【每日论文阅读】生成模型篇
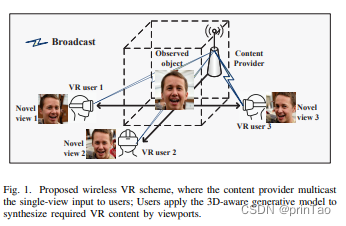
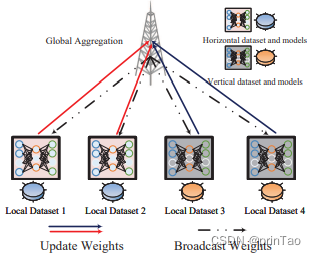
联邦多视图合成用于元宇宙
标题: Federated Multi-View Synthesizing for Metaverse
作者: Yiyu Guo; Zhijin Qin; Xiaoming Tao; Geoffrey Ye Li
摘要:
元宇宙有望提供沉浸式娱乐、教育和商务应用。然而,虚拟现实(VR)在无线网络上的传输是数据和计算密集型的,这使得引入满足严格的服务质量要求的新颖解决方案变得至关重要。随着边缘智能和深度学习的最近进展,我们开发了一个新颖的多视图合成框架,能够高效地为元宇宙中的无线内容传递提供计算、存储和通信资源。我们提出了一个三维(3D)感知的生成模型,该模型使用一组单视图图像。这些单视图图像被传输给一组有重叠视野的用户,避免了与传输切片或整个3D模型相比的大量内容传输。然后,我们提出了一个联合学习方法来保证高效的学习过程。通过利用大型潜在特征空间对垂直和水平数据样本进行特征化,可以改进训练性能,同时在联合学习过程中通过减少传输参数的数量可以实现低延迟通信。我们还提出了一个联合转移学习框架,以实现对不同目标领域的快速领域适应。模拟结果已经证明了我们提出的联合多视图合成框架对于VR内容交付的有效性。
快速推理
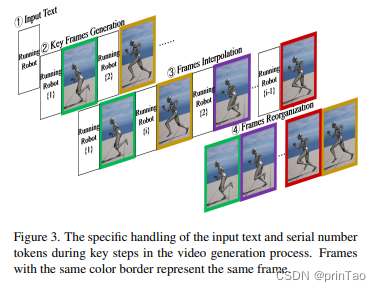
标题: FlashVideo: A Framework for Swift Inference in Text-to-Video Generation
作者: Bin Lei; le Chen; Caiwen Ding
在不断发展的机器学习领域中,视频生成已经通过基于自回归的变压器模型和扩散模型取得了显著的进步,这些模型以合成动态和真实的场景而出名。然而,即使对于生成短视频片段(如GIF)这样的任务,这些模型的推理时间往往都很长。本文介绍了FlashVideo,一个为迅速实现文本到视频生成而量身定制的新框架。FlashVideo是首个成功将RetNet架构应用于视频生成的例子,为该领域带来了独特的方法。通过利用基于RetNet的架构,FlashVideo将推理的时间复杂度从 O ( L 2 ) \mathcal{O}(L^2) O(L2)降低到 O ( L ) \mathcal{O}(L) O(L),在序列长度为 L L L的情况下,这极大地提高了推理速度。此外,我们采用了无冗余帧插值方式,提高了帧插值的效率。我们的全面实验表明,FlashVideo在效率方面比传统的基于自回归的Transformer模型提高了 × 9.17 \times9.17 ×9.17倍,其推理速度与BERT基础的变压器模型在同一个数量级。

? Pioneering adaptation of RetNet for video generation:
This paper marks the first successful adaptation of RetNet, originally an NLP-focused architecture, to the realmof video generation.
We address and overcome the unique challenges posed by RetNet’s relative position encoding,
setting a precedent in the field.
? Tailored training and inference frameworks for video
generation: We innovatively adapt RetNet for video generation by devising specialized training and inference
frameworks. Overcoming the limitations of RetNet’s relative position encoding, our frameworks enable the effective use of RetNet in video generation, breaking new
ground in the application of relative encoding models in
this field.
