【深度视觉】第五章:卷积网络的重要概念及花式卷积
七、卷积网络的重要概念及花式卷积操作
本部分是重点讲一些卷积层的特点、相关概念、以及一些花式的卷积操作方法。属于查漏补缺,或者是点对点的补充吧。
首先再明确一些概念和操作流程:
- 任何神经网络中,一个神经元都只能存储一个数字。
- 卷积神经网络的神经元就是特征图上的每个数字,就是特征图上几乘几矩阵里的每个数字,这些数字我们也称“像素”, 一个数字就是一个神经元。下一个卷积层生成的特征图feature map上的每个神经元都不是和上层神经元全连接的,都只是和它对应的感受野里面的神经元连接的。
- 在计算机视觉中说“降维”,往往是减少一张图上的像素量。
- 卷积核尺寸一般用3*3
- 类似DNN,CNN每层后面都跟一个激活层,而且我们一般不把激活层列出来,一般都是在那个层里的神经元里面直接处理了。CNN也是经过卷积操作后,生成的特征图的每个神经元要再经过激活函数变换。只是因为激活层是没有要训练的参数,所以一般我们不列出这个层。
- CNN的输入和输出是特征图,而且层与层之间的传递是通过扫描核扫描的,所以输出的特征图的尺寸是随着网络的加深是逐渐减小的。所以如果输入特征图的尺寸和扫描核的尺寸以及步长、padding这些搭配不好的话,就会导致网络深度受到限制,网络深度不深就说明提取的特征不够充分。
- 池化核的移动也有步长stride,但默认步长就等于它的核尺寸,这样可以保证它在扫描特征图时不出现重叠。当然,如果需要,我们也可以设置参数令池化核的移动步长不等于核尺寸,这叫“Overlapping Pooling”,重叠池化,但我们一般不会重叠池化,原因我们前面说过很多遍,因为池化就相当于统计,你重复统计就是瞎统计,没有意义,还捣乱。
- 池化核一般都设置为2X2或3X3。使用(2,2)结构的池化层会将featrue map的行列都减半,将整个feature map的像素数减少3/4,因此它是非常有效的降维方法。
1、局部连接、参数共享
卷积神经网络的两大核心思想:局部连接(Local Connectivity)、参数共享(Parameter Sharing),两者共同的一个关键作用就是减少模型的参数量,使运算更加简洁高效,能够运行在超大规模数据集上。
下图展示了全连接网络中一个神经元的参数量。不进行局部连接,每个神经元和每一个输入像素连接,参数量动辄千万级别,网络很难训练: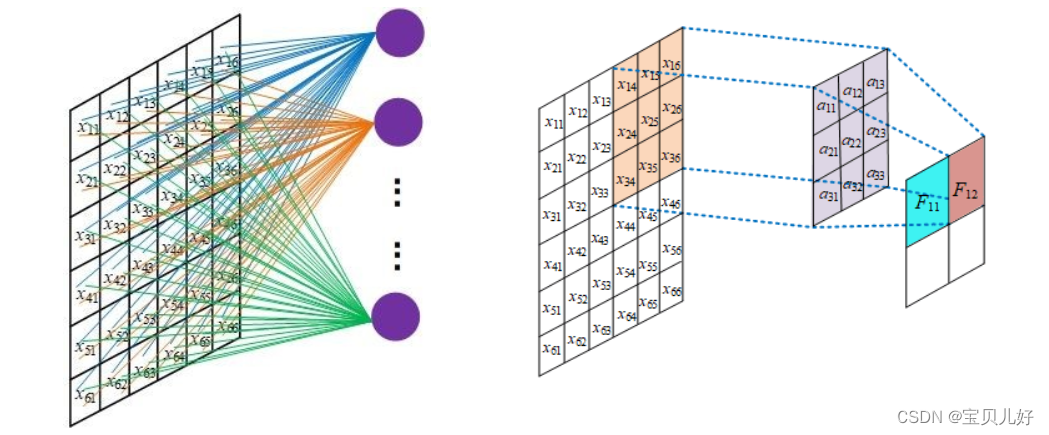
这种就是DNN的运行机制,这种情况参数巨量,无法训练。所以CNN中的卷积操作就是局部连接,避免了全连接中参数过多而造成无法计算的情况。 同时,上一个卷积层的数据和下一个卷积层的数据之间不是像DNN那样的全链接,而是上一层的部分信息和下一层的部分信息相关,因为下一层的信息是通过卷积核和上一层对应的感受野做点积传递到下一层的一个点上的。或者说,就是下一层的特征图上的某个数字只和它上一层特征图的对应位置的感受野范围内的数字相关,和上一层特征图其他位置的数值无关,所以是局部连接。也所以感受野这个概念也是深度视觉中的一个重要概念,后面我们会单独讲这个概念,但你得知道是因为局部连接才有感受野这个概念的。
参数共享的意思就是:我们做卷积操作生成一张feature map时,是前面所有通道图都使用同一组卷积核组卷积而来的。不管你的图像是几乘几的尺寸、不管你有多少张这样的图像,这些张图像在用卷积核进行扫描提取特征的时候,参数都是卷积核尺寸里的几个参数乘以图像的张数,这么多个参数。或者说,就是一张图像中的所有数据(神经元)都共同用一个相同的卷积核进行扫描,所以是参数共享,而且也使参数量骤减。
这两个概念很容易理解,尤其是对卷积操作非常熟悉的同学,就没有太多需要解释的。主要是你知道后,你再读其他人写的东西时,你就很容易知道他在说什么,很多概念大家都没有一个统一的叫法,有的人还叫稀疏交互sparse interaction,这些都是一个东西。
2、感受野 receptive field
在计算机视觉任务中,感受野这个概念非常重要,本部分详细聊聊感受野。
感受野:CNN中某一feature对应(看)着的输入空间中的区域(即:输入图片的像素区域,这些像素参与了该feature的计算)被称为该feature的感受野。 这是我到网上找的一个概念,读着有点蹩脚,其实通俗理解就是:原图->卷积->卷积->池化等一番操作下来->生成了一张特征图。现在问生成的特征图上的某一个像素值,它是由原图中哪些像素点计算而来的?原图中参与计算的那些像素点组成的区域就是感受野。
