Kubernetes 学习总结(41)—— 云原生容器网络详解
背景
随着网络技术的发展,网络的虚拟化程度越来越高,特别是云原生网络,叠加了物理网络、虚机网络和容器网络,数据包在网络 OSI 七层网络模型、TCP/IP 五层网络模型的不同网络层进行封包、转发和解包。网络数据包跨主机网络、容器网络、虚机网络和物理网络到达对端,期间必然带来网络性能损耗。
场景
(1)低延时交易场景
证券交易系统具有交易时间相对集中、交易指令和数据密集的特点,对交易系统处理速度具有极高的要求。近年来,全球各大交易所都在不断对交易系统升级改造,其中“低时延”成为各大交易所竞争的核心,交易系统延时竞争已经进入微秒量级。用户通过客户端委托交易下单经过交易所外的交易软件、主机网络和物理网络,进入交易所内软硬件网络撮合交易,然后将委托回报和成交回报通过反向网络数据链路发送给用户。
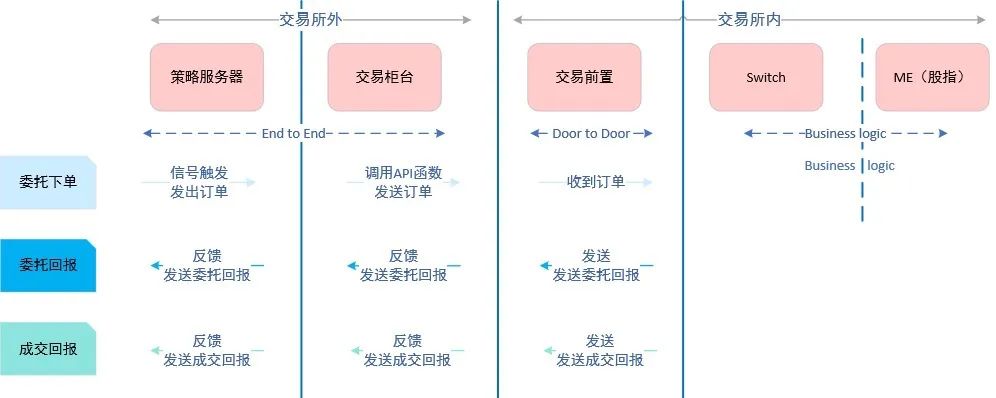
(2)视频和云游戏等流媒体场景
在多媒体领域,直播流媒体、在线视频和云游戏等场景都存在对网络性能、传输速度有极高的要求。单纯从软件或者操作系统虚拟化出来的网络设备,无法达到网络收发处理、转发和传输的性能要求,以及保证低丢包率和低时延。
(3)流量隔离场景
在银行、证券、保险等金融行业,因金融政策、监管政策的要求,需要实现对管理流量、存储流量和业务流量进行隔离,做到网络运维管理,数据存储、数据备份和数据交互同步与业务流量分离,保障数据交互同步与正常网络访问的相互隔离,提高网络并发能力和降低网络延迟。
以上应用场景,无法通过单纯的应用网络、主机网络和硬件网络来解决微妙级低延时要求。如何提升云原生时代整体网络性能,降低网络时延呢?我们可以从传统网络和容器网络路径分析哪些可以优化的点或片段,针对这些点或片段提供可行的容器网络加速方案。
术语
CNI:Container Network Interface,容器运行时和网络实现之间的容器网络 API 接口。
IPAM:专门用于管理容器的IP地址管理,包含对容器分配 IP 地址、网关、路由和 DNS 等管理。
SR-IOV:Single Root I/O Virtualization,单根虚拟化,允许在虚拟机之间高效共享 PCIe 设备。
