哈希表的实现(2):拉链法实现哈希表

一,拉链法
在使用线性探测法实现哈希表时,会发生哈希冲突。这个时候就得向后找位置给新插入的值。这个过程无疑会对哈希表的效率有很大的影响。那我们能不能通过另一种方式来实现哈希表,让哈希表不会发生哈希冲突呢?答案当然是可以的,这个方法就被叫做拉链法。
拉链法:
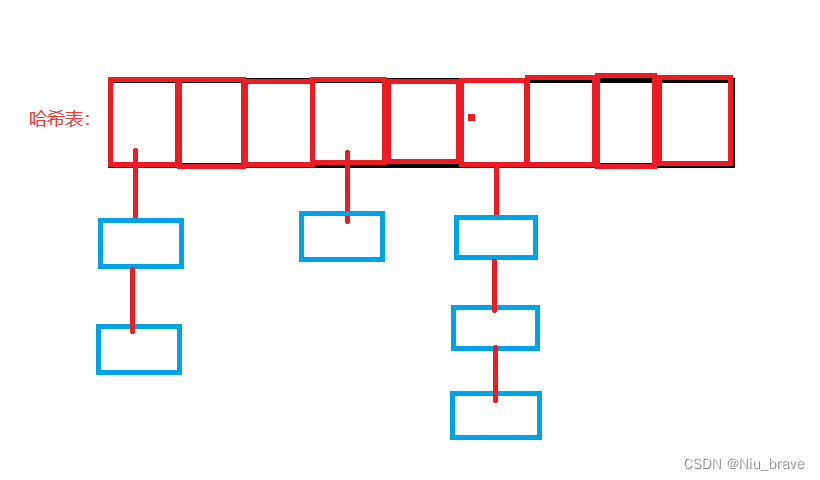
拉链法就是让哈希表里的元素存的是一个单链表指针,然后像链表一样头插哈希值相同的元素到同一个位置上。
如图所示:
二,哈希表的实现
1,定义节点
再stl库里面有现成的单链表可以使用,但是为什么我们要自己定义一个节点呢?这其实是为了后续的哈希表的封装打下基础。
节点定义如下:
template<class K,class V>
struct Node
{
Node(const pair<K,V>key)
:_kv(key)
,next(nullptr)
{}
pair<K, V>_kv;
Node<K, V>* next;
};?2,定义哈希表
还是和使用线性探测法实现哈希表类似,哈希表里面主要有两个成员:
1,vector<Node<K,V>*>_hashtables。
2,_n。
哈希表结构如下:
class Hash_table
{
public:
Hash_table()
{
_hashtables.resize(10, nullptr);//先初始化,开好十个空间
}
private:
vector<Node<K,V>*>_hashtables;
size_t _n = 0;
}3,Insert函数实现
1,算出hashi,使用的方法还是除留余数法法。
2,插入,使用头插法插入。不需要判断是否为空。
3,当插入的个数_n ==_hashtables.size()时便要扩容。
在这里扩容的方式有两种:
?1,创建新的哈希表,调用Insert将旧表的内容插入到新表里面。插入结束后再将新表换给旧表
?2,创建新的vector<Node<K,V>*>new_tables,再将旧表的_hashtables里的节点一个一个的搬到new_tables里。搬完以后再将新表换给旧表。
代码如下:
//插入函数
bool Insert(const pair<K, V> key)//插入节点
{
if (_n == _hashtables.size())//表已被填满
{
// //解决方式1:开一个新表,将旧表里面的内容重新插入到新表里在交换
// Hash_table<K, V>new_Ht;
// int newSize = _hashtables.size()*2;
// new_Ht._hashtables.resize(newSize);
// for (int i = 0;i < _hashtables.size();i++)
// {
// Node<K, V>* cur = _hashtables[i];
// while(cur)
// {
// new_Ht.Insert(cur->_kv);
// cur = cur->next;
// }
// }
// _hashtables.swap(new_Ht._hashtables);
//解决方式2:不要直接插入,而是要将就表里的链移到新表里,然后再交换。这种方式更加高效,不会浪费太多的空间
vector<Node<K,V>*> new_tables;
int newSize = 2 * _hashtables.size();//扩容后的大小
new_tables.resize(newSize);//给新的new_tables开两倍的空间
for (int i = 0;i < _hashtables.size();i++)
{
Hash Func;
Node<K,V>* cur =_hashtables[i];
while (cur)//将链表节点搬到new_tables里
{
Node<K,V>* next = cur->next;
size_t idx = Func(cur->_kv.first) % newSize;
cur->next = new_tables[idx];
new_tables[idx] = cur;
cur = next;
}
_hashtables[i] = nullptr;//搬完以后要将原来旧表对应的值变为nullptr,fan防止二次析构
}
_hashtables.swap(new_tables);//交换
}
Hash Func;//类模板实例化出来一个类
size_t hashi = Func(key.first) % _hashtables.size();//计数出映射的位置
Node<K,V>* newNode = new Node<K,V>(key);//先new出来一个新节点
//头插
Node<K,V>* Next = _hashtables[hashi];
_hashtables[hashi] = newNode;
newNode->next = Next;
_n++;//插入成功个数加1
return true;
}4,Find函数实现
1,计算hashi,遍历查找每这个hashi对应的链表,查找到了便返回该节点的地址。