如果没有特别说明,我们说的感受野都指的是一直映射到原始图像上的感受野。
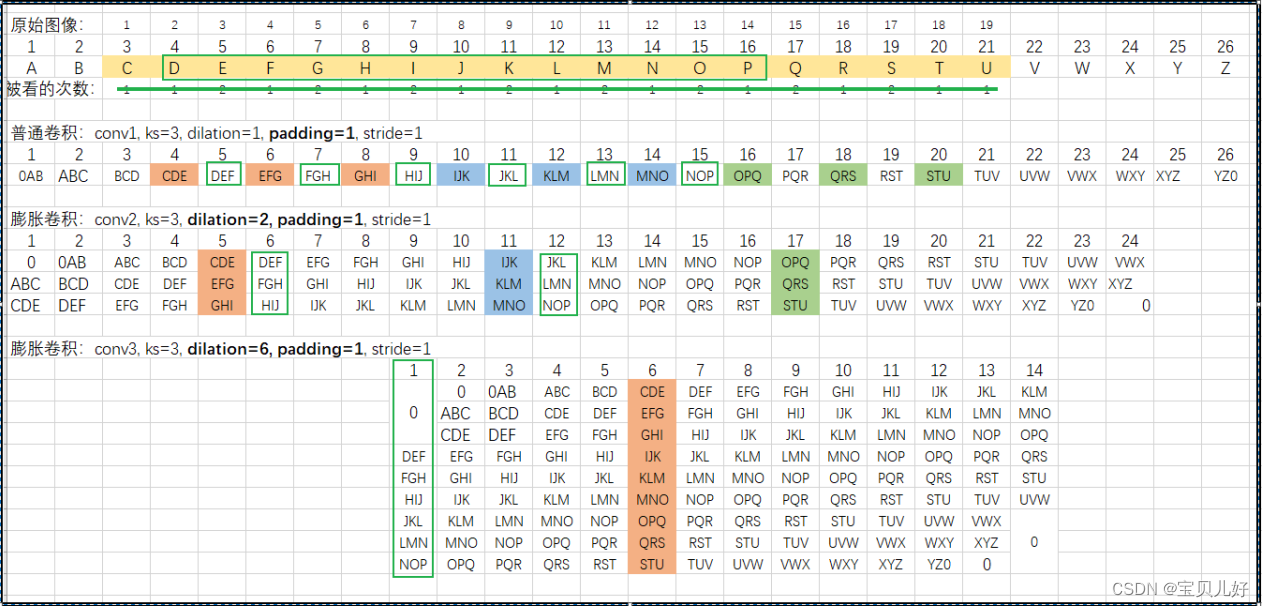
下图中假设原始图像是26x26的尺寸,这里画的是一个截面图,你把它想象成一个面。
第一个卷积层的卷积操作是:3x3卷积核、padding=1、步长=1进行卷积。如此操作三个卷积层,然后进行maxpool,maxpool是2x2的卷积核,步长为2的非重叠池化,最后再是一次卷积操作。
下图是展示上面4次卷积+1次maxpool整个过程中,最后一张特征图的像素点对应到原图中的感受野范围。其中绿色背景的就是这个网络生成的特征图的感受野:
从上图可见:
(1)特征图第8个像素点是原图第10-21个像素点计算而来,而且是越靠中间的像素点参数计算的次数越多,越靠两边的像素点参数计算的次数越少。
(2)也就是说,上图这个网络生成的特征图的感受野就是12。就是特征图每个像素看到的是原图中的12个像素点。局部链接、稀疏交互嘛。
(3)上图中还画了粉色背景和蓝色背景的,分别表示第一个生成的feature map的第一个像素和最后一个像素对应的感受野。单独把这两个点拿出来是因为这两个点的感受野虽然也是12,但它们两个像素的12个感受野中有5个点是无中生有的点,就是padding和池化出来的点。由此也可以推断出最后生成的特征图它其实看到的是有一层厚厚黑边的原图!
随着网络深度的加深,feature map上的神经元对应的感受野会越来越大,这意味着feature map神经元上携带的原始数据的信息也越来越多。由于卷积网络是稀疏交互的,所以在被输入到FC层之前的神经元的感受野越大越好,因为越大表示携带更大范围内的信息。理论研究也表明,一个表现优异的模型在FC层前的感受野一定是非常大的,巨大的感受野是模型表现好的必要条件。
我们通常认为,较大的感受野意味着较好的效果,但稍微增加一些感受野的尺寸,并不能对整个模型的分类效果带来巨大的改变。但是对于像素级别的密集预测任务,就是像素级别的预测任务,就是需要给原始图像中的每个像素点进行分类,比如语义分割任务、语音处理中的立体声和光流估计任务等,FC层之前的感受野的大小至关重要。就是进入FC层前的每个神经元的感受野至少都是需要和原始图像一样大的区域才行,因为它至少也要携带和原始图像一样大的信息,才能判断它自己应该是属于哪个类别。
- 感受野尺寸的计算
如果我们输入图像的尺寸是正方形、卷积核的尺寸也是正方形,对于第i个卷积层或者池化层输出的特征图上,任意一个神经元的感受野是:
![]()
因为公式不好敲,我就用文字描述了,如果想看公式的同学自行百度一下,到处都是。
可见,感受野的大小只与卷积核的大小、各层的步长有关,和padding无关。
后面我们讲卷积的变体操作——膨胀卷积时,其感受野的计算基础也是这个公式。
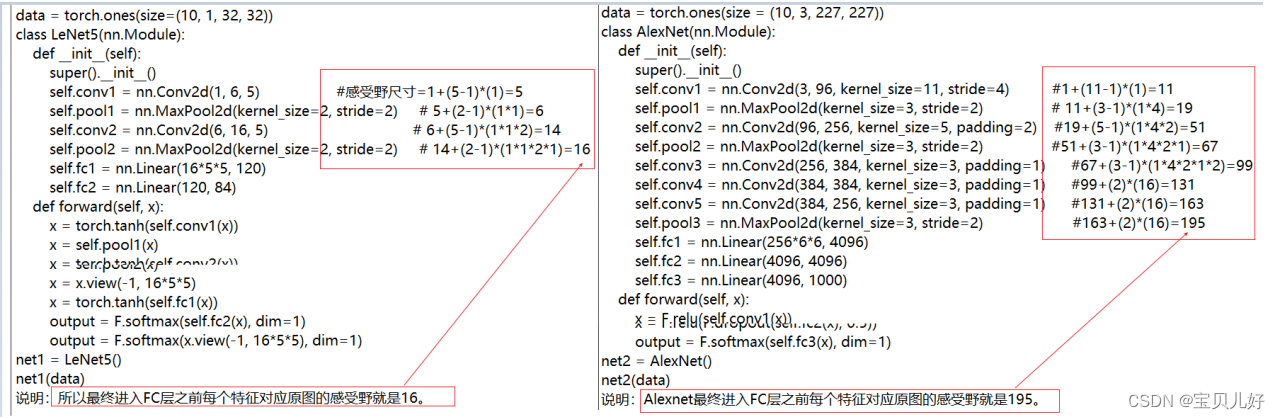
- 下图是根据公式手动计算Lenet和Alexnet的感受野:
- 增大有效感受野的具体方法:
上面我们说了感受野非常重要、感受野越大越好,那到底还有哪些具体措施来放大感受野呢?
一是,加深卷积网络的深度。理论上来说,每增加一个卷积层,感受野的宽和高就会按照卷积核的尺寸-1 的线性增加。
二是,池化层或者是其他快速消减特征图尺寸的技术。
三是,使用更加花式的卷积操作,比如膨胀卷积dilated convolution、残差连接等等。
方法1和2比较好把握,方法3就非常复杂了,在你使用前你首先要非常清楚这些花式操作的各个细节和特点才能游刃有余得使用。所以针对方法3我后面会专门写几个小标题专门讨论。
3、卷积的花式操作:膨胀卷积
膨胀卷积是卷积花式操作的基础,就是最基本的变体,所以这部分也是基础。这部分就和前面的感受野联系得非常紧密,所以感受野的基本知识点你要先吃透,这部分你才能继续往下推进。
(1)什么是膨胀卷积
膨胀卷积又叫空洞卷积,是在论文2016ICLR《Multi-scale Context Aggregation by Dilated Convolutions》中提出的。与标准的卷积核不同,膨胀卷积在kernel中增加了一些空洞,从而可以扩大模型的感受野。


pytorch中的conv2d卷积层里面就有一个参数:dilation。当dilation=1时,就是普通的卷积操作,就是上图左图中的卷积操作。当dilation=2时就是上图右图的卷积操作,就是隔一个点相乘相加。当dilation=3时,就是隔两个点进行相乘相加。 ? ?
