【Linux系统编程二十六】:线程控制与线程特性(Linux中线程库/线程创建/线程退出/线程等待)
【Linux系统编程二十六】:线程控制与线程特性
一.Linux线程库pthread
在Linux中,是没有明确的线程概念的,因为在内核里线程是用进程的内核数据结构模拟实现的,只有轻量级进程的概念。所以在内核里它没有直接控制线程的接口,只有通过轻量级进程的系统调用:

简单介绍一下该系统调用,第一个参数就是一个函数指针,是该线程要执行的方法函数。第二个参数是一个栈指针,指向的是一块栈空间。至于为什么要栈,后面会讲到。
而我们用户只想要线程,不想要所谓的轻量级进程,所以就有人在应用层给我封装了一个线程库pthread。
它内部就是封装了调用轻量级进程系统调用接口,然后给我封装出一批创建线程,退出线程,等待线程的接口。
所以我们想使用Linux中的线程,需要使用第三方pthread库。

1.线程控制块
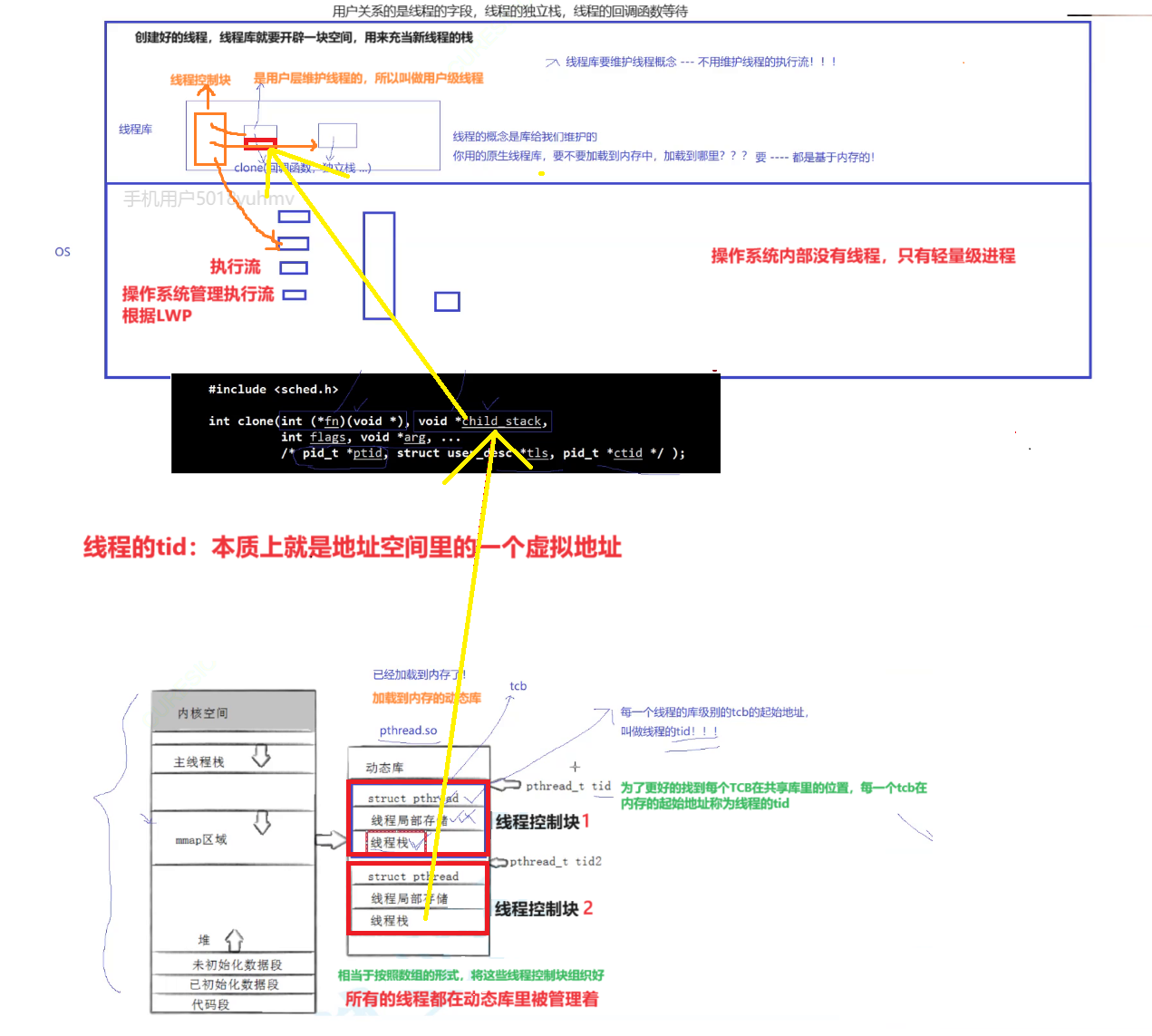
我们要理解的是,操作系统内部是没有线程的,只有轻量级进程,线程是在用户层创建出来的。是用户层维护线程的,所以叫做用户级线程。
因为库是共享的,你在库中可以创建线程,我也可以创建线程,所以线程库中会存在很多的线程,这些线程需不需要管理呢?当然需要!
所以线程库需要维护线程,要管理线程—先描述,再组织。