2,遍历以后没有返回结果便返回nullptr。
代码:Hash hf表示一个仿函数,作用是将key转化为整型值。
Node<K, V>* Find(const K& key)
{
Hash hf;
int hashi = hf(key) % _hashtables.size();//计算hashi
Node<K, V>* cur = _hashtables[hashi];
while (cur)//遍历hashi对应的链表
{
if (cur->_kv.first== key)
{
return cur;//找到了便可以返回节点d
}
cur = cur->next;
}
return nullptr;//找不到便返回nullptr
}5,Erase函数
1,通过计算得到hashi。
2,再遍历hashi,进行删除节点的操作。
3,_n--
代码:
bool Erase(const K& key)
{
int hashi = key % _hashtables.size();//计算hashi
//定义两个指针pre和cur,来进行删除操作,pre保存cur的上一个节点的地址。
Node<K, V>* cur = _hashtables[hashi];
Node<K, V>* pre = nullptr;
while (cur)
{
if (cur->_kv.second == key)
{
if (pre)
{
pre->next = cur->next;//cur不是头节点时
}
else
{
_hashtables[hashi] = cur->next;//cur是头节点时
}
delete cur;//删除cur指向的节点
_n--;//个数减一
return true;
}
pre = cur;
cur = pre->next;
}
return false;
}6,析构函数
1,Node<K,V>节点是我自己定义的节点,所以编译器不会自动的释放这些节点。所以需要我们自己来手动释放。
2,释放的方式也很简单,通过遍历找到表里不是空的节点。再遍历这些节点依次释放。
代码:
~Hash_table()//vector里面的链表时自己实现的,所以要写构造函数将这些节点释放
{
int n = _hashtables.size();
for (int i = 0;i < n;i++)//遍历表
{
Node<K, V>* cur = _hashtables[i];//当前节点
Node<K, V>* next = nullptr;//下一个节点
while (cur)//遍历释放节点
{
next = cur->next;
delete cur;
cur = next;
}
}
}7,拷贝构造函数
1,为了避免析构两次的问题,就得构造新的Node<K,V>*节点,这个节点里的值由拷贝的对象提供
2,实现链表的链接。
代码:
//拷贝构造函数
Hash_table(const Hash_table<K, V>& hash)
{
int newSize = hash._hashtables.size();//拷贝对象的表的大小
_hashtables.resize(newSize);//开与拷贝对象一样大小的空间
for (int i = 0;i < newSize;i++)
{
Node<K, V>* cur = hash._hashtables[i];//cur指向拷贝对象的链表节点
Node<K, V>* headNode = nullptr;//指向拷贝者的链表头
Node<K, V>* ptr = nullptr;//指向拷贝者的链表节点
if (cur)
{
while (cur)
{
Node<K, V>* node = new Node<K, V>(cur->_kv);//new出新节点,避免二次析构
if (!headNode)//链接操作
{
headNode = node;//头节点为空,就先将头节点初始化。
}
else//链接操作
{
ptr = headNode;
while (ptr->next)//找到链表的尾节点
{
ptr = ptr->next;
}
ptr->next = node;
}
cur = cur->next;
_n++;
}
_hashtables[i] = headNode;//链接完了以后将头节点交给_hashtables[i]
}
}
}8,赋值重载
1,构造新表,拷贝赋值者。
2,将新表换给自己。
代码:
//赋值重载
Hash_table<K, V>& operator =(const Hash_table<K, V>&hash)
{
Hash_table<K, V>new_Ht(hash);
_hashtables.swap(new_Ht._hashtables);
_n = new_Ht._n;
return *this;
}三,全部代码
//开散列,拉链法实现哈希表
#include<string>
#include<iostream>
#include<vector>
using namespace std;
namespace close_locate
{