(2)膨胀卷积的输出结果尺寸计算:
膨胀卷积是可以影响我们的输出结果的。不仅影响输出的特征矩阵中的数值,而且影响输出矩阵的尺寸:
当原始图像是9*9,卷积核是3*3,padding=0, stride=1, dilation=1时,输出的特征图是7*7
当原始图像是9*9,卷积核是3*3,padding=0, stride=1, dilation=2时,输出的特征图是5*5
当原始图像是9*9,卷积核是3*3,padding=0, stride=1, dilation=3时,输出的特征图是3*3
...
(3)膨胀卷积是如何增大感受野的?
讲感受野的时候,给大家展示过普通卷积层和池化层生成的feature map对应原图的感受野,也给出了感受野的计算公式。现在我们看看膨胀卷积是如何比普通卷积增大感受野的: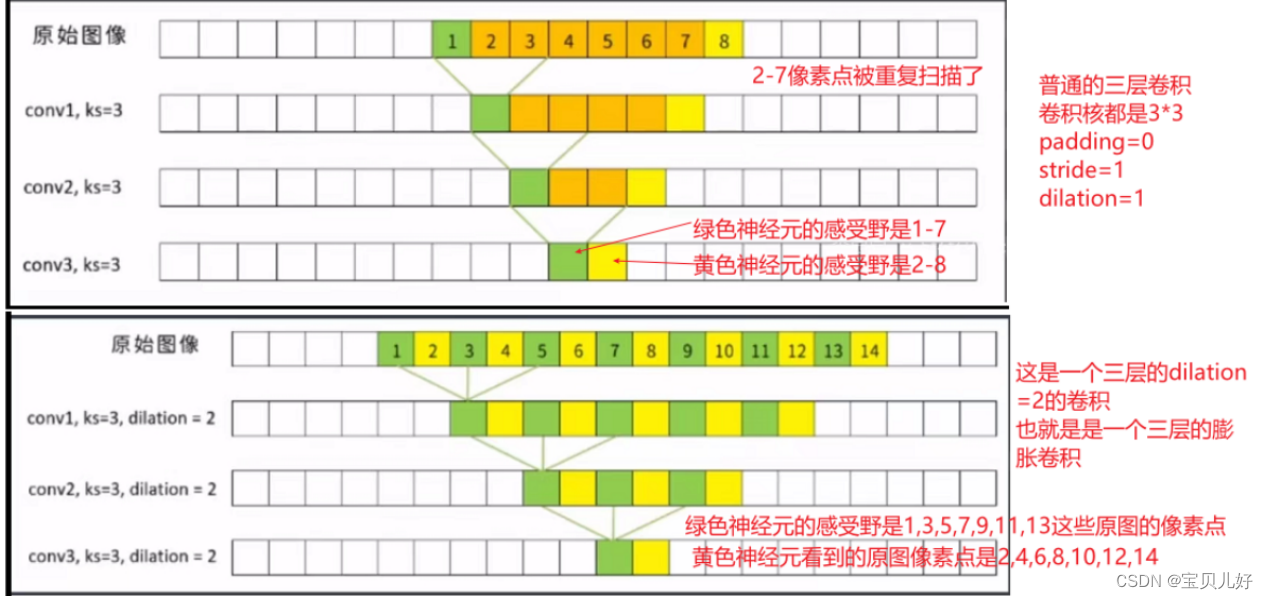
上图表明:同样都是一个三层的卷积网络,最终生成的特征图的每个神经元对应的原图感受野也都是7,但是你使用普通卷积层,感受野是从1-8,就是第一个神经元的感受野是1-7,第二个神经元的感受野是2-8,所以两个相邻的神经元的感受野是从1-8个像素。但是如果你使用的是膨胀卷积,两个相邻的神经元的感受野范围就变成了1-14!第一个绿色神经元的感受野是1,3,5,7,9,11,13,第二个黄色神经元的感受野是2,4,6,8,10,12,14。就是每个神经元对应的感受野被拉伸了,就是单个神经元对应的感受野出现了空洞!但是如果相邻神经元能够完美补充上这些空洞,那这个两个神经元的感受野就比上图的感受野要大得多。所以我们经常利用膨胀卷积的这个性质,把膨胀卷积和普通卷积串联起来使用,来增大特征图的感受野:
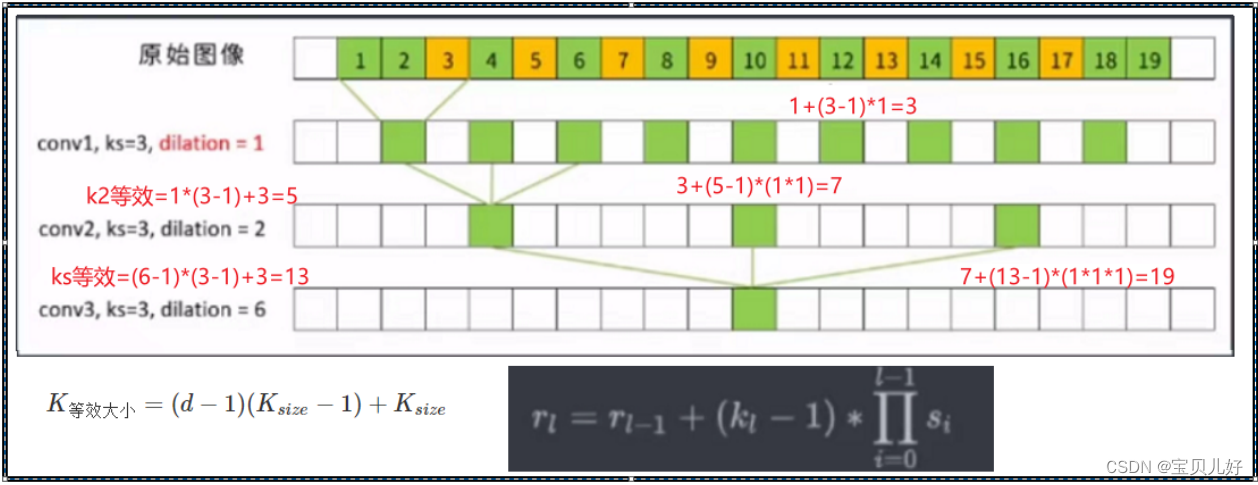
解读1:上图就是一个普通卷积串联一个膨胀2的膨胀卷积再串联一个膨胀6的膨胀卷积,我们可以看到最后生成的特征图的神经元的感受野被放大到19!而且这个19个像素中还没有空洞,而且黄色像素还是被看过2次的。
如果我们再结合池化层进行使用,那膨胀卷积放大感受野的性质会更加明显。正是膨胀卷积的这个优秀品质,膨胀卷积在语义分割等任务中有非常优秀的表现。当然它也有缺点,就是你得巧妙设计你的核尺寸、卷积层、膨胀尺寸、步长、padding等的巧妙搭配,使不出现空洞,因为出现空洞就意味着信息损失嘛,或者信息没有捕捉到嘛。也所以一般认为膨胀卷积不太适合小物体得分隔,更适合大物体的分隔。
解读2:上图的感受野计算我已经用红色字体写出来了,用到的公式也贴在图的下方。就是如果你有膨胀操作,那你的卷积核虽然还是3*3,此时你计算感受野的时候,你得把卷积核通过左边的公式转化为等价的卷积核,然后再用右边的公式计算感受野的尺寸。意思就是:比如上图第二层卷积层是个膨胀=2的膨胀卷积,那你得先把它的卷积核转化为同样感受野的普通卷积层的卷积核大小,就是5*5的等效核,然后再带入右边公式计算感受野,就是7。同理,上图第三层卷积是dilation=6的膨胀卷积,那和它等尺寸感受野的普通卷积层的核尺寸就是13,再根据13计算出感受野是19,就是dilation=6膨胀卷积的感受野。
解读3:只要不产生空洞,感受野和有padding没padding是没关系的,但生成的特征图的尺寸是有变化的,也就是前面提到的出现了黑边:?