? Innovative redundant-free frame interpolation
method: We propose an effective Redundant-free Frame
Interpolation method that maintains high video quality
while optimizing computational resources.
? Empirical validation of FlashVideo’s efficiency and
quality: Through comprehensive experiments, we
demonstrate the efficiency and quality of FlashVideo.
These experiments validate our methods and showcase
FlashVideo’s enhanced performance in video generation
tasks.
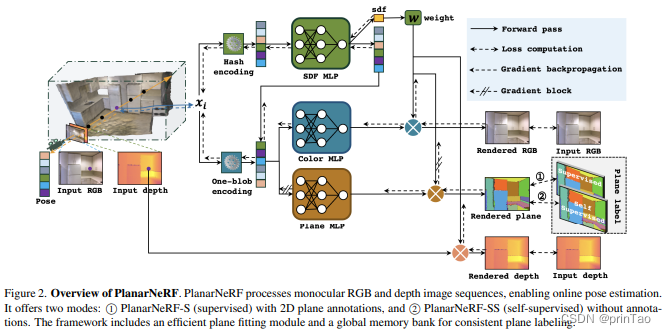
PlanarNeRF: NeRF + 在线学习(训练后修正)
标题: PlanarNeRF: Online Learning of Planar Primitives with Neural Radiance Fields
从视觉数据中识别出空间完整的平面图元是计算机视觉中的关键任务。而以往的方法大多受限于2D段恢复或简化3D结构,即使有大量的平面标注也是如此。我们提出了PlanarNeRF,一个能够通过在线学习检测密集3D平面的新颖框架。PlanarNeRF利用神经场表示法带来了三个主要贡献。首先,它利用并行的外观和几何知识,提高了3D平面检测的能力。其次,我们提出了一个轻量级的平面拟合模块,用于估计平面参数。第三,我们引入了一种新颖的全局存储银行结构和更新机制,以确保跨帧间的一致性。PlanarNeRF的灵活架构使其既可在2D监督下工作,也可在自我监督的解决方案中工作,在每种情况下,它都可以有效地从稀疏的训练信号中学习,大大提高了训练效率。通过大量实验,我们展示了PlanarNeRF在各种场景中的有效性和对已有工作的显著改进。

不同seed下内容一致的超分辨率
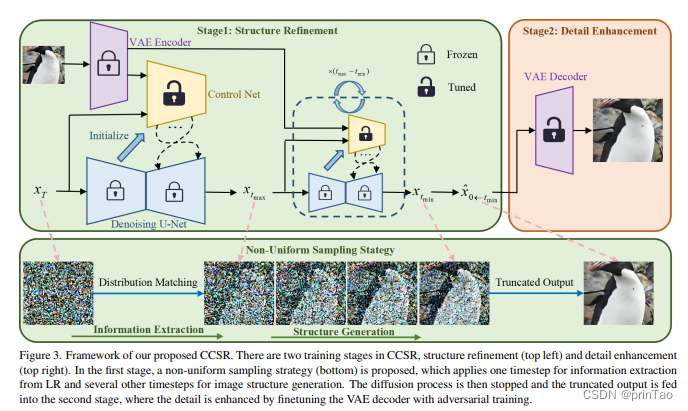
标题: Improving the Stability of Diffusion Models for Content Consistent Super-Resolution
摘要:
预训练的潜在扩散模型的生成先验已经证明有巨大的潜力来提高图像超分辨率(SR)结果的感知质量。遗憾的是,现有的基于扩散先验的SR方法遇到了一个共同的问题,即,它们倾向于为具有不同噪声样本的同一低分辨率图像生成相当不同的输出。这种随机性在文本到图像生成任务中是期望的,但对于需要很好地保存图像内容的SR任务而言,这是个问题。为了提高基于扩散先验的SR的稳定性,我们提出使用扩散模型来精细化图片结构,同时使用生成对抗性训练增强图像的细节。具体地说,我们提出了一个不均匀的时间步学习策略来训练一个紧凑型扩散网络,该网络具有高效稳定的效能,能够有效再现图像的主要结构,并通过对抗性训练对变分自动编码器(VAE)的预训练解码器进行微调以增强细节。大量实验表明,我们提出的这种方法,即内容一致的超分辨率(CCSR),可以显著减少基于扩散先验的SR的随机性,从而提高SR输出的内容一致性,并加速了图像生成过程。代码和模型可以在 {https://github.com/csslc/CCSR} 中找到。
贝叶斯统一自监督聚类
标题: A Bayesian Unification of Self-Supervised Clustering and Energy-Based Models
作者: Leven 大学
摘要:
自监督学习是利用大量未标注数据的热门且强大的方法,文献中已提出了各种训练目标。在此研究中,我们对最先进的自监督学习目标进行了贝叶斯分析,阐明了每个类别中潜在的概率图模型,并提出了一种从第一原理推导它们的标准化方法。这种分析也指出了将自我监督学习与基于似然的生成模型集成的自然方法。我们在基于聚类的自监督学习和能量模型领域内实例化了这一概念,引入了一个新颖的下界,这个下界经过证明能够可靠地惩罚最重要的失败模式。此外,这个新提出的下界使得无需进行停止梯度、动量编码器或专门的聚类层等不对称元素的情况下,就能对标准的主干架构进行训练-这些元素通常被引入以避免学习到琐碎的解决方案。我们通过在合成和现实世界数据(包括SVHN,CIFAR10和CIFAR100)上的实验,进一步证实了我们的理论成果,从而显示出我们的目标函数在聚类、生成和超出分布检测性能方面,能够以较大的优势超越现有的自我监督学习策略。我们还展示了GEDI可以集成到神经-符号框架中,以减轻推理捷径问题,并由于提高了分类性能,而学习到更高质量的符号表示。
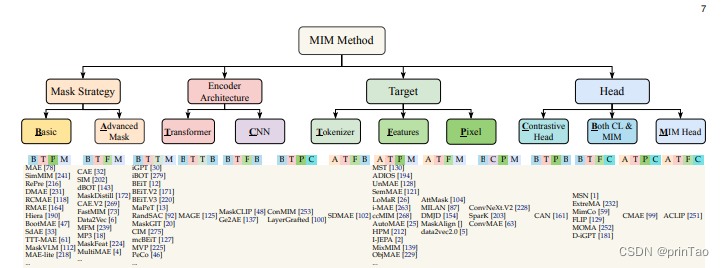
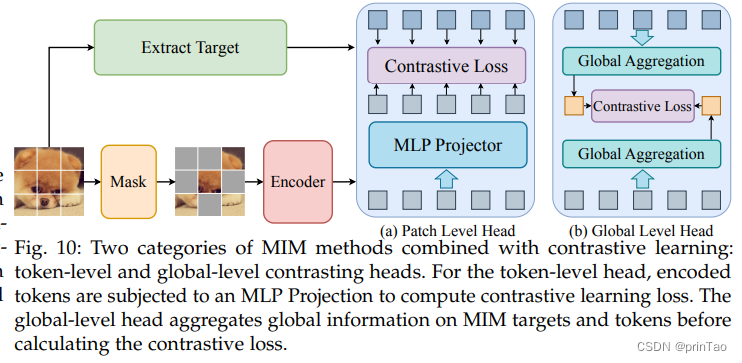
【综述】遮罩建模 在 自监督学习 各领域的应用
标题: Masked Modeling for Self-supervised Representation Learning on Vision and Beyond
随着深度学习的革命性进步,近年来,自监督学习因其出色的表示学习能力和对标注数据的低依赖性而越来越受到关注。在众多的自我监督技术中,掩模建模已成为一种独特的方法,它涉及预测在训练过程中被成比例掩模的原始数据。这种范式使深度模型能够学习强大的表示,并已在计算机视觉、自然语言处理等领域展现出出色的性能。在这篇综述中,我们将全面评述掩模建模框架及其方法论,详细阐述了掩模建模中的技术细节,包括多种掩模策略,恢复目标,网络结构等。接下来,我们系统性地探讨了其在众多领域的广泛应用。此外,我们还探讨了不同领域掩模建模方法的相同点和不同点。在论文的最后部分,我们通过讨论当前技术的限制,指出了推动掩模建模研究的几种可能途径。这篇综述的论文列表项目可在以下网址找到:\url{https://github.com/Lupin1998/Awesome-MIM}。


视频生成的轨迹控制
标题: TrailBlazer: Trajectory Control for Diffusion-Based Video Generation
在最近的文本到视频(T2V)生成方法中,实现合成视频的可控性往往是一个挑战。通常,这个问题通过提供边缘映射、深度映射或现有视频以进行修改的形式,进行低级别的帧控制来解决。然而,获取这样的引导可能需要大量的劳动力。本文聚焦于通过使用简单的边界框以各种方式引导主题,以增强视频合成中的可控性,而无需进行神经网络训练、微调、推理时间优化或使用预先存在的视频。我们的算法,名为TrailBlazer,基于一个预先训练的(T2V)模型构建,并且易于实现。主体通过我们提出的空间和时间注意力图编辑被一个边界框引导。此外,我们引入了关键帧的概念,允许主体轨迹和整体外观由一个移动的边界框以及相应的提示引导,无需提供详细的蒙版。该方法效率高,与基础预训练模型相比,额外的计算量微乎其微。尽管边界框引导的简单性,但产生的动作却出人意料的自然,包括当框体大小增加时,会出现包括透视和向虚拟相机移动的效果。
视频定位DINO:向开放词汇空间-时间视频定位迈进
标题: Video-GroundingDINO: Towards Open-Vocabulary Spatio-Temporal Video Grounding
