,只需要对值进行哈希处理并在相应的索引位置进行搜索即可,这时的搜索速度是非常快的。(缺点:存储大)
bloom的思路
bloom过滤器可以实现的功能:
- 某个值可能在集合中
- 某个值绝对不在集合中
也就是说:bloom过滤器来判断某个值在某个大集合中,是有一定概率的,表示存在一定的误判率。那为什么会存在误判呢?这是由它的原理决定的。
内部原理
-
本质结构
长度为m的位向量或位列表(仅包含0或者1值的列表)组成。最初的情况下所有值都为0:

-
数据映射
当我们将一个数据加入到bloom过滤器中的时候,会提供k个不同的哈希函数(没错,这里会用到哈希函数,但是注意不止一个,是有k个不同的哈希函数)
在前面所提到的哈希表中,我们使用的是单个哈希函数,因此只能输出单个索引值。而对于布隆过滤器来说,我们将使用多个哈希函数,这将会产生多个索引值。
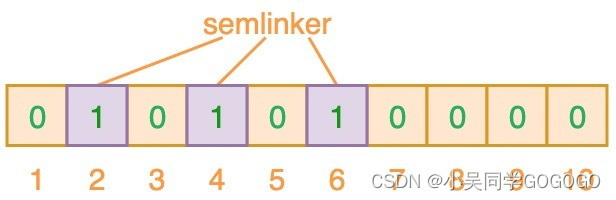
1)如上图所示,当输入 “semlinker” 时,预设的 3 个哈希函数将输出 2、4、6,我们把相应位置 1。
2)假设另一个输入 ”kakuqo“,哈希函数输出 3、4 和 7。(你可能已经注意到,索引位 4 已经被先前的 “semlinker” 标记了。此时,我们已经使用 “semlinker” 和 ”kakuqo“ 两个输入值,填充了位向量。)
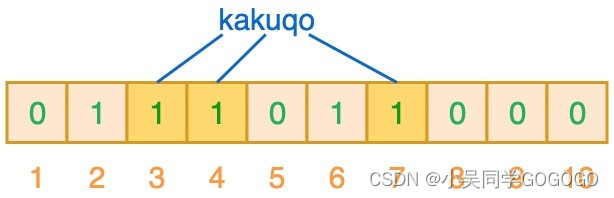
上图变成:
-
数据检索
根据上图所示,当我们检索kakuqo的时候,通过三个hash函数,会映射到3,4,7三个位置,结果可以看到都是1,表示存在对应的值。
当我们检索fullstack的时候,假如输出的三个索引为2,3,7 可以看到其实也命中了。但是:我们并没有向其中插入fullstack数据,所以这里存在误判了。
产生的原因是由于哈希碰撞导致的巧合而将不同的元素存储在相同的比特位上。 -
误判率 FPP
上面误判的概率其实可以有公式进行计算的:
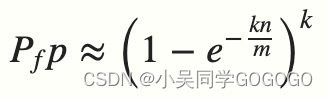
n 是已经添加元素的数量;
k 哈希的次数;
m 布隆过滤器的长度(如比特数组的大小);
注意:当bloom过滤器满的时候,每一次查询都会返回true;所以m的选择取决于想要放入的数据量,并且m要远远大于n。
布隆过滤器的长度 m 可以根据给定的误判率(FFP)的和期望添加的元素个数 n 的通过如下公式计算:
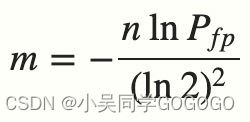
-
结论
当我们搜索一个值的时候,若该值经过 K 个哈希函数运算后的任何一个索引位为 ”0“,那么该值肯定不在集合中。但如果所有哈希索引值均为 ”1“,则只能说该搜索的值可能存在集合中。
bloom过滤器为什么快?
使用类似hashMap的原理,使得它的插入和查询速度是非常快的,时间复杂度是O(K),可以联想一下HashMap的过程。
bloom过滤器更加节省空间!
Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。

优缺点
- 优点:性能好 && 高效&&安全性好,本身不存储任何原始数据,只有二进制数据
- 缺点:一定的错误识别率 && 删除难度大
实际应用
java
在Java中,你可以使用第三方库来实现布隆过滤器,比如Google的Guava库或Apache的Commons库。下面我将介绍如何在Java中使用Guava库来应用布隆过滤器。
首先,你需要在你的Java项目中添加Guava库的依赖。你可以在你的构建工具(如Maven或Gradle)的配置文件中添加以下依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1-jre</version>
</dependency>
一旦你添加了依赖,你就可以在你的Java代码中使用Guava的布隆过滤器了。下面是一个简单的示例:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {
public static void main(String[] args) {
// 创建一个布隆过滤器,设置期望插入的元素个数和误判率
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.unencodedCharsFunnel(), 1000, 0.01);
// 向布隆过滤器中插入元素
bloomFilter.put("apple");
bloomFilter.put("banana");
bloomFilter.put("orange");
// 判断元素是否存在于布隆过滤器中
System.out.println(bloomFilter.mightContain("apple")); // true
System.out.println(bloomFilter.mightContain("pear")); // false
System.out.println(bloomFilter.mightContain("banana")); // true
}
}
在上面的示例中,我们首先创建了一个布隆过滤器,设置了期望插入的元素个数为1000,误判率为0.01。然后我们向布隆过滤器中插入了几个元素,最后使用mightContain方法来判断元素是否存在于布隆过滤器中。
go
在Go语言中应用布隆过滤器相对简单,并且Go标准库中提供了github.com/willf/bloom包,可以方便地实现布隆过滤器功能。下面是一个在Go中使用布隆过滤器的示例:
首先,你需要安装github.com/willf/bloom包,可以使用以下命令进行安装:
go get github.com/willf/bloom
安装完成后,你可以在你的Go代码中导入该包并使用布隆过滤器。下面是一个简单的示例:
package main
import (
"fmt"
"github.com/willf/bloom"
)
func main() {
// 创建一个布隆过滤器,设置期望插入的元素个数和误判率
bf := bloom.New(1000, 0.01)
// 向布隆过滤器中插入元素
bf.Add([]byte("apple"))
bf.Add([]byte("banana"))
bf.Add([]byte("orange"))
// 判断元素是否存在于布隆过滤器中
fmt.Println(bf.Test([]byte("apple"))) // true
fmt.Println(bf.Test([]byte("pear"))) // false
fmt.Println(bf.Test([]byte("banana"))) // true
}
在上面的示例中,我们首先使用bloom.New函数创建了一个布隆过滤器,设置了期望插入的元素个数为1000,误判率为0.01。然后我们使用Add方法向布隆过滤器中插入了几个元素,最后使用Test方法来判断元素是否存在于布隆过滤器中。
python
在Python中,你可以使用pybloom_live或redisbloom等第三方库来实现布隆过滤器。下面我将演示如何在Python中使用pybloom_live库来应用布隆过滤器。
首先,你需要安装pybloom_live库。你可以使用以下命令通过pip来安装:
pip install pybloom_live
安装完成后,你可以在Python代码中导入pybloom_live库并使用布隆过滤器。下面是一个简单的示例:
from pybloom_live import BloomFilter
# 创建一个布隆过滤器,设置期望插入的元素个数和误判率
bf = BloomFilter(capacity=1000, error_rate=0.01)
# 向布隆过滤器中插入元素
bf.add("apple")
bf.add("banana")
bf.add("orange")
# 判断元素是否存在于布隆过滤器中
print("apple" in bf) # True
print("pear" in bf) # False
print("banana" in bf) # True
在上面的示例中,我们首先使用BloomFilter类创建了一个布隆过滤器,设置了期望插入的元素个数为1000,误判率为0.01。然后我们使用add方法向布隆过滤器中插入了几个元素,最后使用in关键字来判断元素是否存在于布隆过滤器中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一文读懂SoBit 跨链桥教程
- shell编程-xargs命令详解(超详细)
- 香港云服务器:如何计算其正常运行时间
- 运动耳机平价推荐哪款、性价比高的运动耳机学生党
- 如何使用Python的交互控制台
- el-cascader 获取label、value值
- MyBatis-基本概念
- 重新定义出行,PIX移动空间-Robobus2.0正式发布
- 算法设计与分析2023秋-头歌实验-实验五 分治法
- uview1使用form表单设置required必填项,并更改星花的颜色