基于电商场景的高并发RocketMQ实战-Broker高并发消息写入、读写队列原理分析
🌈🌈🌈🌈🌈🌈🌈🌈
【11来了】文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁
Broker 如何实现高并发消息写入
Broker 对消息进行写磁盘是采用的 磁盘顺序写 ,写磁盘分为两种:顺序写和随机写,两种速度差别非常大!
Broker 通过顺序写磁盘,也就是在文件末尾不停追加内容,不需要进行寻址操作,大幅度 提高消息持久化存储的性能
这里消息写入的就是 Commitlog 文件!
磁盘顺序写和磁盘随机写的速度差距如下图:
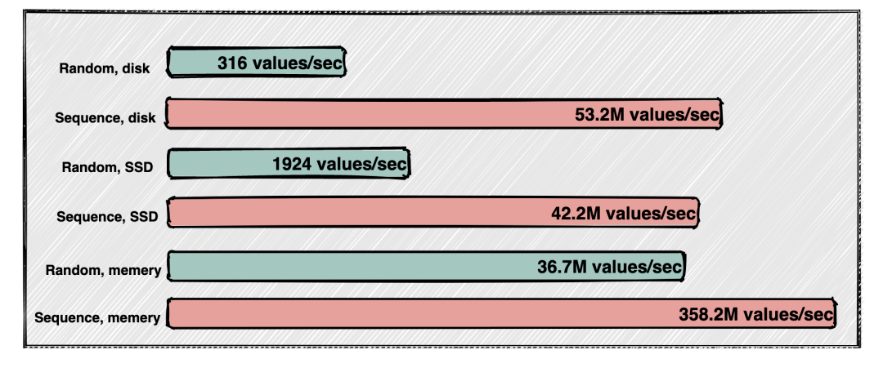
在将消息写入 Commitlog 文件之后,会有一个后台线程去监听 Commitlog 是否有数据写入,如果有就将新写入的数据写入到 write queue 中,这里写到 queue 中数据的内容就是消息在 Commitlog 中的偏移量 offset,写入 Commitlog 文件动作如下图黑色部分:
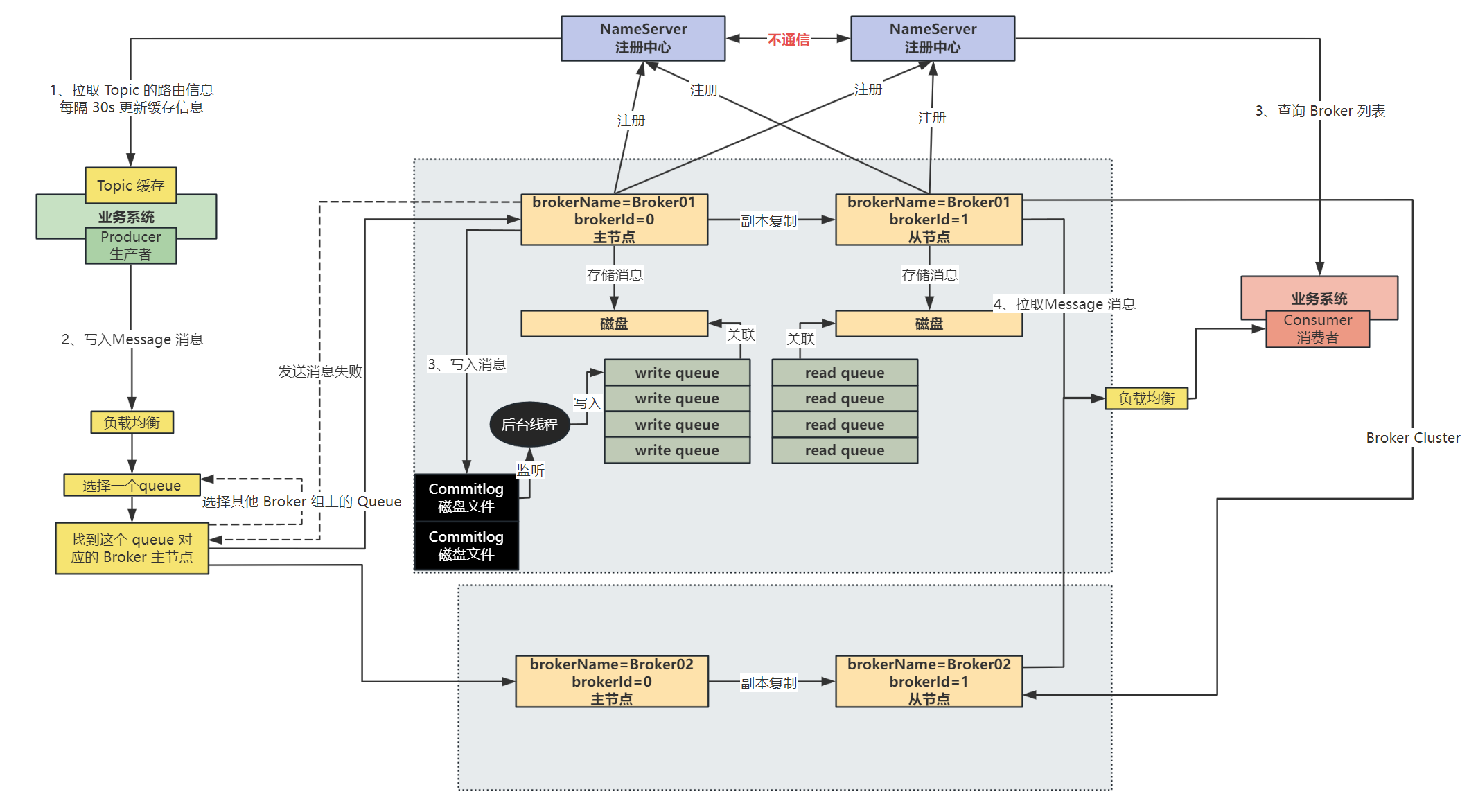
总结:
那么这里的高并发就是通过两点来保证:
- 通过
磁盘顺序写来提升性能 - 通过
异步将 Commitlog 文件写入 write queue(也就是 consume queue)中,保证不影响主流程速度
RocketMQ 的读写队列原理分析
RocketMQ 中是区分了 write queue 和 read queue,在物理层面只有 write queue 才对应磁盘上的 consumeQueue 物理文件,而 read queue 是一个虚的概念,并不是一个 read queue 也新创建一个磁盘文件