视频定位的目标是在视频中定位与输入文字查询相对应的时空段。本文通过引入开放词汇时空视频定位任务,解决了当前视频定位方法的一个关键限制。与当前盛行的封闭集方法不同,由于训练数据有限和预先定义的词汇表,这些方法在处理开放词汇场景时遇到困难。我们的模型利用来自基础空间定位模型的预训练表征,使其能够有效地弥合自然语言和多样化视觉内容之间的语义鸿沟,同时在封闭集和开放词汇设置中实现强大的性能。我们的贡献包括一个新颖的时空视频定位模型,在多个数据集的封闭集评估中超越了最新的结果,并在开放词汇场景中展示出优越的性能。值得注意的是,该模型在VidSTG(声明性和疑问性)和HC-STVG(V1和V2)数据集的封闭集设置中胜过了最新的方法。此外,在HC-STVG V1和YouCook-Interactions的开放词汇评估中,我们的模型超越了最近最佳性能的模型,m_vIoU提高了4.26,准确度提高了1.83%,展示了其在处理各种语言和视觉概念以提高视频理解的有效性。我们的代码将在https://github.com/TalalWasim/Video-GroundingDINO上发布。
解决文本到3D生成中的分数蒸馏模式崩溃
标题: Taming Mode Collapse in Score Distillation for Text-to-3D Generation
Project page: https://vita-group.github.io/3D-Mode-Collapse/
尽管在文本到3D生成中,分数蒸馏显示出了显著的性能,但这种技术以其视图不一致性问题而臭名昭著,这也被称为 “Janus” 现象,其中生成的物体用多个前面的面欺骗每个视图。虽然一些项目通过分数去偏或提示工程处理这个问题表现出了有效性,但对于解释和处理这个问题的更严格的视角仍然不明确。在这篇论文中,我们揭示了现有的基于分数蒸馏的文本到3D生成框架在每个视图上独立地退化为最大似然寻求,并因此遭受模式崩溃问题,这在实践中表现为Janus现象。为了控制模式崩溃,我们通过在相应的变分目标中重新建立熵项来改善分数蒸馏,这被应用于渲染图像的分布。最大化熵鼓励生成的3D资产中不同视图的多样性,从而缓解Janus问题。基于这个新的目标,我们推导出一个新的3D分数蒸馏的更新规则,被称为熵分数蒸馏(ESD)。我们理论上揭示了,ESD可以通过仅采用分类器自由指导技巧在变分分数蒸馏基础上进行简化和实现。虽然这种方法极其直接,但我们的大量实验成功地证明,ESD可以有效地处理分数蒸馏中的Janus现象。

自动驾驶中的WoodScape运动分割 – 2023年CVPR全景视觉车牌挑战赛
标题: WoodScape Motion Segmentation for Autonomous Driving – CVPR 2023 OmniCV Workshop Challenge
摘要:
运动分割是自动驾驶中一项复杂却不可或缺的任务。由镜头的自我运动、鱼眼镜头中的径向畸变以及对时间一致性的需求带来的挑战使得这项任务愈加复杂,使传统和标准的卷积神经网络(CNN)方法的效果降低。大量的数据标记工作、多样且不常见场景的表现,以及广泛的数据收集要求,都突显出了用合成数据改善机器学习模型性能的重要性。为此,我们使用了由Parallel Domain开发的PD-WoodScape合成数据集,同时也使用了WoodScape鱼眼数据集。因此,我们提出了一个以自动驾驶为主题的WoodScape鱼眼运动分割挑战,这个挑战是作为2023年CVPR全向计算机视觉(OmniCV)研讨会的一部分进行的。作为首次关注鱼眼运动分割的比赛之一,我们旨在探索并评估在该领域使用合成数据的潜力和影响。在这篇论文中,我们对吸引了112支全球团队参与且共提交234个方案的比赛进行了详细的分析。这项研究描绘了运动分割任务中的复杂性,强调了鱼眼数据集的重要性,阐述了合成数据集的必要性以及他们带来的领域差距,为提出成功解决方案提供了基础蓝图。然后,我们深入探讨了基线实验和获胜方法的细节,并对其定性和定量结果进行评估,提供了有用的见解。
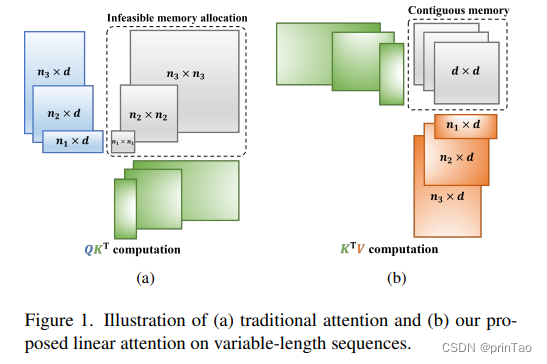
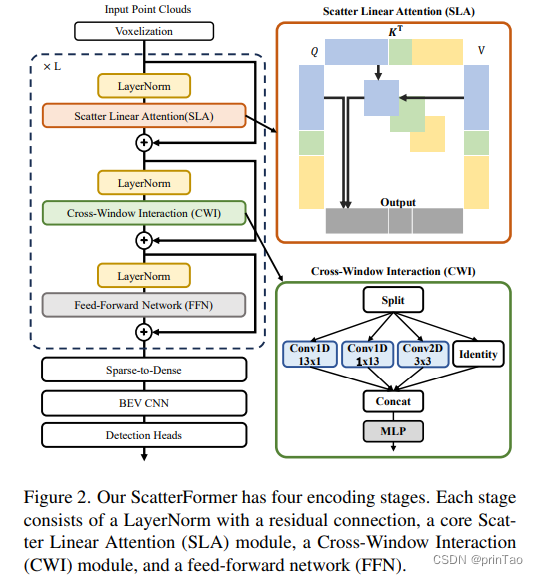
ScatterFormer:高效voxel Transformer与散射线性注意力
标题: ScatterFormer: Efficient Voxel Transformer with Scattered Linear Attention