PF:Physical Function,包含 SR-IOV 功能结构主要用于 SR-IOV 功能管理。PF 通过分配 VF 来配置和管理 SR-IOV 功能。
VF:Virtual Function,轻量级 PCIE 功能(I/O 处理)的 PCIE 设备,每个VF 都是通过 PF 来生成管理,VF 的具体数量限制受限于 PCIE 设备、自身配置和驱动程序的支持。
RDMA:Remote Direct Memory Access,远程直接内存访问,将网络协议栈下沉到网卡硬件,网卡硬件收发包并进行协议栈封装和解析,然后将数据存放到指定内存地址,而不需要 CPU 干预。
DPDK:Data Plane Development Kit,数据平面开发套件,工作在用户态用于快速数据包处理,使用轮询 Polling 来处理数据包。
VPP:Vector Packet Processing,矢量数据包处理,工作在用户态的高性能数据包处理协议栈。通常与 DPDK 结合使用,提供多种收发数据包、交换和路由能力。
VCL:VPP Communication Library,高性能 VPP 数据包处理协议栈类库。
eBPF:Extended Berkeley Packet Filter,可扩展的伯克利包过滤器,在操作系统内核中运行沙盒程序,安全有效地扩展内核功能,而不需要更改内核源代码或加载内核模块。主要提供主机网络通信、安全管理和可观测的能力。
Cilium:基于 eBPF 技术实现的网络插件,用于提供网络、安全和观测容器工作负载之间的云原生网络。
XDP:eXpress Data Path,快速数据路径,XDP 是 Linux 网络处理流程中的一个 eBPF 钩子,能够挂载 eBPF 程序,能够在网络数据包到达网卡驱动层时对其进行处理。
传统网络数据包处理路径
在传统的 Linux 主机网络中,源应用程序通过系统调用与内核中 Socket 层进行网络数据交互,网络数据包分别依次进入?Socket 层、传输层、网络层和网络接口层,最后通过网卡驱动、CPU 和物理网卡到达目标应用程序所在的物理网卡,期间 CPU 和网卡驱动频繁进行硬中断、软中断与轮询来通知操作系统进行收发收据包。

