数据湖技术之Paimon
一、简介
Flink社区希望能够将Flink的Streaming实时计算能力和Lakehouse新架构优势进一步结合,推出新一代Streaming Lakehouse技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。
Apache Paimon是一个流数据湖平台,具有高速数据摄取、变更日志跟踪和高效的实时分析的能力。
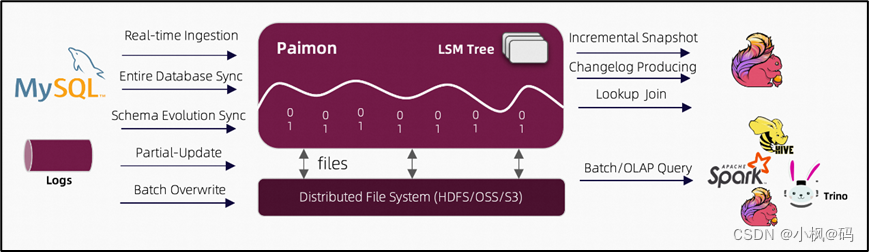
1.1 读/写
Paimon支持多种读/写数据和执行OLAP查询的方式
(1)对于读取,它支持以下方式消费数据:
从历史快照(批处理模式)
从最新的偏移量(在流模式下)
以混合方式读取增量快照
(2)对于写入,它支持来自数据库变更日志(CDC)的流式同步或来自离线数据的批量插入/覆盖。
1.2 生态系统
除了Apache Flink外,Paimon还支持Apache Hive、Apache Spark、Trino等其他计算引擎的读取。
1.3 内部
在底层,Paimon将列式文件存储在文件系统/对象存储上,并使用LSM树结构来支持大量数据更新和高性能查询。
1.4 统一存储
对于Apache Flink这样的流引擎,通常有三种类型的连接器:
- 消息队列:例如Apache Kafka,在源阶段和中间阶段都使用它,以保证延迟保持在秒级。
- OLAP系统:例如Clickhouse,它以流方式接收处理后的数据并为用户的即席查询提供服务
- 批量存储:例如Apache Hive,它支持传统批处理的各种操作,包括INSERT、OVERWRIT
Paimon提供表抽象,它的使用方式与传统数据库没有什么区别:
- 在批处理模式下,它就像一个Hive表,支持Batch SQL的各种操作。查询它以查看最新的快照。
- 在流执行模式下,它的作用就像一个消息队列,查询它的行为就像从历史数据永不过期的消息队列中查询流更改日志。
二、核心特性
1)统一批处理和流处理
批量写入和读取、流式更新、变更日志生成,全部支持。
2)数据湖能力
低成本、高可靠性、可扩展的元数据。 Apache Paimon 具有作为数据湖存储的所有优势。
3)各种合并引擎
按照您喜欢的方式更新记录。保留最后一条记录、进行部分更新或将记录聚合在一起,由您决定。
4)变更日志生成
Apache Paimon 可以从任何数据源生成正确且完整的变更日志,从而简化您的流分析。
5)丰富的表类型
除了主键表之外,Apache Paimon还支持append-only表,提供有序的流式读取来替代消息队列。
6)模式演化
Apache Paimon 支持完整的模式演化。您可以重命名列并重新排序。
三、基本概念
1.1 Snapshot
快照捕获表在某个时间点状态。用户可以通过最新的快照来访问表的最新数据。通过时间旅行,用户还可以通过较早的快照访问表的先前状态。
1.2?Partition
Paimon采用与Apache Hive相同的分区概念来分离数据。
1.3 Bucket
未分区表或分区表中分区被细分为存储桶,以便为可用于更有效查询的数据提供额外的结构。
桶的范围由记录中的一列或多列的哈希值确定。用户可以通过提供bucket-key选项来指定分桶列。如果未指定bucket-key分桶列选项,则主键(如果已定义)或完整记录将用作存储桶键。
桶是读写的最小存储单元,因此桶的数量限制了最大处理并行度。不过这个数字不应该太大,因为它会导致大量小文件和低读取性能。一般来说,建议每个桶的数据大小为1GB左右。
1.4 Consistency Guarantees一致性保证
Paimon Writer使用两阶段提交协议以原子方式将一批记录提交到表中。每次提交在提交时最多生成两个快照。
对于任意两个同时修改表的writer,只要他们不修改同一个存储桶,他们的提交都是可序列化的。如果他们修改同一个存储桶,则仅保证快照隔离。也就是说,最终表的状态可能是两次提交的混合,但不会丢失任何更改。
1.5 文件布局
一张表的所有文件都存储在一个基本目录下。Paimon文件以分层方式组织。下图说明了文件布局。
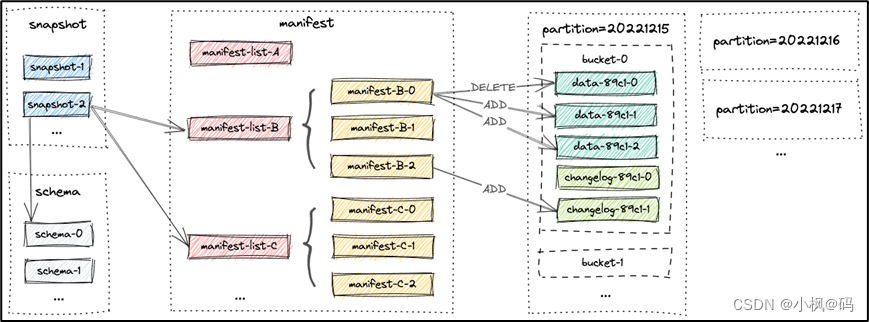
1.5.1 Snapshot Files
所有快照文件都存储在快照目录中。