在线程库中其实是存在一个叫做线程控制块的结构体,它就是用来描述线程的各种属性比如线程的字段,线程的独立栈,线程的回调函数等。
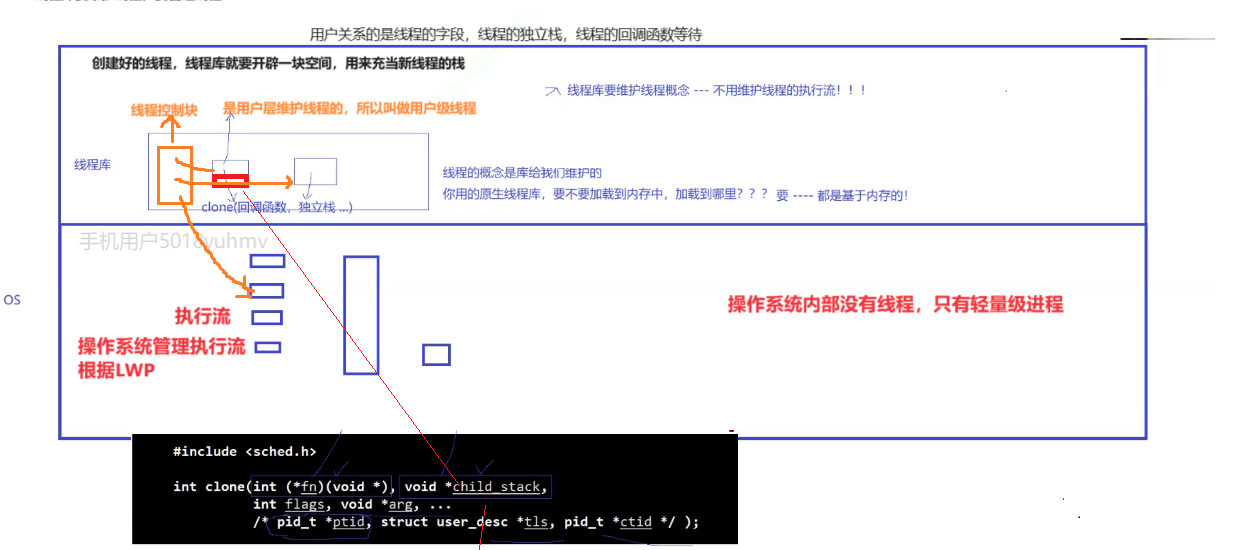
创建一个线程,线程库就需要开辟一块空间,用来创建线程的TCB。
这是在用户层面,而线程库使用时,是需要加载到内存面的,在内核层面,没有所谓的TCB(线程控制块),它只有一个执行流,也就是轻量级进程,对于操作系统来说,它管理的是执行流。每一个线程在内核里都有唯一的LWP。
2.线程tid
根据上面的理解,我们知道在用户层面,线程库会为线程创建线程控制块TCB。那么这么多线程,用户是如何区别这些线程的呢?每一个线程在用户层都会存在一个tid,用来区别不同线程的。根据动态库的学习,我们知道,在链接时需要将动态库加载到内存的共享区里。
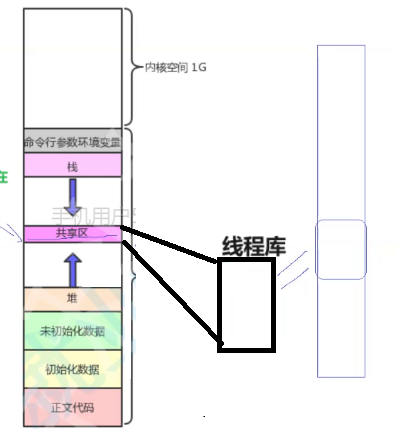
而线程库链接时也需要加载到内存的共享区里。
线程库里存在很多描述线程的线程控制块TCB。线程库按照数组的方式将各个线程控制块管理起来。所有的线程都在动态库里被管理着。
而这些线程控制块在共享区里的起始地址就就是该线程的tid。
因为为了更好的找到每个TCB在共享库里的位置,每一个TCB在内存的起始地址就称为线程的tid
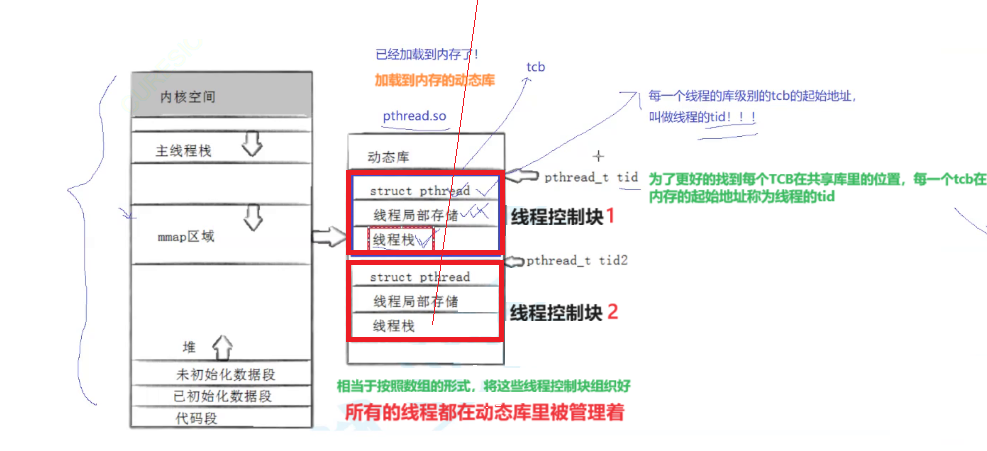