基于窗口的变换器通过以更局部的方式捕获具有可承受的注意力计算的上下文感知表示,已经证明在大规模点云理解中具有强大的能力。然而,由于点云的稀疏性,每个窗口的体素数量差异很大。当前的方法将每个窗口中的体素分割成多个等大小的子集,这在排序和填充体素方面带来了高昂的开销,使得它们运行速度比基于稀疏卷积的方法要慢。在本文中,我们提出了ScatterFormer,这是我们所知的第一个可以直接在具有可变长度的体素集上执行注意力的算法。ScatterFormer的关键在于创新的散射线性注意力(SLA)模块,它利用线性注意力机制并行处理分散在不同窗口中的所有体素。通过利用GPU的分层计算单元和矩阵阻塞算法,我们将所提出的SLA模块的延迟减少到在适度的GPU上不到1毫秒。此外,我们开发了一个跨窗口交互模块,同时增强本地表示,并允许信息在窗口之间流动,消除了窗口移位的需要。我们提出的ScatterFormer在大规模的Waymo开放数据集上展示了73 mAP (L2)的效果,在NuScenes数据集上达到了70.5 NDS,运行速度优异,为28 FPS。代码可在https://github.com/skyhehe123/ScatterFormer获得。
Training the Adapter Modules. The backbone of the network, namely the feature extraction network and the sequential
network, is initially trained on a large dataset, with the exclusion of the adapter modules. In general, the efficacy of the
backbone in extracting useful features correlates strongly with the diversity and size of the dataset. Exclusively training
on a limited dataset inside a singular domain has the potential to result in overfitting, hence hindering the model’s ability
to effectively generalize across other domains. The following step of training involves incorporating a new task into the
model and subsequently optimizing the model’s performance on it. The new task may encompass a novel domain such
as a different language, a distinct font, or a new environmental configuration. The existing model has the capability to
be modified and applied to the new task while retaining knowledge of the past tasks. The prevention of forgetting is
accomplished by freezing the weights of the backbone and solely updating the weights of the corresponding adapter
modules during the second phase of training. The adapter modules can be conceptualized as a collection of task-specific