接下来,我们具体分析一下网络数据包发送流程:首先,在用户态网络协议栈中,源应用程序会调用 Socket 发送数据包的接口,数据包从用户态进入到内核态中的?Socket 层,Socket 层会将应用层数据拷贝到 Socket 发送缓冲区中。然后,在内核态网络协议栈中,从 Socket 发送缓冲区中取出数据包,并按照 TCP/IP 协议栈从上到下逐层处理。如果使用的是 TCP 传输协议发送数据,那么会在传输层增加 TCP 包头,然后交给网络层,网络层会给数据包增加IP包,然后通过查询路由表确认下一跳的 IP,并按照 MTU 大小进行分片。分片后的网络包,就会被送到网络接口层,通过 ARP 协议获得下一跳的 MAC 地址,然后增加帧头和帧尾,放到发包队列中。最后,等队列准备就绪后,会触发软中断告诉网卡驱动程序有新的网络包需要发送,最后驱动程序通过?DMA,从发包队列中读取网络包,将其放入到硬件网卡的队列中,随后在物理网络中,物理网卡再将它发送出去,通过交换机或者网桥等到达目标应用所在主机物理网卡。
网络数据包接收流程与网络数据包发送的流程正好相反,其中,发送流程执行数据包的封包处理,而接收过程则执行数据包的解包处理。基于以上网络数据包通信和处理过程,在高性能网络通信场景下,频繁的网络收发数据包,数据包在内核中不同网络路协议栈之间的封装和解包处理,以及软硬件中断与轮询,导致网络通信延迟较高。
容器网络数据包处理路径
在容器网络环境下,网络数据包的处理流程较传统网络数据包的处理路径更加长,网络环境更加复杂。容器网络数据包的发送和接收经过七层,分别是:容器用户态编程协议、容器内核态网络协议栈、容器与主机网卡对、主机用户态容器网络 CNI、虚拟主机网络、主机网卡驱动,主机网卡和物理网络。
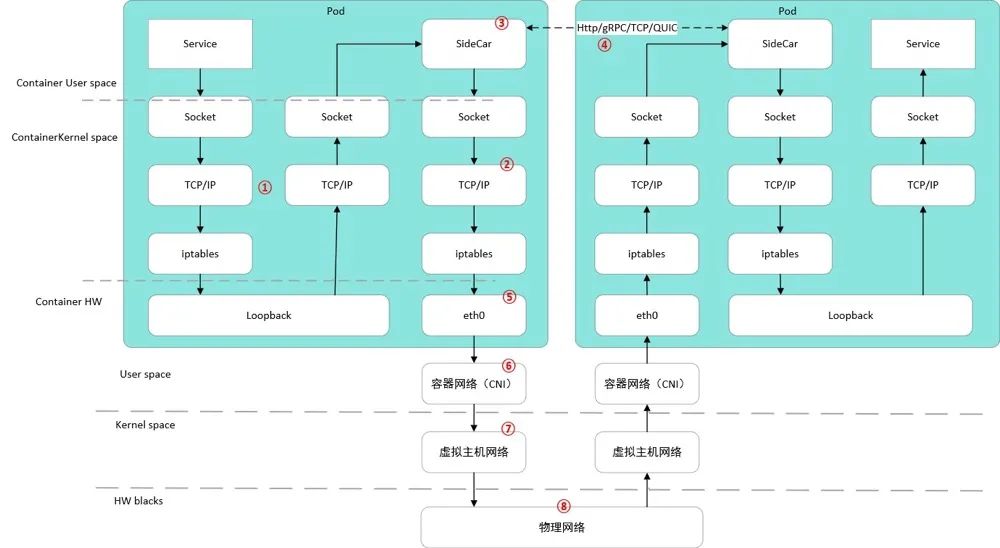
相对于普通的容器化应用,微服务服务网格应用的容器网络最具代表性,主要多了边车 Sidecar 对应用的流量劫持和转发,其他的流量数据包处理过程与普通应用一样。下面以服务网格中应用与边车 Sidecar 之间的网络数据包发送和接收路径为例说明。