(4)无脑堆叠膨胀卷积的后果:
上图的第一种架构就出现了gridding effect问题,就是生成的特征图的感受野出现大量空洞,也就是就没有学习原图中空洞的像素点,这肯定是不行的,是一种信息丢失,是不利于学习的。膨胀卷积的最大缺点就是容易出现gridding effect。所以你在使用膨胀卷积时,一定要设计好你的核尺寸、卷积层、膨胀尺寸、步长、padding等参数,否则适得其反的效果。
而针对膨胀卷积的使用方法,论文提出了混合膨胀卷积HDC(hybrid dilated convolution)。所以HDC的目标是通过一系列膨胀卷积之后可以完全覆盖底层特征层的方形区域,并且该方形区域中间是没有任何孔洞或缺失的边缘(withou any holes or missing edges)。
为此,论文给出三个建议:空洞卷积(膨胀卷积)的相关知识以及使用建议(HDC原则)-CSDN博客?参考这篇博文吧,写得非常详细,很赞!我上面的截图也是出自这篇博文,感谢作者!
4、1x1卷积核,MLP layer
后面我们开始学深度视觉中的经典架构,到时你会经常遇到1x1卷积核,所以这里我们提前先聊聊它。
1x1卷积核:顾名思义,核上只有一个权重,所以每次卷积操作时,就是逐点卷积,从左往右从上往下,就是特征图上的每个元素都和这个权重相乘得到尺寸一样的新特征图。
1x1卷积核的特点:
(1))完全不改变输入特征图的尺寸,保存了原有特征图的所有信息,可以完整的将特征图中的位置信息传递到下一层。以后经典网络中使用的1x1卷积核都是由于这个原因。
(2)使用1x1卷积核,实现了多个feature map的线性组合。这样输出的feature map就是多个通道的整合信息了,能够使网络提取的特征更加丰富。
(3)通常卷积层后面会跟一个激活函数,1x1卷积层后面也会跟一个激活函数,所以我们还可以在参数量几乎很小、特征图尺寸也不变的情况下,引入了更多的非线性,增强神经网络的表达能力。
(4)我们用1x1卷积核都是为了特殊的目的,其中常见的目的之一就是:减少参数量,加深网络深度。
(5)使用1x1卷积核的卷积层的参数量就是:输入特征图个数*输出特征图个数+偏置个数(偏置个数也是输出特征图的个数)
5、瓶颈设计bottleneck desigh
瓶颈设计是1x1卷积核的一个重要应用场景。就是不改变特征图的尺寸但用它来调整输出的通道数。目的只有两个,一是协助减少网络的参数量,从而减小计算量,二是协助增加网络深度,提升网络效果,同时训练也相对容易一些,就是这两个作用。
在深层网络架构中,瓶颈设计应用得非常非常得广泛,下图右图就是Resnet论文里的Bottleneck V1的架构设计:输入是256张特征图,输出也是256张特征图。如果不用瓶颈架构的设计,就是下图的左图,只要一个3x3的卷积层卷积,但是参数量高达59万多!但是如果设计成右边的瓶颈架构,参数量爆减至7万一点,而且还加深了网络。网络越深效果越好嘛。而且参数越少计算量就越少啊,网络运行效率也提上来了。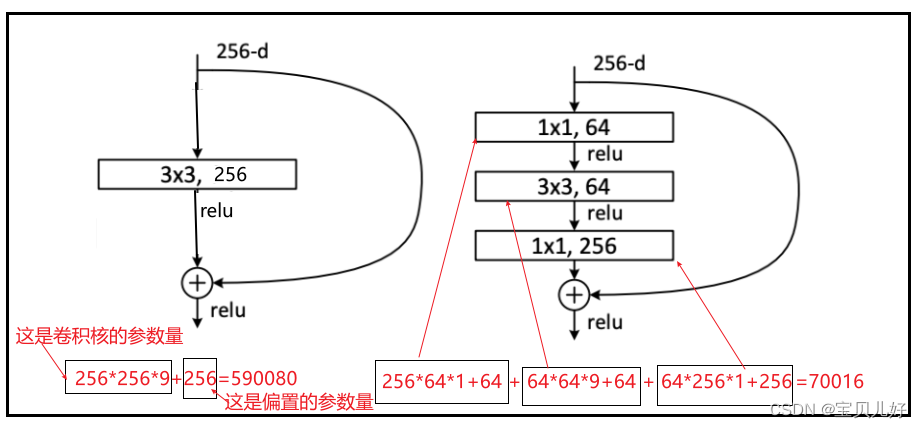
这里举的例子主要是说明1x1卷积核是如何搭建瓶颈架构的,瓶颈架构又是如何减少参数量和加深网络的。这里看不明白可以先搁置,后面会详细讲解残差网络,到时还会和这个东西打交道的。
6、分组卷积Group Convolution
分组卷积最开始被使用在经典入门卷积神经网络AlexNet上,用于解决显存不足的问题。在现在被广泛用于各种轻量化模型中,用于减少运算量和参数量。
分组卷积是通过将输入特征图和输出特征图分组来削减链接数量的卷积方式,如下图所示: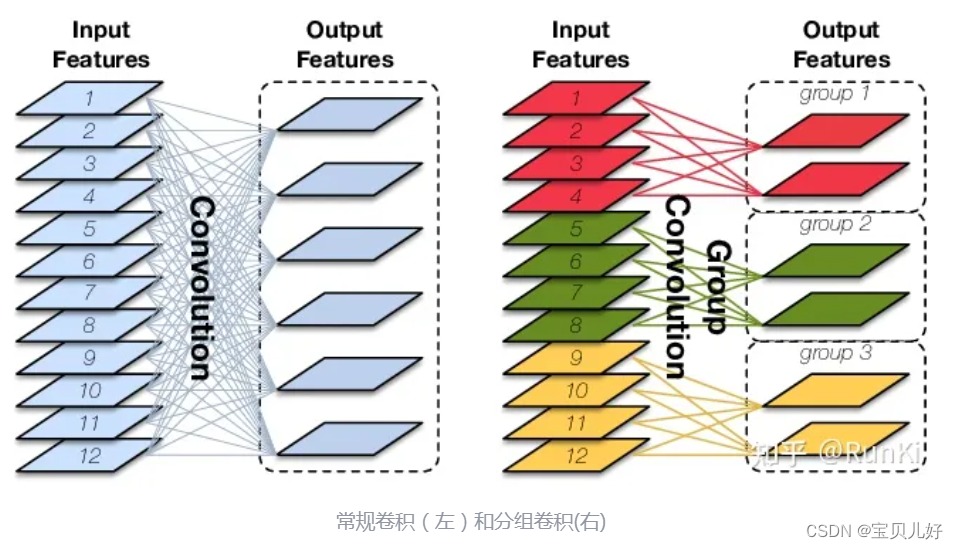
说明:我写的这个系列文章的初心就是做一个学习笔记,所以为了减少工作量,能截图说明问题的我都尽量截图了,所以可能会有点点对不起原图作者,这里先感谢原图的作者!