这两个参数是在 Topic 下进行设置的:
writeQueueNums:表示生产者在发送消息时,可以向几个队列进行发送readQueueNums:表示消费者在消费消息时,可以从多少个队列进行拉取
write queue 和 read queue 是一一对应的,如果 write queue 的数量多于 read queue,那么就会有一部分 write queue 中的消息永远不会被消费到;如果 read queue 的数量多于 write queue,那么就存在一部分 consumer 订阅的 read queue 中没有数据
设计 write queue 和 read queue 的意义:
使扩缩容的过程更加平滑,比如原来有 4 个 write queue 和 read queue,先将 write queue 缩容成 2 个,那么此时先不缩容读队列,等待与删除的两个读队列所对应的写队列中的旧数据被消费完毕之后,再对读队列进行缩容
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【精选】车辆违规实线变道检测系统:融合Gold-YOLO改进YOLOv8
- 【刷题篇】动态规划(八)
- Ubuntu 常用命令之 cal 命令用法介绍
- 原码、补码、反码
- Docker(八)高级网络配置
- VM虚拟机共享主机文件,解决再次打开文件不在了的情况
- 新成立的科技公司推广需要哪些设计准备—南京梵构广告
- 嵌入式学习第二章——C语言基础6
- Vue3的computed和watch
- 如何修复msvcp140_1.dll丢失问题,分享多种实测可靠的修复方法