容器源应用程序访问目标应用程序的数据路径,在容器内与传统网络数据包收发处理流程类似,但是会增加容器主机网络路径。容器内源应用程序通过 Socket 调用,网络数据包由容器用户态进入容器内核态以太网协议栈,然后通过 Loopback 回环进入 Sidecar 边车的内核态和用户态协议栈。经由 Sidecar 流量劫持之后,通过应用 Sidecar 调用内核态 Socket 进入容器内核态以太网协议栈。最后经由主机用户态容器网络 CNI,通过虚拟主机网络,进入物理网卡和物理网络,转发至目标应用程序所在的主机和容器环境。目标应用程序所在的主机网络和容器网络的数据包处理路径与源应用程序数据包处理路径一样,但收发数据包的方向相反。
云原生背景下的容器网络,会在物理网络、主机网络、容器网络和容器主机网络等多个层面网络类型的网络性能瓶颈,可以从下表多维度分析潜在的网络加速方向:
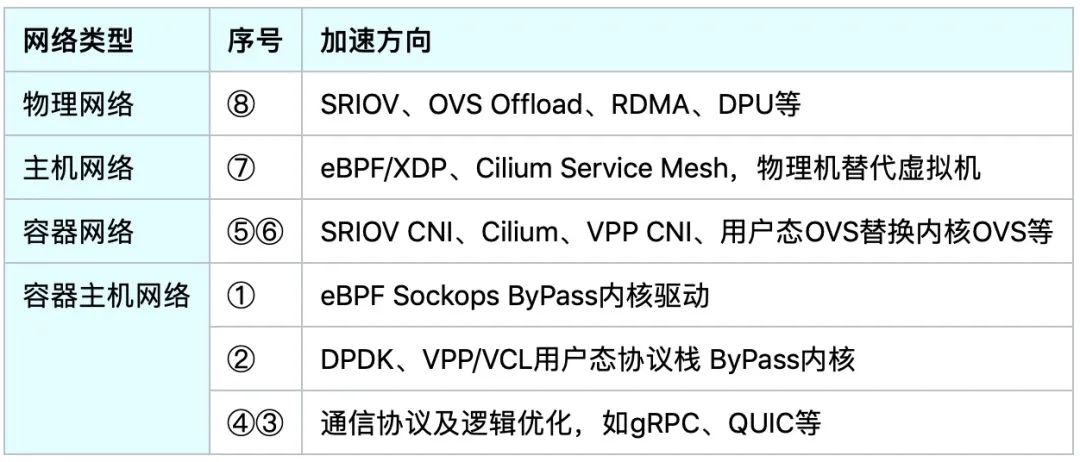
基于以上容器网络数据路径的分析,可以从几个方面进行网络规划和建设:
1、智能硬件网络方面,可以通过 Offload 下沉网卡驱动和数据包至智能硬件(SRIOV/DPU/RDMA)实现加速。
2、软件网络方面,操作系统网络层分为内核态网络和用户态网络,通过 ByPass 操作系统内核态网络协议栈,进入用户态网络协议栈,在用户态借助工具套件 DPDK,以及用户态 VPP、 VCL 和 QUIC 等协议进行编程,解决用户态网络性能问题,实现内核态和用户态网络加速。
容器网络加速方案
1. 智能网络加速
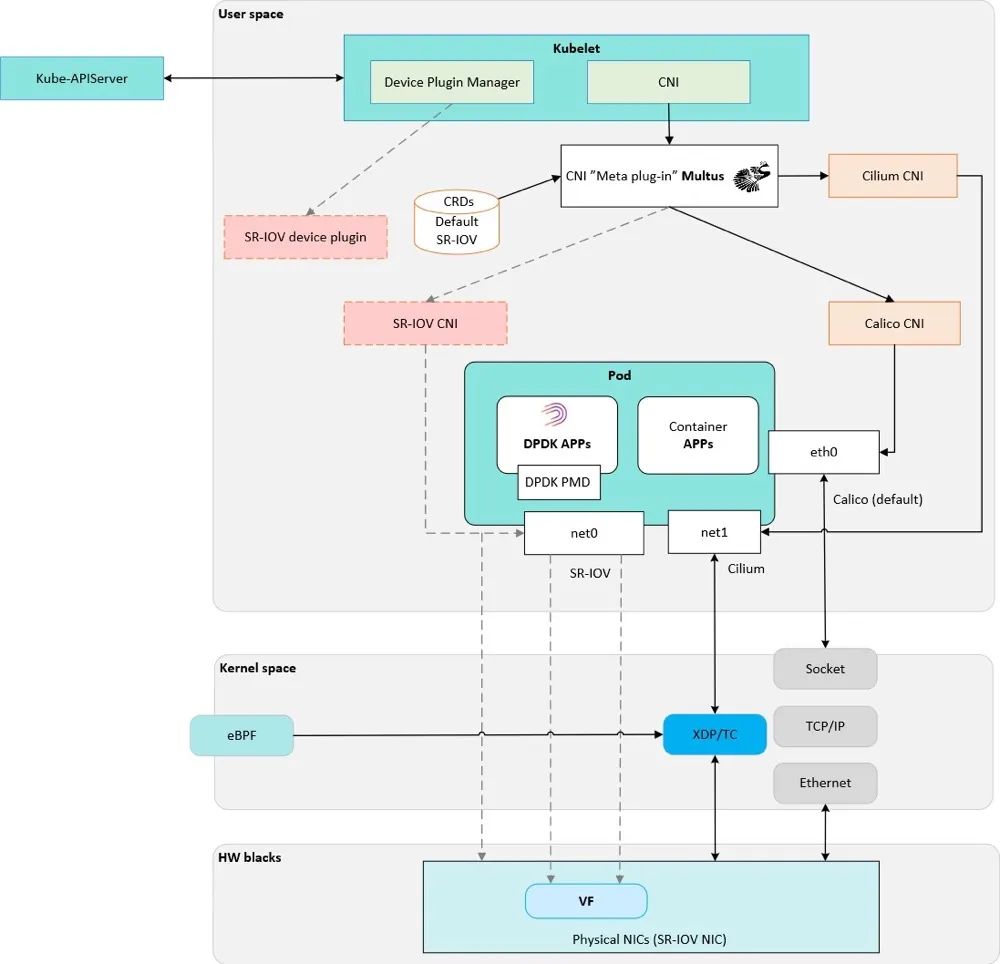
借助于支持 SR-IOV 的智能硬件,把网卡驱动卸载至物理网卡。通过调用 Netlink 包将 VF 修改到容器的 Namespace 下,使得物理机中 PF 扩展出来的 VF 可以被容器直接调用。基于 Multus、SR-IOV Device Plugin 和 SR-IOV CNI (Kubernetes 1.24 之前的版本,CNI 的管理由 Kubelet 负责,新版 Kubernetes 版本 CNI 管理由 CRI 负责)实现网络 IO 卸载至物理网卡上的 VF,同时把 VF 另一端插入容器,作为容器的以太网网卡。容器网络数据包从容器用户态协议栈,经过容器内核态协议栈,通过 VF 卸载至物理网卡 PF,ByPass 容器主机内核和主机内核驱动从而实现网络加速。同时,在?Underlay 网络场景中,通过 IPAM 可以管理集群域的固定 IP 分配、释放和回收,以及防止 IP 泄漏和 IP 冲突检测等。