上图左图就是我们平时用的普通卷积层:输入是一个12个通道的特征图,用六个12层深度的卷积核组对输入的特征图进行卷积操作(用一个12深的卷积核组卷积和输入特征图对应位置,进行全图卷积操作,生成12张特征图,然后把这12张特征图对应位置相加,最后再加一个bias,就得到一张输出特征图)得到六张输出特征图。所以,普通卷积生成的每张输出特征图都是前面所有输入特征图的全连接数据。如果把每张输入特征图看作一个神经元、把每张输出特征图也看作一个神经元,那么输入和输出直接就是全连接的关系。就是每张输出特征图和前面所有输入特征图都有关系。
上图右图就是一个分组卷积,将输入特征图分成了三组group,输出也分成了三组,组合组之间没有关系,组内特征图之间是全连接关系。其实DNN也有分组的,这个就和DNN也是类似,后面输出的特征图只和前面部分输入特征图是全连接关系。
做分组卷积的注意点有:
(1)一般我们都是分偶数个groups组,比如16, 32, 64、128、256等这样的分组。
(2)输入特征图和输出特征图都要分成一样的组数,不让架构就不对,没法跑通数据的。
做分组卷积的目的是:
(1)减少运算量和参数量,相同输入输出大小的情况下,减少为原来的1/g。
(2)隔绝不同组的信息交换。 在某些情况下,如每个输出与输入的一部分特征图相关联时,分组卷积可以取得比常规卷积更好的性能,如输出通道为2,它们分别只与输入的1,2和3,4通道相关,这时最好使用g=2的分组卷积,相当于直接让模型将不相关的输入通道权重设置为零,加快模型收敛。但对于需要考虑所有输入特征图信息的情况,分组卷积会降低模型的性能,对于这个问题,常常在两个分组卷积之间加入Channel_Shuffle模块打乱通道顺序,从而实现不同分组间的信息交换。
分组卷积在pytorch中的实现: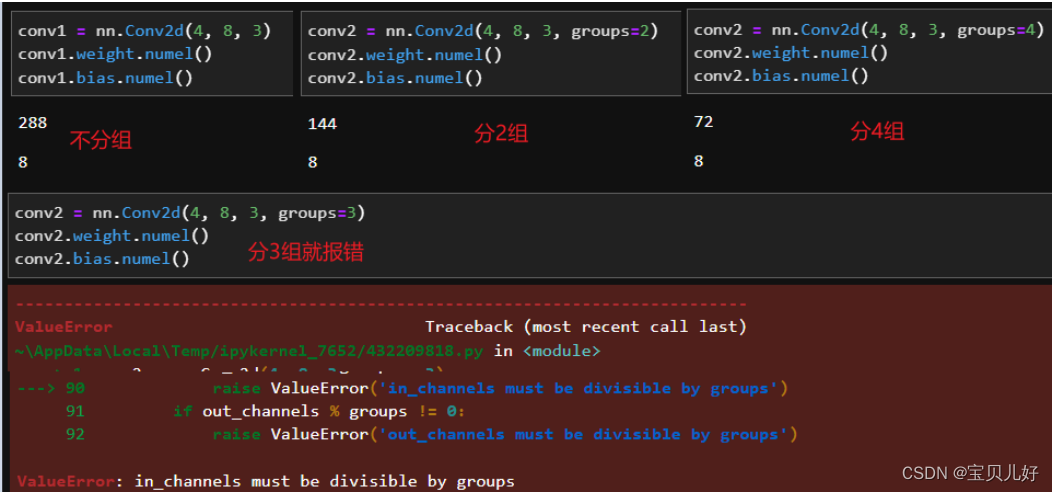
7、深度卷积 Depthwise Convolution
深度卷积是分组卷积的一个特例。当我们把groups设置成输入特征图数量时,就是深度卷积了。当然输出特征图的groups也要和输入的groups相同,当然输入输出只是groups相同,每个groups中的输出特征图可以是1个也可以是多个。就是输入的每个通道都自己分一组,输出也是输入的组数,但组内的特征图可以不是1个。
从深度卷积架构上看,生成的特征图就只与前面一层的对应位置的特征图的数据有关,而和不对应位置的其他特征图无关了,所以深度分离卷积不仅可以帮助卷积层减少参数量,还可以削弱特征图与特征图之间的联系来控制过拟合。
8、深度可分离卷积 Depthwise separable convolution
将深度卷积和1X1卷积层串联就是深度可分离卷积了。深度卷积的结果只与它前面一层的对应特征图相关,所以当我们使用深度卷积后,生成的特征图分别只与前层对应的通道相关,这样就没有有效的利用不同通道在相同空间位置上的feature信息。因此需要1X1卷积(Pointwise Convolution)来将这些Feature map进行组合生成新的Feature map。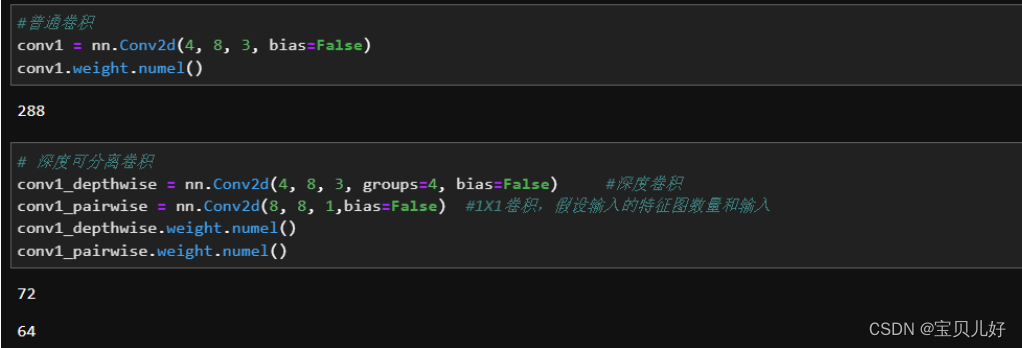
有时这些花式操作的搭配会起到意想不到的效果,尤其是在一些特殊场景中会发挥很巧妙地作用,比如在物体检测场景中:比如检测图片中的小汽车在图片哪里,是在图片的中间?左上?右下?等等,此时就需要使用滑窗识别,就是用一个小尺寸的“窗口”对原始图像滑动切分,就类似卷积层的卷积核的扫描方式,把原始图像分成多小尺寸图像,然后判断这些小尺寸图像中是否有小汽车: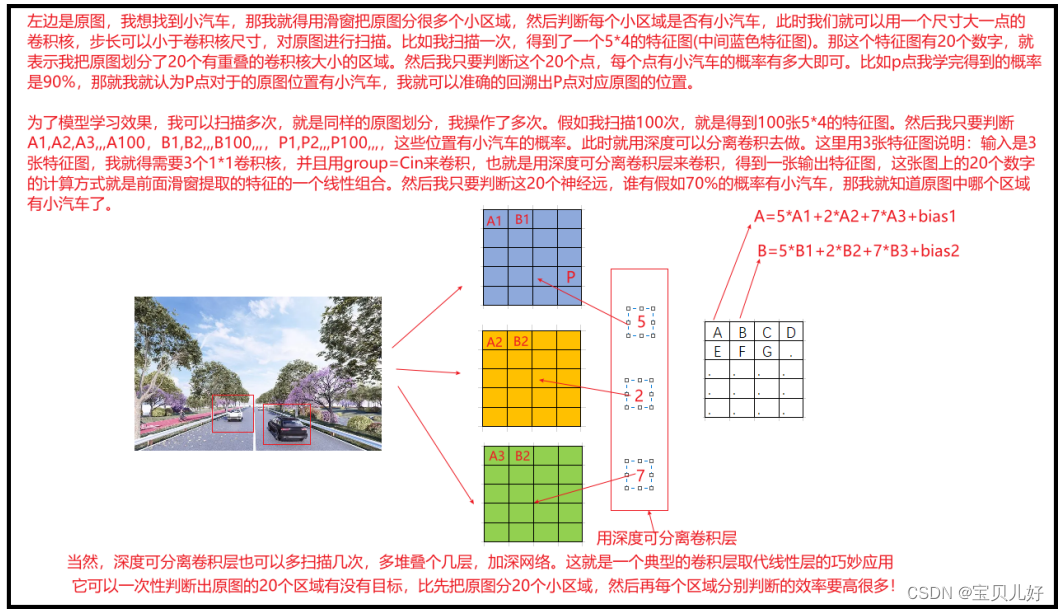
这就非常精巧,就相当于使用一次计算完成了对原始图片所有滑窗的判断,这比先将图像切成窗口,在一个个窗口喂入网络判断要高效很多。这就极大的节省了时间和计算资源,完美!
