GoogleNet网络分析与demo实例
参考自?
- up主的b站链接:霹雳吧啦Wz的个人空间-霹雳吧啦Wz个人主页-哔哩哔哩视频
- 这位大佬的博客?Fun'_机器学习,pytorch图像分类,工具箱-CSDN博客
1. GoogLeNet网络详解
GoogLeNet在2014年由Google团队提出(与VGG网络同年,注意GoogLeNet中的L大写是为了致敬LeNet),斩获当年ImageNet竞赛中Classification Task (分类任务) 第一名。
原论文地址:深度学习面试题20:GoogLeNet(Inception V1) - 黎明程序员 - 博客园 (cnblogs.com)
GoogLeNet 的创新点:
1.引入了 Inception 结构(融合不同尺度的特征信息)
2.使用1x1的卷积核进行降维以及映射处理 (虽然VGG网络中也有,但该论文介绍的更详细)
3.添加两个辅助分类器帮助训练
4.丢弃全连接层,使用平均池化层(大大减少模型参数,除去两个辅助分类器,网络大小只有vgg的1/20)
?
inception 结构
传统的CNN结构如AlexNet、VggNet(下图)都是串联的结构,即将一系列的卷积层和池化层进行串联得到的结构

这里GoogleNet提出了并联的思路
将特征矩阵同时输入到多个分支进行处理,并将输出的特征矩阵按深度进行拼接,得到最终输出
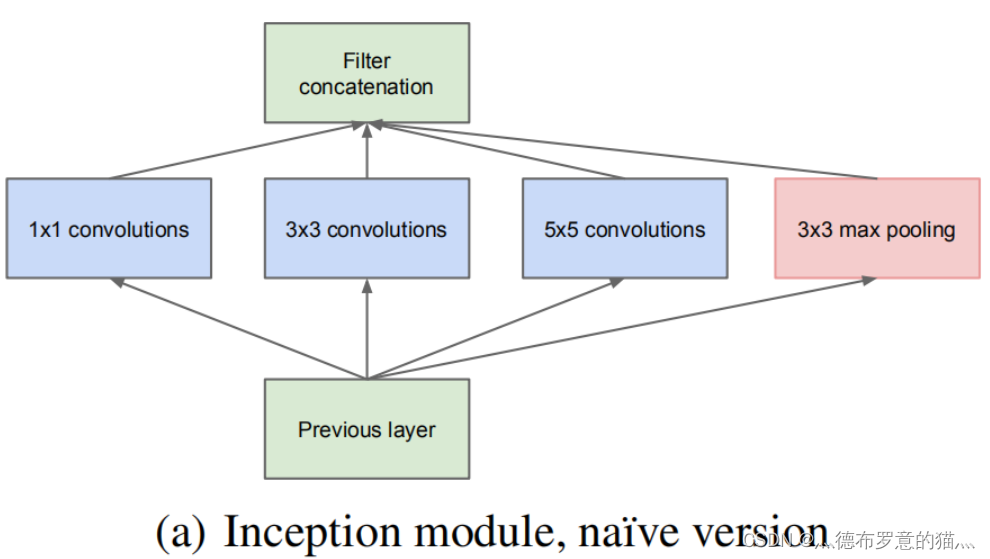
inception的作用:增加网络深度和宽度的同时减少参数
在 inception 的基础上,还可以加上降维功能的结构,如下图所示,在原始 inception 结构的基础上,在分支2,3,4上加入了卷积核大小为1x1的卷积层,目的是为了降维(减小深度),减少模型训练参数,减少计算量。

1×1卷积核的降维功能
同样是对一个深度为512的特征矩阵使用64个大小为5x5的卷积核进行卷积,不使用1x1卷积核进行降维的 话一共需要819200个参数,如果使用1x1卷积核进行降维一共需要50688个参数,明显少了很多。

辅助分类器(Auxiliary Classifier)
AlexNet 和 VGG 都只有1个输出层,GoogLeNet 有3个输出层,其中的两个是辅助分类层。
如下图所示,网络主干右边的 两个分支 就是 辅助分类器,其结构一模一样。
在训练模型时,将两个辅助分类器的损失乘以权重(论文中是0.3)加到网络的整体损失上,再进行反向传播。
?
辅助分类器的作用:
作用一:可以把他看做inception网络中的一个小细节,它确保了即便是隐藏单元和中间层也参与了特征计算,他们也能预测图片的类别,他在inception网络中起到一种调整的效果,并且能防止网络发生过拟合。
作用二:给定深度相对较大的网络,有效传播梯度反向通过所有层的能力是一个问题。通过将辅助分类器添加到这些中间层,可以期望较低阶段分类器的判别力。在训练期间,它们的损失以折扣权重(辅助分类器损失的权重是0.3)加到网络的整个损失上。
?

GoogLeNet 网络参数

pytorch搭建GoogLeNet
相比于 AlexNet 和 VggNet 只有卷积层和全连接层这两种结构,GoogLeNet多了 inception 和 辅助分类器(Auxiliary Classifier),而 inception 和 辅助分类器 也是由多个卷积层和全连接层组合的,因此在定义模型时可以将 卷积、inception 、辅助分类器定义成不同的类,调用时更加方便。
?
import torch.nn as nn
import torch
import torch.nn.functional as F
class GoogLeNet(nn.Module):
# 传入的参数中aux_logits=True表示训练过程用到辅助分类器,aux_logits=False表示验证过程不用辅助分类器
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# Inception结构
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1) # 按 channel 对四个分支拼接
# 辅助分类器
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
# 基础卷积层(卷积+ReLU)
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
train.py
实例化网络时的参数
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)
GoogLeNet的网络输出 loss 有三个部分,分别是主干输出loss、两个辅助分类器输出loss(权重0.3)
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
predict
# create model
model = GoogLeNet(num_classes=5, aux_logits=False)
# load model weights
model_weight_path = "./googleNet.pth"
但是在加载训练好的模型参数时,由于其中是包含有辅助分类器的,需要设置strict=False
missing_keys, unexpected_keys = model.load_state_dict(torch.load(model_weight_path), strict=False)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【教程】如何在苹果手机上查看系统文件?
- Mongo DB中的集合和数据库
- java天气预报查询管理系统(开题+源码)
- 单元测试计划、用例、报告、评审编制模板
- 击败 8 名人类规划师:清华团队提出强化学习的城市空间规划模型
- 平面灯阵中寻找最大正方形边界 - 华为机试真题题解
- 2.3_6 用信号量实现进程互斥、同步、前驱关系
- 统计学R语言实验7 方差分析
- 【信息安全原理】——入侵检测与网络欺骗(学习笔记)
- Github项目推荐-clone-voice