modules that are incorporated to enhance the efficiency of feature extraction for the novel job. During the process of
backpropagation, the data originating from the new domain is exclusively directed through its corresponding adapter
module, while the remaining adapter modules remain unaffected. Therefore, the performance of the model on different
domains is unaffected. Consequently, the model can accurately identify characters from several domains without
requiring the training of separate models for each domain. By freezing the weights of the backbone, the training process
benefits from a significant reduction in the number of parameters to be optimized. This leads to a faster training period
and mitigates the potential problem of overfitting. The utilization of information from the backbone by the adapters,
which have been trained on a substantial dataset to extract the most valuable characteristics, leads to a reduction in the
needed data size and number of training epochs for the adapter. Hence, our model exhibits a high degree of adaptability
in character recognition across many domains, resulting in efficient utilization of training time and resources.
边界注意力:在任何分辨率下学习寻找微弱边界
标题: Boundary Attention: Learning to Find Faint Boundaries at Any Resolution
Project website at boundaryattention.github.io: http://boundaryattention.github.io
我们提出了一个可微分模型,该模型明确地模拟了边界–包括轮廓,角落和交点–我们用一个新的机制来描述,我们称之为“边界注意力”。我们展示了即使在边界信号非常微弱或被噪声淹没的情况下,我们的模型仍能提供准确的结果。与之前寻找微弱边界的传统方法比,我们的模型有以下优点:它可微分;能够适应更大的图片;并能够自动适应图片各部分的适当的几何细节。与之前通过端到端的训练来查找边界的深度方法相比,它具有以下优点:提供亚像素的精度,对噪声的抵抗力更强,而且能够处理任何以其原始分辨率和方面比率的图像。
考虑3D可视性的泛化神经辐射场对交互双手的研究
标题: 3D Visibility-aware Generalizable Neural Radiance Fields for Interacting Hands
Accepted by AAAI-24