所以线程的tid本质就是共享区内存的一个虚拟地址。
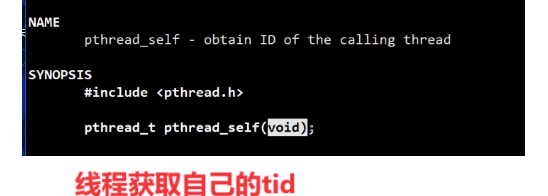
线程获取自己的tid,系统调用接口:
3.线程栈
线程控制块里还存在一个线程栈,这是什么,又为什么呢?
因为每一个线程都是一个独立的执行流,各自在不同的地址空间执行代码,也就是执行不同的函数。而函数里难免会需要各种临时变量,或者调用其他函数,传递形参等,这些都需要栈空间存储。所以每一个线程创建时,都需要一块栈空间,用来维护各自函数里临时变量。
而主线程用的是地址空间里的栈空间。其他线程用的都是共享区里开辟的空间。在线程创建时,首先在上层线程库会为新线程创建一堆数据结构叫做线程控制块,里面维护着该线程的tid,该线程的栈空间等。上层将tcb创建好后,在内核层面就会形成对应的执行流,然后调用系统调用clone,将线程的栈空间,传递给child_stack。

二.线程控制
1.线程创建
main函数执行流我们称为是主线程,主线程创建的线程我们称为新线程。

1.pthread_create()是用来创建线程的。它会产生一个线程id,用来标识该线程的唯一性。线程的后续操作,都是根据该线程的id来操作线程。该id的本质就是共享区内存的虚拟地址。(就是线程控制块TCB在共享区内存的起始地址)
2.pthread_t是操作系统提供的数据类型,类似于int
3.第一个参数是用作输出型参数的,它是将创建的线程的tid给带出来。
4.第二个参数,是用来控制线程的属性,不用的情况下,置nullptr就可以。
5.第三个参数是一个函数指针,它是该线程要执行的方法函数。该函数的返回值和参数都是void类型。
6.第四个参数,是新线程执行的方法函数的参数。执行线程函数也可能需要参数,所以这个参数,就是主线程传给新线程的参数。主线程想让子线程知道什么,就可以通过该参数传递给子线程。该参数是一个void类型,不过注意不仅可以传普通类型过去还可以传对象过去。
7.
注意在编译的时候需要链接线程库。