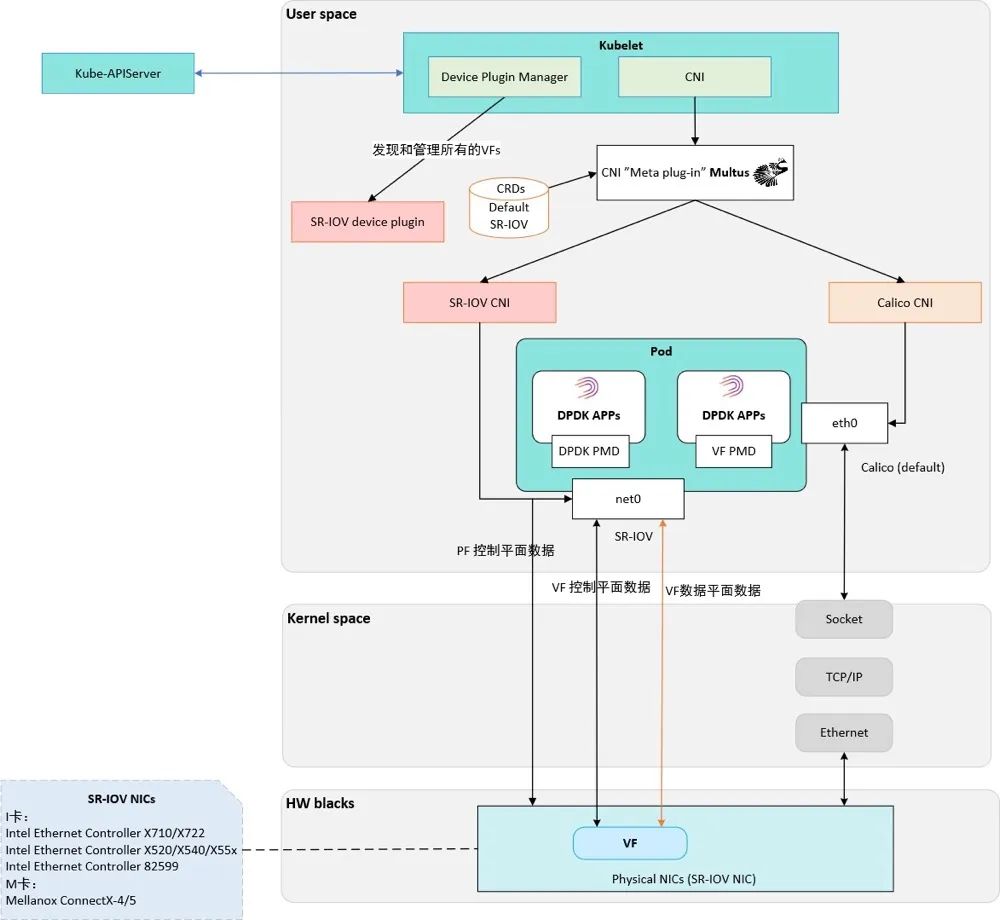
目前常见的支持容器 SR-IOV 技术的网卡有 Intel X710/X722/X520/540、Mellanox ConnectX-4/5/6 等,同时支持 NUMA、RDMA 和 DPU 等技术。
2. 内核态网络加速
基于支持 eBPF 的高内核版本(Kernel 4.19.57+,推荐5.10+ )的 Linux 操作系统,在 XDP 原生驱动模式(Native-Routing)或卸载模式(Offload,需要智能网卡支持)下 ByPass 内核协议栈,通过?Cilium CNI?将容器网卡一端植入 eBPF 程序,另一端插入容器内作为容器以太网网卡,实现通信和容器网络加速。可以基于 Multus、Cilium CNI 和 SpiderPool 实现内核网络加速。
3. 用户态网络加速
用户态的网络加速有多种实现方式,可以通过?SRIOV+DPDK 方式,把内核态网卡驱动切换成用户态网卡驱动,实现“用户态网卡 -> DPDK 轮询 Pool 模式-> DPDK 库 -> 应用程序” 跳过容器内核态网络协议栈,基于用户态 UIO Bypass 数据链路实现加速。或可以 DPDK +VPP/VCL 协议栈自编程模式的用户态网络极速。在服务网格场景下,借助于 Linux 高内核版本通过?eBPF Sockops/Sockmap 技术,实现应用服务与服务网格边车 Sidecar 之间的加速。
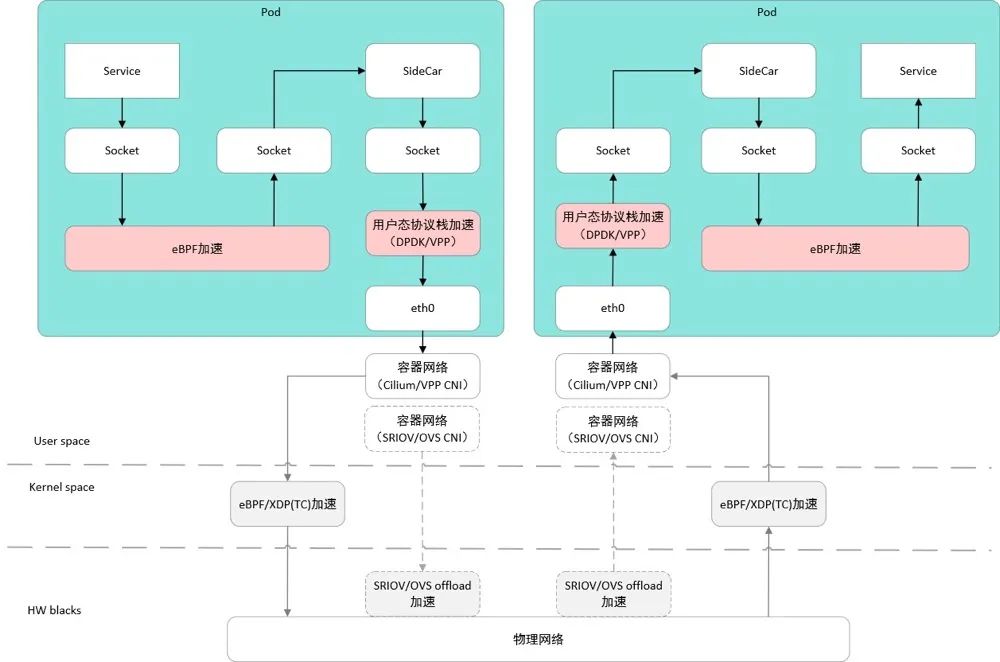
以上三种网络方案,各有其有特定使用场景,智能网络加速方案加速性能最好,需要有智能硬件网卡的支持,对操作系统没有特殊的要求。内核态网络加速方案加速性能居中,仅需要操作系统满足一定的内核版本要求,有较好的通用适配性,适应于大多数网络加速场景的要求。用户态网络加速方案作为智能网络加速和用户态网络加速在 ByPass 系统内核之外的互补方案,用于用户态域的的网络加速,可以帮助用户实现全场景的网络加速方案,适应于用户应用程序的在 DPDK 工具、VPP/VCL 协议族、gRPC/QUIC 低延迟协议等自编程。