9、转置卷积(Transposed Convolution)
在众多的无监督深度学习算法中,尤其是生成类算法中,转置卷积是被普遍使用的,比如编码器Encoder-Decoder、Unet、pix2pix都有转置卷积的身影。
转置卷积的地位是和普通卷积是对应的,也是卷积网络中的最最基础的卷积操作,所以都是基础中的基础,是必学的。
普通卷积是把大尺寸数据(比如图像数据,一副图像怎么也有几百个像素点,就是几百个数据)一层层卷成小尺寸数据(比如5x5=25个数据或者7x7=49个数据,总之就是相比原图就没剩几个数据了),然后放入全连接层FC进行分类。转置卷积就正好相反,是把小尺寸数据一层层卷成大尺寸数据!所以转置卷积经常用于生成算法中,比如我就喂入网络少量数据,让网络给我生成一副图像(大尺寸数据)。
转置卷积不是传统卷积的逆运算。传统卷积的逆运算是反卷积Deconvolution。 由于反卷积是卷积操作的逆运算,所以反卷积可以将被卷积之前的图像像素极大程度的复原、甚至生成超越原始图像的图像,所以反卷积常常被用于提升图像像素、为影像上色等场景。而转置卷积只能将图像恢复到被卷积之前的尺寸,就是仅仅恢复个空间信息,是不能恢复被卷积之前的图像的像素信息的。就是一张图像被传统卷积层卷积后,生成了一些特征图,反卷积可以根据这些特征图把图像恢复到原图,但这个恢复也不是非常准确的,但可以恢复大部分信息,比如原图的颜色、轮廓、形状、尺寸等信息。而转置卷积不是干这个的,转置卷积也能恢复,但仅仅恢复的是原图的尺寸,其他信息都恢复不了。
如果说卷积操作是不断从原图中提取各种粒度的纹理基元的过程,那转置卷积就是不断从输入数据中上采样,让输入数据的尺寸不断扩大的过程。这两个过程就是两个不相干的过程,各自有各自的操作流程,也没有啥关联,所以也没有可比性。
当我们喂入转置卷积网络一个或数个随机数,转置卷积层的作用就是一层层扩大这个随机数的尺寸,直到这个尺寸是我们想要的尺寸后,就是我们要生成的图像。至于这个图像到底像不像我想要的图像,还是就是一副瞎子胡乱画的图像,这就交给损失函数了,损失函数是衡量我想要的图像和网络生成的图像之间的差距,我只要让损失函数不断减小,那就算这副图像是瞎子胡乱画的,也会一步步逼近我想要的图像了。或者这样理解:转置卷积网络的任务是把小尺寸数据卷到大尺寸数据即可,损失函数和优化算法是让这个大尺寸数据中每个像素点的值逐渐逼近真实图像的数值的。
还很多资料上讲转置卷积时,经常说转置卷积是一种上采样。很多同学一听上采样,又感觉是哪方神圣,于是冒出很多疑问,云里雾里。其实我认为实在没必要这么卖弄。其实上采样通俗的理解就是让少量数据变成大量数据、下采样就是让大量数据变成少量数据。在图像数据领域中,下采样其实就是将大尺寸的原图不断缩小的过程,比如缩小图片;上采样就是将小尺寸的图像变成大尺寸的图像,比如放大图片。我们平时的放缩图片就是上下采样的实例。所以从这个角度说,转置卷积也确实是让图片尺寸放大了,所以也确实是上采样的一种。但是实现上采样的方法有很多,不只是通过转置卷积实现,还可以通过比如最近邻插值、双线性插值和、反池化等手段实现。这部分在我的opencv中有详细讲解,感兴趣的可以自己去找找看。其实pytorch中也有上采样的API: torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)这个API采用的就是最近邻、线性、双线性、双三次(bicubic)、三线性(trilinear)等插值算法,才是典型的传统采样手段。
说这么多就是想说,其实转置卷积就是转置卷积自己,也别扯什么上下采样,也更不是传统卷积的逆运算!所以你就单独好好理解转置卷积即可。好好区别转置卷积和普通卷积的不同之处,因为二者经常搭配使用。普通卷积让图像尺寸变小,转置卷积让图像尺寸变大,所以二者经常一起出现,到时参数设置你别搞混就行。
(1)转置卷积的卷积过程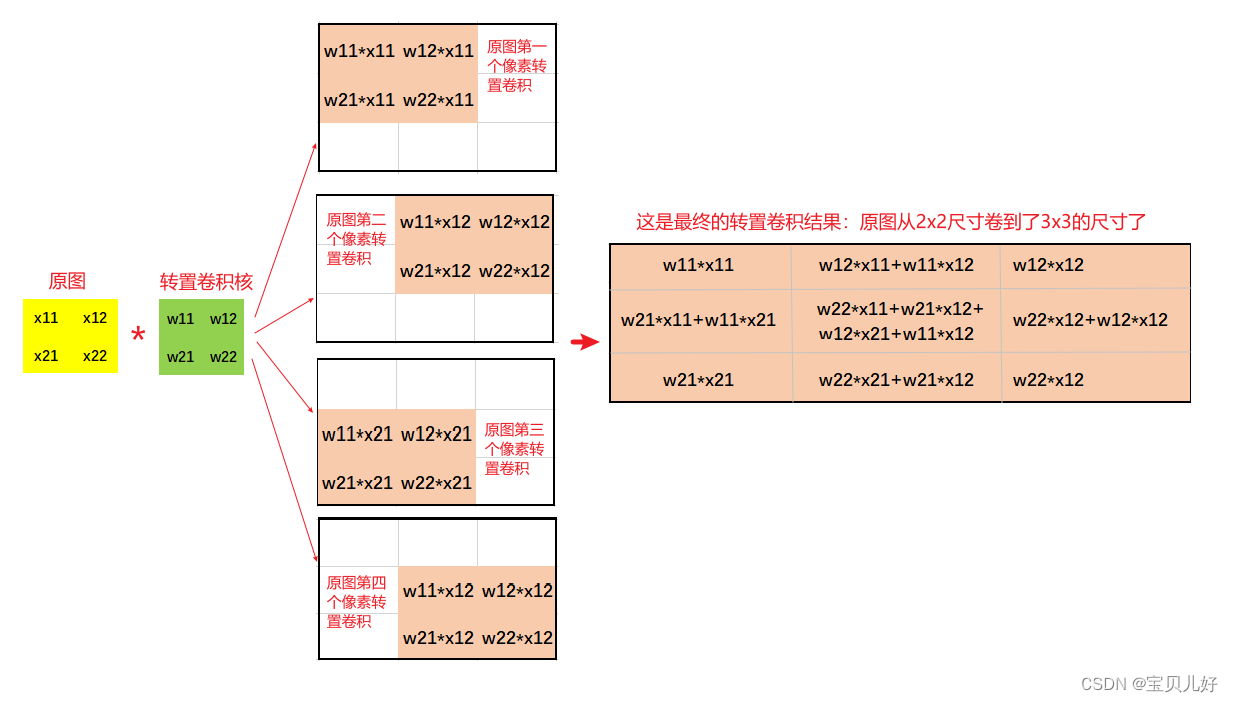
这就是转置卷积的形象化的计算过程,就是卷积核和原图的每个像素分别卷积,把原图一个像素上采样成卷积核尺寸个像素;原图的每个像素点都上采样完毕后,然后把所有的上采样结果按照相对位置相加,这个相对位置是上下/左右都是移动一步,这个步子和步长没有任何关系!不管stride是多少padding是多少,这里都是上下/左右都是移动一步进行相加。
(2)转置卷积层的stride和padding
上面的卷积过程是stide=1,padding=0的情况下的转置卷积操作,下面看看如果stride和padding设置为其他值时,是如何进行转置卷积的:
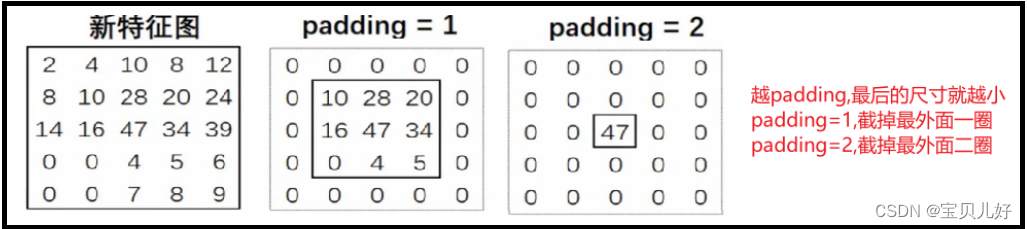
可见,转置卷积的stride和padding和普通卷积的这两个参数的意思完全不一样!