template<class K,class V>
struct Node
{
Node(const pair<K,V>key)
:_kv(key)
,next(nullptr)
{}
pair<K, V>_kv;
Node<K, V>* next;
};
template <class K>
struct Getkey
{
size_t operator()(const K& key)
{
return size_t(key);
}
};
template <>
struct Getkey<string>
{
size_t operator()(const string& key)
{
size_t sum = 0;
int n = key.size();
for (int i = 0;i < n;i++)
{
sum = sum * 31 + key[i];
}
return sum;
}
};
template <class K,class V,class Hash = Getkey<K>>
class Hash_table
{
public:
template<class K>
int Getkey(const K& key)
{
Hash hf;
return hf(key)%_hashtables.size();
}
Hash_table()
{
_hashtables.resize(10, nullptr);//先初始化,开好十个空间
}
~Hash_table()//vector里面的链表时自己实现的,所以要写构造函数将这些节点释放
{
int n = _hashtables.size();
for (int i = 0;i < n;i++)
{
Node<K, V>* cur = _hashtables[i];
Node<K, V>* next = nullptr;
while (cur)
{
next = cur->next;
delete cur;
cur = next;
}
}
}
//拷贝构造函数
Hash_table(const Hash_table<K, V>& hash)
{
//Hash_table<K, V> new_Ht;
int newSize = hash._hashtables.size();
_hashtables.resize(newSize);
for (int i = 0;i < newSize;i++)
{
Node<K, V>* cur = hash._hashtables[i];
Node<K, V>* headNode = nullptr;
Node<K, V>* ptr = _hashtables[i];
if (cur)
{
while (cur)
{
Node<K, V>* node = new Node<K, V>(cur->_kv);
if (!headNode)
{
headNode = node;
}
else
{
ptr = headNode;
while (ptr->next)
{
ptr = ptr->next;
}
ptr->next = node;
}
cur = cur->next;
_n++;
}
_hashtables[i] = headNode;
}
}
}
//赋值重载
Hash_table<K, V>& operator =(const Hash_table<K, V>&hash)
{
Hash_table<K, V>new_Ht(hash);
_hashtables.swap(new_Ht._hashtables);
_n = new_Ht._n;
return *this;
}
//插入函数
bool Insert(const pair<K, V> key)//插入节点
{
if (_n == _hashtables.size())//表已被填满
{
// //解决方式1:开一个新表,将旧表里面的内容重新插入到新表里在交换
// Hash_table<K, V>new_Ht;
// int newSize = _hashtables.size()*2;
// new_Ht._hashtables.resize(newSize);
// for (int i = 0;i < _hashtables.size();i++)
// {
// Node<K, V>* cur = _hashtables[i];
// while(cur)
// {
// new_Ht.Insert(cur->_kv);
// cur = cur->next;
// }
// }
// _hashtables.swap(new_Ht._hashtables);
//解决方式2:不要直接插入,而是要将就表里的链移到新表里,然后再交换。这种方式更加高效,不会浪费太多的空间
vector<Node<K,V>*> new_tables;
int newSize = 2 * _hashtables.size();
new_tables.resize(newSize);
for (int i = 0;i < _hashtables.size();i++)
{
Hash Func;
Node<K,V>* cur =_hashtables[i];