创建的线程和主线程是如何区分的呢?
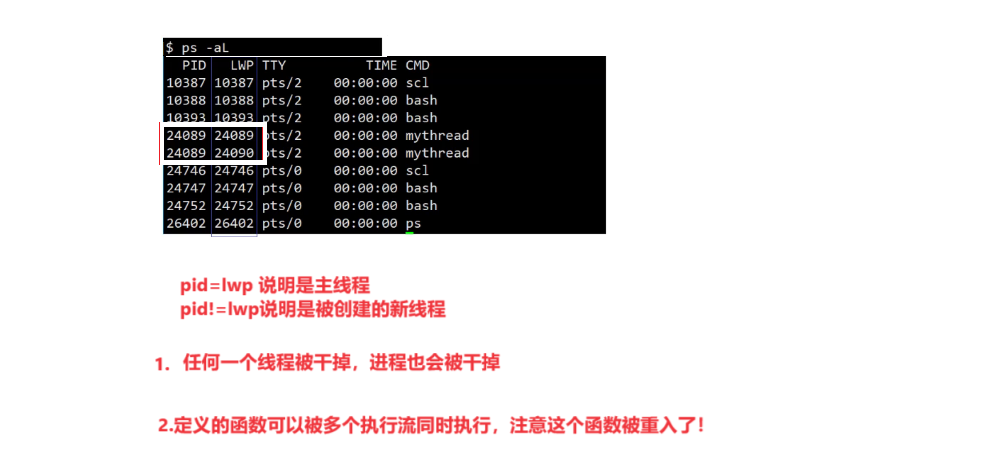
根据LWP来区别,或者根据它们的tid来区别。
任何一个线程被干掉,进程就会被干掉,因为线程就是进程内部的一个执行分支。
2.线程退出
线程执行的函数返回了,就代表线程退出。
线程退出有两种方式,一种是函数之间return返回退出。
一种是使用系统调用pthread_exit()来退出。
注意不能使用exit()接口,它是用来进程退出的:

注意线程退出,返回的是void*类型,如果没有什么可以退出的,就直接返回nullptr;
形参可以接收一个对象指针,那么最后函数返回时也可以返回一个对象。

3.线程等待
主线程创建新线程,也需要观看这个新线程,需要等待新线程。不然会出现类似于"僵尸进程"。导致资源泄露。并且有时主线程也需要获取创建的线程的一些处理结果。所以需要主线程最后退出。

1.pthread_join()是用来进程等待的。
2.第一个参数就是线程的tid,创建线程时,会将线程的tid给带出来。
3.第二个参数retval是一个输出型参数,是用来将线程执行函数结果给带出来,因为线程执行的函数的返回值是void类型,要想将该类型带出来,必须使用指针类型,也就是void *类型。
4.主线程在等待时,默认是阻塞等待,如果线程不退出,那么主线程就会一直等待。
5.线程退出时,主线程join等待不需要考虑异常情况,因为做不到,只有进程才可以做到。
6.一般来说,主线程退出,其他线程也会退出,但是如果使用pthread_exit(主线程tid),其他线程可能不会退出。
主线程还可以取消新线程(该线程已经被创建完毕)
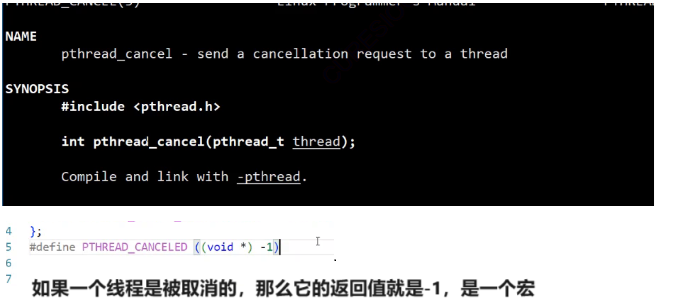
线程如果被取消,那么它执行的函数返回值就会为-1。
三.线程的特性
因为在内核里没有线程的具体实现,线程是在用户层利用第三方库实现的,所以在内核中是如何区分线程和进程的呢?在内核中是没有线程和进程概念,它们都是轻量级进程,而每一个轻量级进程都有唯一标识它的LWP(Light Weight Process)。
而与之对应的用户层是真正实现了线程,所以叫做用户级线程,每一个线程都具有自己的tid。
所以这样对应起来,真正的线程是具有两部分构成的,一个是上层用户级线程,一个是下层内核级线程。用户级执行流:内核LWP=1:1
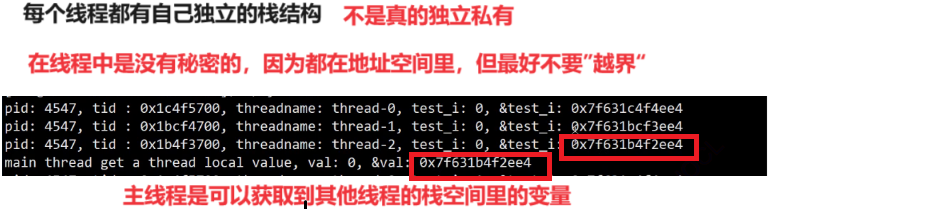
1.独立栈
每一个线程都是具有独立的栈结构的,当不同的线程调用同一个函数时,虽然是同一个函数,但是在不同的函数栈帧中。所以同一个变量,是在不同的栈帧中开辟的,地址也就不会相同。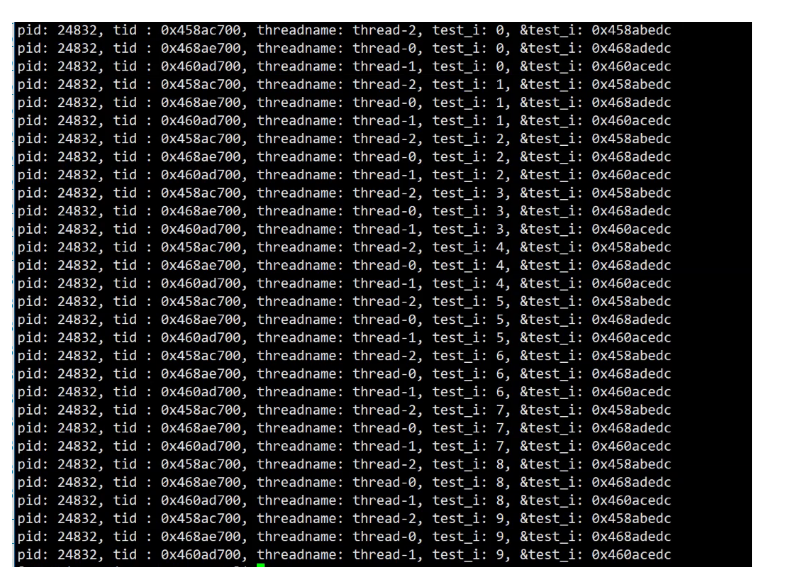
但这个独立是相对独立,不是真的独立私有,其他线程想要访问你的栈也是可以访问到的,因为这些线程都是在同一个地址空间上运行,所以在线程中是没有秘密可言的,只不过线程之间最好不要越界访问。
2.局部存储
全局变量是每一个线程都可以访问的,就相当于一个共享资源。访问到的都是同一个。