神经辐射场(NeRFs)对于场景,物体和人类来说是有希望的3D表示。然而,大多数现有的方法都需要多视角输入和每场景的训练,这限制了它们在实际生活中的应用。此外,当前的方法更偏重于单一主题案例,尚未解决涉及到严重的手部间遮挡和视角变化挑战的相互作用手部的场景。为了解决这些问题,本文提出了一种可泛化的可见性感知神经辐射野(VA-NeRF)框架用于交互手部。具体来说,有了交互手部图像作为输入,我们的可见性感知神经辐射场首先获取手部的基于网格的表示,并提取对应的几何和纹理特征。随后,引入一个能够利用查询点和网格顶点的可见性并且可以自适应地合并两只手的特征的特征融合模块,以实现在未见区域的特征恢复。此外,我们的可见性感知神经辐射野与一种新型的鉴别器在对抗学习范式中一同进行优化。与预测合成图像的单一真/假标签的传统鉴别器相比,所提出的鉴别器生成一个像素级的可见性图,为未见区域提供了细粒度的监督,鼓励可见性感知神经辐射场提高合成图像的视觉质量。在Interhand2.6M数据集的实验表明,我们提出的可见性感知NeRF显著优于传统的NeRF。项目页面: \url{https://github.com/XuanHuang0/VANeRF}。
在扩散模型中通过重用注意力图快速推理
标题: Fast Inference Through The Reuse Of Attention Maps In Diffusion Models
文本到图像的扩散模型在灵活和逼真的图像合成方面展示了前所未有的能力。然而,产生单一图像所需的迭代过程耗时且会导致高延迟,促使研究者进一步研究其效率。通常,改善延迟的方法有两种:(1)通过知识蒸馏(KD)训练更小的模型;和(2)采用ODE理论的技术以便使用更大的步长。相反,我们提出了一种不改变采样器步长的无需训练的方法。具体来说,我们发现反复计算注意力图是既耗时又冗余的;因此,我们提出在采样过程中结构化地重复使用注意力地图。我们初步的重复使用政策由最基本的ODE理论推动,该理论建议在采样过程的后期最适合重复使用。在指出这种理论方法的许多限制后,我们通过经验搜索更好的策略。与依赖KD的方法不同,我们的重复使用策略可以非常轻松地适应各种情况,以一种即插即用的方式进行。此外,当适用于稳定扩散-1.5时,我们的重复使用策略减少了延迟,对样本质量的影响最小。
无监督连续异常检测与对比学习提示
标题: Unsupervised Continual Anomaly Detection with Contrastively-learned Prompt
Accepted by AAAI 2024
在工业制造中,无监督异常检测(UAD)的增量训练是至关重要的,因为无法预测的缺陷使得获得足够的标记数据变得不可能。然而,连续学习方法主要依赖于监督注释,而在UAD的应用却受限于监督注释的缺乏。当前的UAD方法为不同的类别顺序地训练单独的模型,导致了灾难性的遗忘和重大的计算负担。为了解决这个问题,我们提出了一个名为UCAD的新型无监督连续异常检测框架,该框架通过对比学习的提示来为UAD提供连续学习的能力。在我们提出的UCAD中,我们通过利用一个简洁的关键提示知识库,设计了一个连续提示模块(CPM),通过任务特定的“正常”知识来指导任务不变“异常”模型的预测。此外,我们设计了基于结构的对比学习(SCL),与分割任何模型(SAM)结合,以改进提示学习和异常分割结果。具体来说,通过将SAM的掩蔽视为结构,我们将同一掩蔽内的特征拉近,并将其他特征远离以提供一般的特征表示。我们进行了全面的实验,并在无监督连续异常检测和分割上设立了基准,证明我们的方法比异常检测方法(即使有彩排训练)要显著优秀。代码将在https://github.com/shirowalker/UCAD上可用。
DTBS:用于夜间语义分割领域适应的双教师双向自我训练
标题: DTBS: Dual-Teacher Bi-directional Self-training for Domain Adaptation in Nighttime Semantic Segmentation