参考链接:
https://docs.kernel.org/networking/index.html?
https://docs.cilium.io/en/stable/overview/component-overview/?
https://docs.cilium.io/en/stable/network/servicemesh/?
https://cilium.io/use-cases/service-mesh/?
https://ebpf.io/what-is-ebpf/?
https://docs.openvswitch.org/en/latest/intro/install/afxdp/?
https://github.com/k8snetworkplumbingwg/ovs-cni/blob/main/docs/ovs-offload.md?
https://xie.infoq.cn/article/6ba14b756c3019cc737ed48a6?
https://upload.wikimedia.org/wikipedia/commons/3/37/Netfilter-packet-flow.svg
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Elasticsearch_8.11.4_kibana_8.11.4_metricbeat_8.11.4安装及本地部署_ELK日志部署
- 看这里!分享3个有关iPhone照片恢复的好用方法!
- C# OpenCvSharp读取rtsp流录制mp4可分段保存
- css中>>>、/deep/、::v-deep的作用和区别,element-ui自定义样式
- 关于chatglm3 function calling的理解
- labelme读取文件顺序
- 使用JavaScript制作一个在线记事本
- 一文读懂AI计算平台库
- SQL面试题挑战05:找出恶意购买用户
- 【PyTorch简介】5.Autograd 自动微分