那么有没有这样的变量,它是线程独有的,但又是全局的呢?也就是线程想要一个私有的全局变量呢?
线程的局部存储可以满足这样的条件。什么叫局部存储呢?

在线程控制块里,存储着一个叫线程局部存储的对象。它也是一块空间,是在共享区内存提前申请好的,当线程创建时,就已经存在。也就是每一个线程都会有一个局部存储,它可以用来定义全局变量,但这个全局变量又只有该线程能访问。
可以将线程自己不变的属性,且频繁调用的,放进去。然后再交给线程。
可能有人会疑惑,为什么要有局部存储,为什么不在线程函数内部直接设置一个临时变量不就好啦。
这样做的原因很简单,效率高,不需要频繁的创建变量,不需要传递参数也可以使用。
3.线程可分离
主线程创建新线程后,有两种情况,一种是等待新线程,一种是不等待线程。
等待线程,可能需要获取新线程的返回结果。
不等待线程,说明不关心新线程的返回结果。

但是你又说了,不等待线程会造成资源泄露。
有一种方法可以让主线程,不等待新线程,也不会造成资源泄露:线程分离
也就是主线程与新线程分离后,主线程不关心新线程的返回结果,新线程退出后会自动释放资源。
int pthread_detach(pthread_t thread);
//thread就是线程的tid
线程分离有两种方法:
①主线程强制分离
在主线程里,利用创建线程获取得到的tid,来分离新线程。
②新线程主动分离
在新线程执行的函数里,利用(pthread_self()获取自己的tid来分离。

【注意】
①一个线程被分离后,主线程就不能再等待它了。如果该线程分离后,主线程又等待它,这样会报错。
②分离线程,说明主线程是不关心该线程的返回结果,也就是不想等待该线程,但还是要保证主线程,最后退出。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mysql数据库备份还原
- nuc980 打包烧录系统镜像文件
- 静态HTTP:如何优化性能
- openGauss学习笔记-196 openGauss 数据库运维-常见故障定位案例-强制结束指定的问题会话
- 从零开始学Docker-Day1
- 阿里开发手册 嵩山版-编程规约 (一)命名规范
- 计算机毕业设计 基于Java的国产动漫网站的设计与实现 Java实战项目 附源码+文档+视频讲解
- 高精度加法和高精度减法算法
- odoo17 | 创建一个新应用程序
- 前端面试题-html5新增特性有哪些