由于照明不足和注释困难,夜间条件对自动驾驶车辆感知系统构成了重大挑战。无监督领域适应(UDA)已被广泛应用于此类图像的语义分割,从常规条件适应到目标夜间条件领域。自我训练(ST)是UDA中的一种模式,其中运用了动量师从模式进行伪标签预测,但存在确认偏误问题。因为来自单个教师的单向知识转移不足以适应大范围的领域转移。为缓解这个问题,我们建议通过逐步考虑风格影响和照明变化来缓解领域间隙。因此,我们引入了一个一阶双教师双向自训练(DTBS)框架,用于平滑的知识转移和反馈。基于两个师从模型,我们提出了一种新的流程,分别解耦风格和照明转移。此外,我们提出了一个新的重新加权指数移动平均数(EMA)来整合风格和照明因素的知识,并向学生模型提供反馈。这样,我们的方法可以嵌入到其他的UDA方法中,以增强其性能。例如,Cityscapes到ACDC夜间任务的结果为53.8mIoU(%),相较之前最先进的方法提高了+5%。代码在\网址{https://github.com/hf618/DTBS}可获取。
深度辨别度量学习用于单眼3D物体检测
标题: Depth-discriminative Metric Learning for Monocular 3D Object Detection
Accepted at NeurIPS 2023
单目三维物体检测由于在RGB图像中缺乏深度信息,因此面临着重大挑战。许多现有的方法试图通过分配额外的参数用于物体深度估计,或利用额外的模块或数据来提高物体深度估计的性能。相比之下,我们引入了一种新的度量学习方案,这种方案鼓励模型提取与视觉属性无关的深度区分性特征,而无需增加推理时间和模型大小。我们的方法利用保持距离的函数来组织与地面真实物体深度关联的特征空间流形。我们提出的(K,B,eps)-拟等距损失使用预定的成对距离限制作为指导,调整物体描述符之间的距离,而不会破坏自然特征流形的非线性。此外,我们引入了一个辅助头部,用于物体的深度估计,提高了深度质量,同时维持了推理时间。通过实验显示了我们方法的广泛应用性,这些实验显示,当我们的方法集成到各种基线中时,整体性能有所提高。结果显示,我们的方法在KITTI和Waymo上,平均分别提高了23.51%和5.78%的各种基线的性能。
城市脉搏:利用街景时间序列进行城市变化的细粒度评估
标题: CityPulse: Fine-Grained Assessment of Urban Change with Street View Time Series
Accepted by AAAI 2024
城市转变对个人和整个社区都产生深远的社会影响。准确评估这些转变对于理解其根本原因并确保可持续的城市规划至关重要。传统的测量方式经常在空间和时间的粒度上遇到限制,无法捕捉到实时的物理变化。而街景图像能够从行人视角捕捉到城市空间的脉搏,作为一种高清晰度、最新和直接的视觉代理来审视城市的变化。我们整理了迄今为止最大的街景时间序列数据集,并提出了一种端到端的变化检测模型来有效捕捉大规模建筑环境的物理变化。我们通过与先前文献的基准比较并在整个城市级别实施它来展示我们提出的方法的有效性。我们的方法有可能补充现有的数据集并作为评估城市变化的细粒度和准确评估的补充。
Noise-NeRF:使用可训练的噪声在神经辐射场中隐藏信息
标题: Noise-NeRF: Hide Information in Neural Radiance Fields using Trainable Noise
神经辐射场(NeRF)被提出作为一种创新的3D表示方法。虽然引起了众多关注,但NeRF面临诸如信息保密性和安全性的关键问题。隐写术是一种用于保护信息安全的技术,通过将信息嵌入另一个对象中进行隐藏。目前,关于NeRF隐写术的研究较少,主要面临着隐写质量低、模型权重损伤以及隐写信息量有限的挑战。本文提出了一种基于可训练噪声的新颖NeRF隐写方法:Noise-NeRF。此外,我们还提出了自适应像素选择策略和像素扰动策略来提高隐写质量和效率。在开源数据集上的广泛实验表明,Noise-NeRF在隐写质量和渲染质量方面都提供了最先进的性能,以及在超分辨率图像隐写中的有效性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!