快照文件是一个 JSON 文件,包含有关此快照的信息,包括:
正在使用的Schema文件
包含此快照的所有更改的清单列表(manifest list)
1.5.2?Manifest Files
所有清单列表(manifest list)和清单文件(manifest file)都存储在清单(manifest)目录中。
清单列表(manifest list)是清单文件名(manifest file)的列表。
清单文件(manifest file)是包含有关 LSM 数据文件和更改日志文件的文件信息。例如对应快照中创建了哪个LSM数据文件、删除了哪个文件。
1.5.3 Data?Files
数据文件按分区和存储桶分组。每个存储桶目录都包含一个 LSM 树及其变更日志文件。目前,Paimon 支持使用 orc(默认)、parquet 和 avro 作为数据文件格式。
1.5.4?LSM Trees
Paimon 采用 LSM 树(日志结构合并树)作为文件存储的数据结构。
1.5.5?Sorted Runs
LSM 树将文件组织成多个Sorted Run。Sorted Run由一个或多个数据文件组成,并且每个数据文件恰好属于一个Sorted Run。
数据文件中的记录按其主键排序。在Sorted Run中,数据文件的主键范围永远不会重叠。
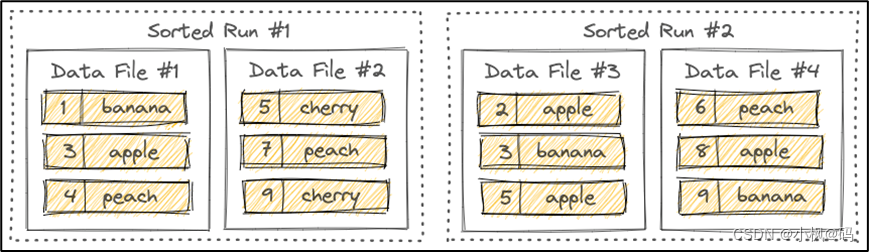
正如您所看到的,不同的Sorted Run可能具有重叠的主键范围,甚至可能包含相同的主键。查询LSM树时,必须合并所有Sorted Run,并且必须根据用户指定的合并引擎和每条记录的时间戳来合并具有相同主键的所有记录。
写入LSM树的新记录将首先缓存在内存中。当内存缓冲区满时,内存中的所有记录将被排序并刷新到磁盘。
1.5.6?Compaction
????????当越来越多的记录写入LSM树时,Sorted Run的数量将会增加。由于查询LSM树需要将所有Sorted Run合并起来,太多Sorted Run将导致查询性能较差,甚至内存不足。
????????为了限制Sorted Run的数量,我们必须偶尔将多个Sorted Run合并为一个大的Sorted Run。这个过程称为Compaction。
????????然而,Compaction是一个资源密集型过程,会消耗一定的CPU时间和磁盘IO,因此过于频繁的Compaction可能会导致写入速度变慢。这是查询和写入性能之间的权衡。 Paimon 目前采用了类似于 Rocksdb 通用压缩的Compaction策略。
????????默认情况下,当Paimon将记录追加到LSM树时,它也会根据需要执行Compaction。用户还可以选择在“专用Compaction作业”中独立执行所有Compaction。
四、CDC集成(具有整库同步和schema变更的功能)
Paimon支持多种通过模式演化(schema变更)将数据提取到Paimon表中的方法。这意味着添加的列会实时同步到Paimon表中,并且不会为此重新启动同步作业。
目前支持以下同步方式:
- MySQL同步表:将MySQL中的一张或多张表同步到一张Paimon表中。
- MySQL同步数据库:将整个MySQL数据库同步到一个Paimon数据中。
- API同步表:将您的自定义DataStream输入同步到一张Paimon中。
- Kafka同步表:将一个Kafka topic的表同步到一张Paimon表中。
- Kafka同步数据库:将一个包含多表的Kafka主题或多个各包含一表的主题同步到一个Paimon数据库中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JavaScript中绑定事件的方法
- day5 select poll
- 基于 IP 多播的网络会议程序(2024)
- 【昕宝爸爸小模块】深入浅出之Java 8中的 Stream
- vue2+webpack升级vue3+vite,报错Cannot read properties of null (reading ‘isCE‘)
- Linux反向、分离解析与主从复制
- 高精度算法笔记
- c盘扩容时,d盘无法删除卷问题
- 数据链路层流量控制与传输层流量控制对比
- flowable流程引擎中包容网关、排他网关、并行网关之间的区别与联系