转置卷积的stride是作用于原图的,stride=2,就把原图膨胀一下,然后再进行转置卷积操作。stride=3,原图就膨胀两下,再转置卷积操作。
但是有没有发现,当步长变长时,由于膨胀的都是0,所以卷积后的结果也都是0,所以对后面的加和是没有影响的,影响的只是加和时的相对位置!
转置卷积的padding却是作用在生成的特征图上的!而且是对生成的特征图进行消减的!padding=1就把最外面的一圈变成0,padding=2就把最外面两圈变成0。
(3)卷积过程在pytorch底层的计算方法:
转置卷积也是有自己的代码模块,但是有趣的是,它内置的原理还是普通卷积形式: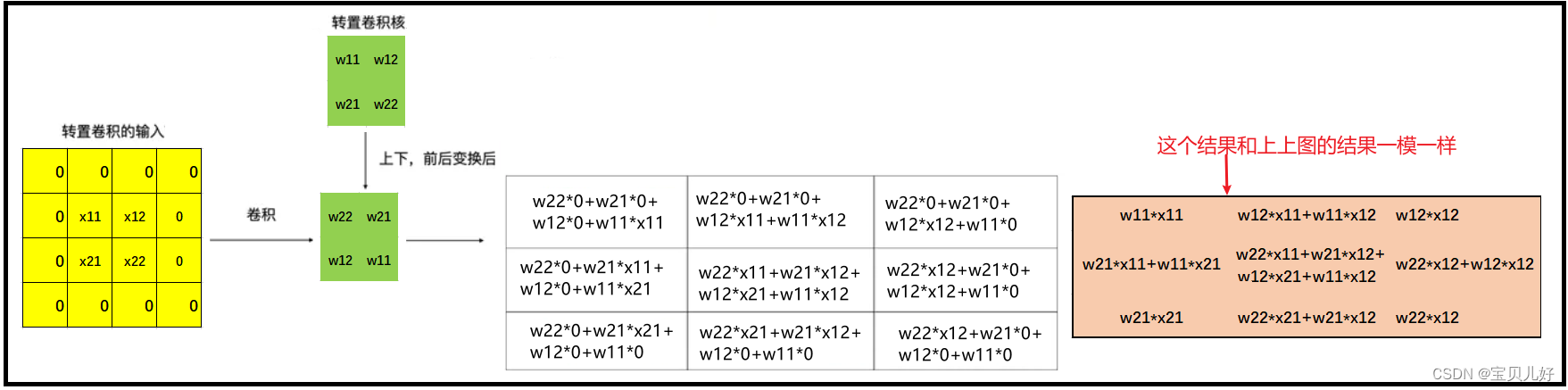
所以,经过以上处理,转置卷积计算又变回了卷积计算。而卷积计算的底层数学处理又是矩阵乘法,具体实现过程我们在卷积架构章节中有详细描述,这里就不赘述了。
在此再把转置卷积的计算过程梳理一下:
第一步:对输入特征图进行补零操作(补kernel-1圈0),得到新的特征图。
第二步:将转置卷积的卷积核上下、左右变换作为新的卷积核。
第三步:利用新的卷积核在新的特征图上进行步长为1,padding为0的卷积操作。而卷积操作就是之前的普通卷积操作的流程。
(4)另外角度理解转置卷积的原理
我在网上看别人写转置卷积时,发现有人还有另外一些角度,也是思路非常清晰,通俗易懂,先整理出来以免日后忘记:
那此时转置卷积的问题就变成:找到一个卷积核D,让D和B进行普通卷积操作就得到C了。那如何找到卷积核D,根据B、C的形状就可以知道D的形状和D中0值和非0值的位置了。那我先在D中的非0值位置随机生成一个D,让D和B进行普通卷积操作就得到C的形状了。至于C变形成二维后是不是我想要的,就交给损失函数和优化算法,优化算法会一步步把D迭代成恰当的D,让D卷积B后得到的C的数值也是我们想要的数值,此时,是不是就从小尺寸数据B生成了大尺寸数据C了,就是生成算法的基本流程。
(5)转置卷积输出的特征图尺寸:
左边是普通卷积层卷积后的输出尺寸,右边是转置卷积层卷积后的输出尺寸。现在我们推导一下右边的公式:
- 假设转置卷积的输入宽度是H,卷积核的大小是K,encoding时的stride=s,padding=p
- 先给输入图像外圈补K-1圈0,此时输入的宽度是:H+2*(K-1)
- 当stride=s时,是让输入膨胀s-1次,膨胀后输入的宽度是:H+2*(K-1)+(H-1)*(s-1)
- 上述处理完之后,就等价为'padding=0,stride=1,kernel=K'的标准卷积操作了,带入左图的公式,计算输出的尺寸是:H+2*(K-1)+(H-1)*(s-1)-K+1
- 处理padding: H+2*(K-1)+(H-1)*(s-1)-K+1-2p
整理后结果就是:K + (H-1)*s -2p
(6)小结:
stride是增加输出特征图尺寸的。padding是减小输出特征图尺寸的,并且padding对输出特征图的影响是非常大的,所以这个参数我们一般不设,要设也是1或者2,不会再大了。这个参数主要是用来调整尺寸的,比如我转置卷积完毕后的图像是32x32,但是我模型的输入尺寸是28x28,我们采用这个参数来调整。 和传统卷积不一样,传统卷积是防止边角的信息损失才pading的,而转置卷积是要裁剪一圈才padding的。
在pytorch中,我们还可以对转置卷积执行空洞转置卷积(膨胀)、分组转置卷积等操作。同时参数量少、稀疏交互等特性是也适用转置卷积。
转置卷积层的卷积核尺寸和普通卷积层的卷积核尺寸不一样!普通卷积层我们一般设置奇数尺寸的卷积核,但是转置卷积层我们一般是设置成偶数尺寸的卷积核。
我们使用卷积操作的时候是非常关注输入输出的尺寸的。普通卷积层有一些特殊搭配,比如kernel_size=3,stride=1,padding=1或者kernel_size=5,stride=1,padding=2这种特殊搭配,是不改变输入输出尺寸的。同理转置卷积也有一些常用的参数组合:

(7)用pytorch实现一个转置卷积层
API里面的参数其实在前面都一直有提到,所以这里就不解释参数了,多演示一些相关的方法和属性吧。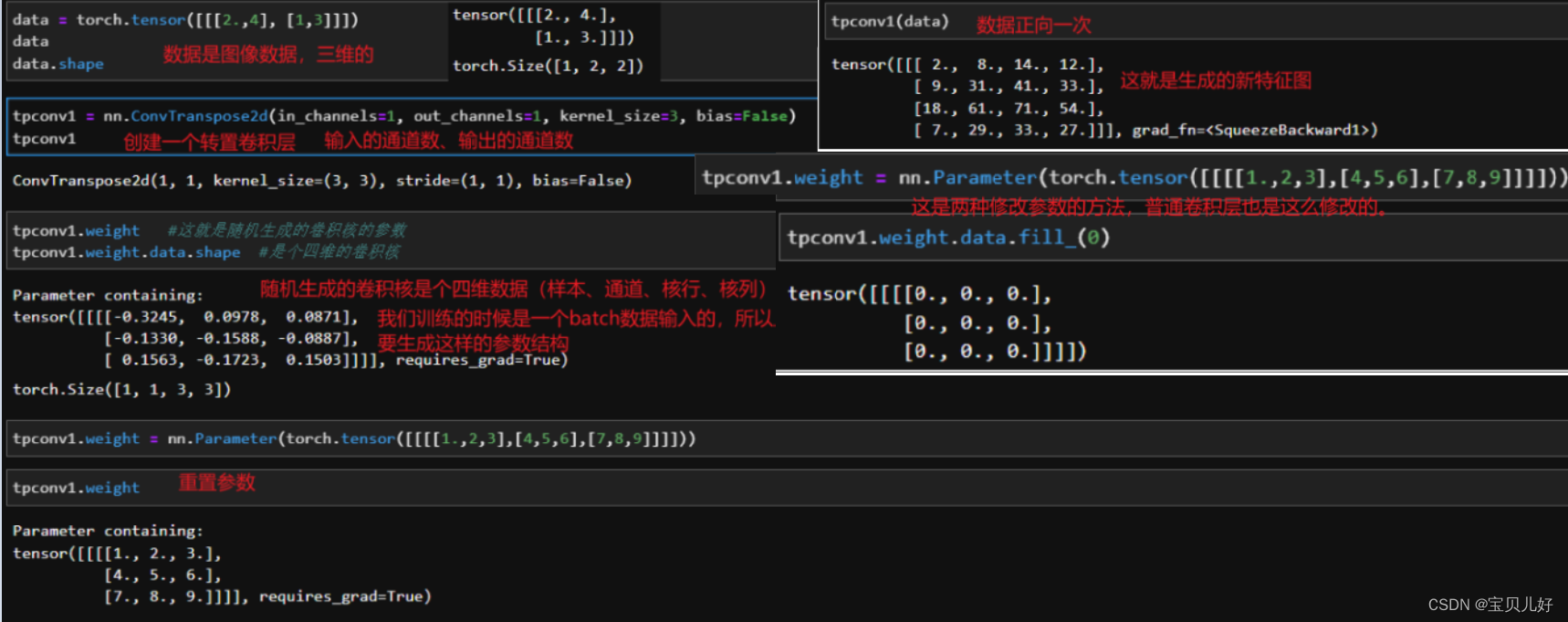
10、全局平均池化层 global average pooling,GAP层
除了卷积层有花式操作外,池化层也有一个花式操作:全局平均池化层 global average pooling,GAP层
全局平均池化层(GAP)是在2013年的《Network In Network》(NIN)中首次提出,其实就是对每一个通道图所有像素值求平均值,然后得到一个新的1 * 1的通道图。所以GAP层的本质就是池化层,池化方式是平均池化,池化核尺寸是输入特征图的尺寸,步长也是特征图尺寸,没有padding。所以,不管传入GAP层的是多少张特征图,CAP层都会将其转化为(张数, 1, 1)这种结果。所以有人就会用1x1卷积核先把通道调成类别个数,然后用CAP层把结果转化为(n_classes,1,1),使得在形式上实现多分类的功能。NiN网络就是使用1X1卷积层连接GAP的方式实现10分类,但是这种做法仅仅是带来了参数量的减少,并没有带来效果的提升,所以NiN也没有流行起来。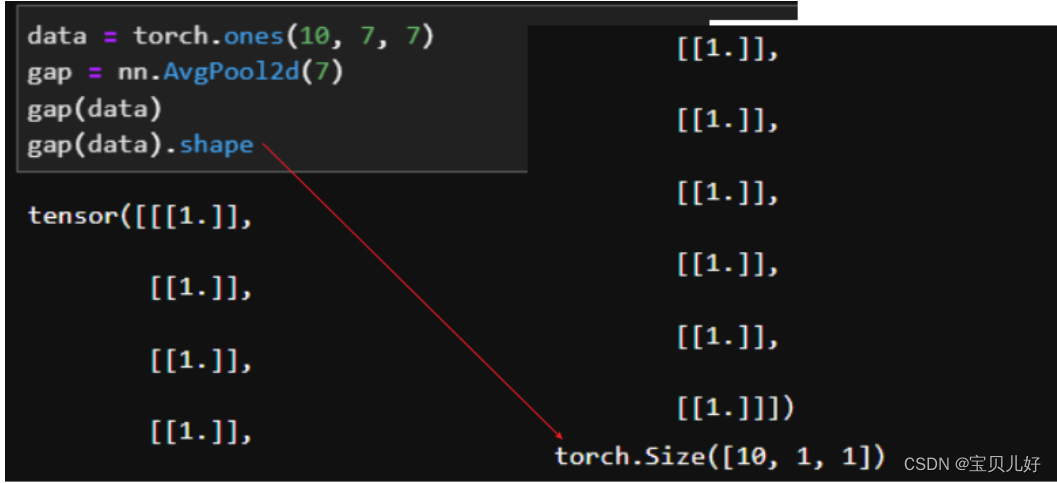
暂时先讲这么多个点吧,以后遇到了再添加。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《剑指offer》数学第二题:求1+2+3+...+n
- MyBatis——自定义MyBatis(了解)
- ATA-P系列功率放大器在压电叠堆中的作用是什么
- Django 构建动态前端页面详解
- 万森与北星,爱要不留遗憾
- Jenkins 构建 AWS Fargate 服务更新控制
- 【并发】AtomicInteger很安全
- JavaScript中这些事件(event)类型你都知道吗?
- 【数据结构与算法】排序算法:冒泡排序,冒泡排序优化,选择排序、选择排序优化
- 网络基础名词