while (cur)
{
Node<K,V>* next = cur->next;
size_t idx = Func(cur->_kv.first) % newSize;
cur->next = new_tables[idx];
new_tables[idx] = cur;
cur = next;
}
_hashtables[i] = nullptr;
}
_hashtables.swap(new_tables);
}
Hash Func;//类模板实例化出来一个类
size_t hashi = Func(key.first) % _hashtables.size();//计数出映射的位置
Node<K,V>* newNode = new Node<K,V>(key);//先new出来一个新节点
//头插
Node<K,V>* Next = _hashtables[hashi];
_hashtables[hashi] = newNode;
newNode->next = Next;
_n++;
return true;
}
Node<K, V>* Find(const K& key)
{
Hash hf;
int hashi = hf(key) % _hashtables.size();
Node<K, V>* cur = _hashtables[hashi];
while (cur)
{
if (cur->_kv.first== key)
{
return cur;
}
cur = cur->next;
}
return nullptr;
}
bool Erase(const K& key)
{
int hashi = key % _hashtables.size();
Node<K, V>* cur = _hashtables[hashi];
Node<K, V>* pre = nullptr;
while (cur)
{
if (cur->_kv.second == key)
{
if (pre)
{
pre->next = cur->next;
}
else
{
_hashtables[hashi] = cur->next;
}
delete cur;
_n--;
return true;
}
pre = cur;
cur = pre->next;
}
return false;
}
void buketCount()//统计哈希桶的各种数据
{
int Maxlen = 0;//统计最长的哈希桶长度
int sum = 0;//统计一共有多少个桶
double averagelen = 0;//统计平均有多少个桶
int buketCount = 0;
int n = _hashtables.size();
for (int i = 0;i < n;i++)
{
Node<K, V>* cur = _hashtables[i];
if (cur)
{
buketCount++;
int len = 0;
while (cur)
{
sum++;
len++;
cur = cur->next;
}
Maxlen = max(Maxlen, len);
}
}
averagelen = (double)sum / (double)buketCount;
cout << "buketCount: " << buketCount << " " << "averagelen: " << averagelen << " " << "Maxlen: " << Maxlen << " ";
}
void Print()
{
int n = _hashtables.size();
for (int i = 0;i < n;i++)
{
Node<K, V>* cur = _hashtables[i];
while (cur)
{
cout << cur->_kv.first << ":" << cur->_kv.second << endl;;
cur = cur->next;
}
}
cout << endl << endl;
}
private:
vector<Node<K,V>*>_hashtables;
size_t _n = 0;
};
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux:掌握systemctl命令控制软件的启动和关闭、掌握使用ln命令创建软连接
- Traefik Ingress Controller
- msvcr120.dll丢失怎样修复,三种修复msvcr120.dll丢失的方法
- 【Azure 架构师学习笔记】- Azure Databricks (4) - 使用Azure Key Vault 管理ADB Secret
- 配电室智能监控系统设计及实现分析——安科瑞 顾烊宇
- 想要拿到中留服认证,需要出境多少天?180天/360天吗??
- C++:C/C++内存管理
- 一刀切转为精细化,门店如何进行「体检式」巡查(一)
- 鉴源实验室丨软件代码编码规则静态检测
- 微电网优化MATLAB:遗传算法(Genetic Algorithm,GA)求解微电网优化(提供MATLAB代码)