数据在内存中的存储之大小端
今天也是努力学编程,敲代码的一天!
1.什么是大小端
其实超过一个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为大端字节序
存储和小端字节序存储,下面是具体的概念:
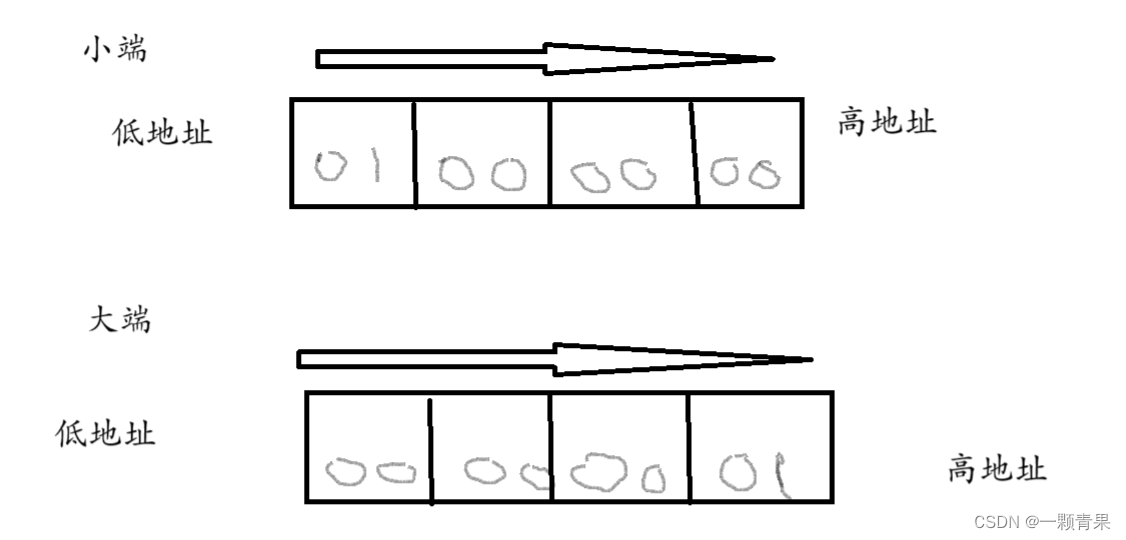
🐶大端(存储)模式:
是指数据的低位字节内容保存在内存的高地址处,而数据的高位字节内容,保存在内存的低地址处。
🐶小端(存储)模式:
是指数据的低位字节内容保存在内存的低地址处,而数据的高位字节内容,保存在内存的高地址处
上述概念需要记住,方便分辨大小端。
2.为什么要有大小端
这是因为在C语言中除了8 bit 的 char 之外,还有16 bit 的 short 型32 bit 的 long 型(要看具体的编译器),另外,对位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个16bit的short型x,在内存中的地址为x010,的值为x1122,那么x11为高字节ex22为低字节。
👻对于大端模式,就将x11 放在低地址中,即x1 中x22放在高地址中,即x011中。
👻小端模式,刚好相反。
我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
?🐰再举个例子,对于整数1,他的二进制是00000000 00000000 00000000 00000001
又因为在展示内存中的数据时是以16进制为模式的,所以改为16进制 00 00 00 01
很明显每两个数是一个字节,
3.该如何确定当前编译环境是大端还是小端呢
1??.共用体确定大小端
#include<stdio.h>
union u
{
?? ?char a;
?? ?int b;
};
int QueryEnd1()
{
?? ?union u end;
?? ?end.b =1;
?? ??? ?return end.a;
}
int main()
{
?? ?int i = QueryEnd1();
?? ?if (i == 1)
?? ?{
?? ??? ?printf("小端模式\n");
?? ?}
?? ?else
?? ?{
?? ??? ?printf("大端模式\n");
?? ?}?? ?return 0;
}
2??.指针确定大小端?
int QueryEnd1()
{
int* a = NULL;
int b = 1;
a = &b;
return *((char*)a);
}
int main()
{
int i = QueryEnd1();
if (i == 1)
{
printf("小端模式\n");
}
else
{
printf("大端模式\n");
}
return 0;
}ok,今天的分享就到这里啦,感觉有用的话,就点个赞支持一下吧!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!