面试必问究极重点之HashMap的底层原理
1.底层数据结构
? ? ? ? JDK版本不同的数据结构
1.7 数组 + 链表
1.8 数组 + (链表 | 红黑树)
2.添加数据put
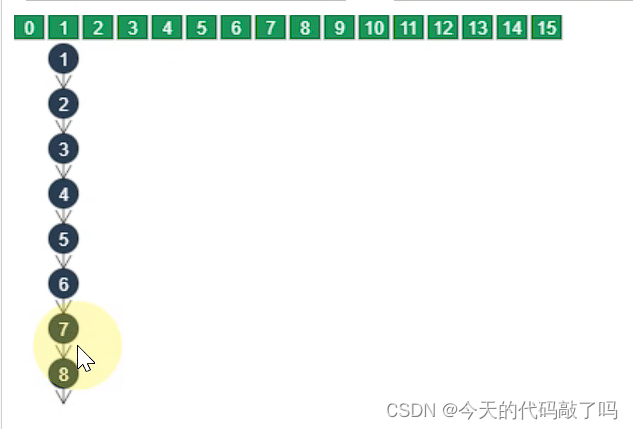
- 在添加一个值的时候,首先会计算他的hash码,然后进行二次hash,在对当前长度取模得到在底层数组中的索引位置
- 当取模完成后,会遇到不同元素索引位置相同的情况。我们把这种情况叫做hash冲突,此时会将后一个元素通过链表的形式挂在下边
- 当存储元素数量超过数组容量的四分之三时,会进行扩容,扩容后,也可以减少链表长度。
- 但是如果同一条链上的元素原始hash本就相同,此时通过扩容就不能有减少链表的长度了
3.树化与退化
树化意义
-
红黑树用来避免 DoS 攻击,防止链表超长时性能下降,树化应当是偶然情况,是保底策略
-
hash 表的查找,更新的时间复杂度是 $O(1)$,而红黑树的查找,更新的时间复杂度是 $O(log_2?n )$,TreeNode 占用空间也比普通 Node 的大,如非必要,尽量还是使用链表
-
hash 值如果足够随机,则在 hash 表内按泊松分布,在负载因子 0.75 的情况下,长度超过 8 的链表出现概率是 0.00000006,树化阈值选择 8 就是为了让树化几率足够小
-
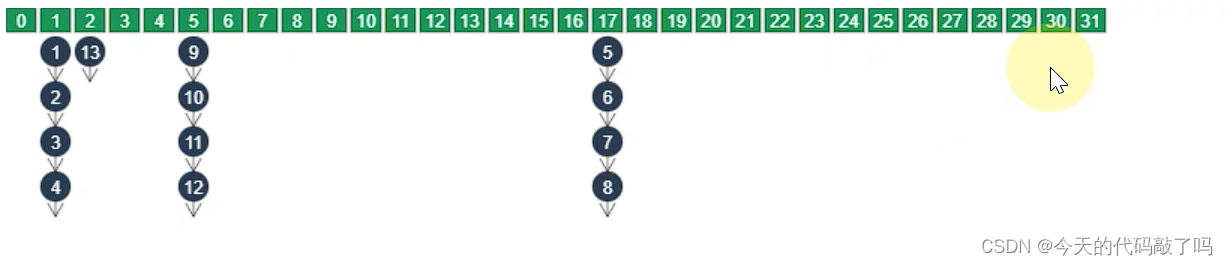
树化规则
-
当链表长度超过树化阈值 8 时,先尝试扩容来减少链表长度,如果数组容量已经 >=64,才会进行树化
退化规则
-
情况1:在扩容时如果拆分树时,树元素个数 <= 6 则会退化链表
-
情况2:remove 树节点时,若 root、root.left、root.right、root.left.left 有一个为 null ,也会退化为链表(在移除之前检查
4.索引计算
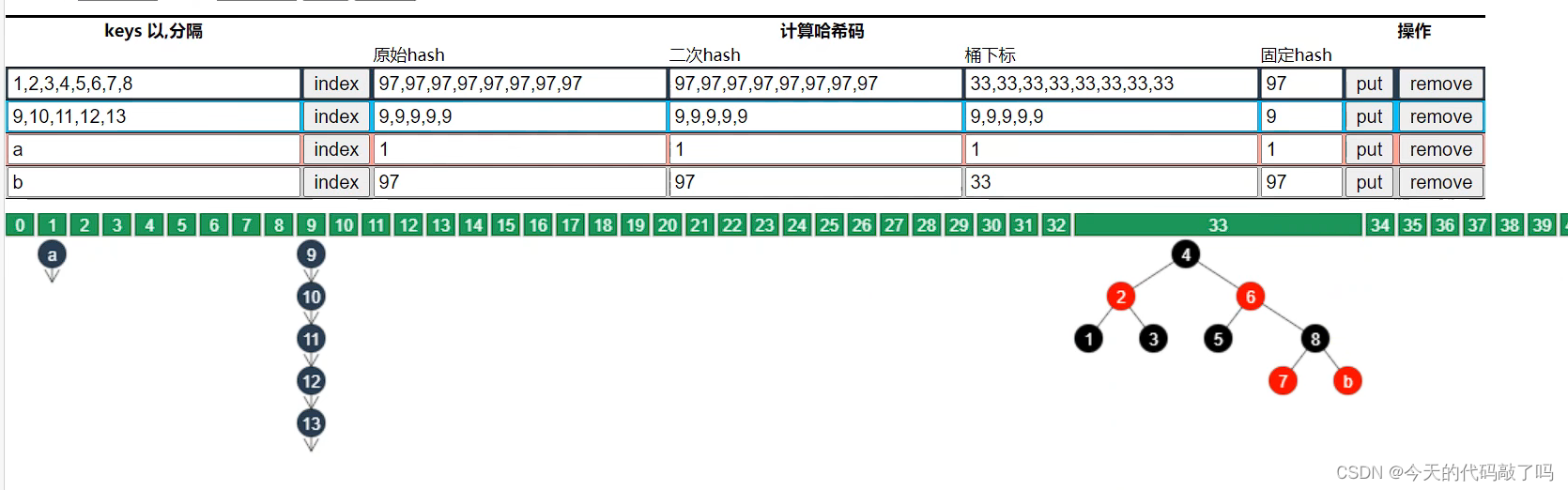
索引计算方法
-
首先,计算对象的 hashCode()
-
再进行调用 HashMap 的 hash() 方法进行二次哈希
-
二次 hash() 是为了综合高位数据,让哈希分布更为均匀
-
-
最后 & (capacity – 1) 得到索引
数组容量为何是 2 的 n 次幂
-
计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
-
扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
注意
-
二次 hash 是为了配合 容量是 2 的 n 次幂 这一设计前提,如果 hash 表的容量不是 2 的 n 次幂,则不必二次 hash
-
容量是 2 的 n 次幂 这一设计计算索引效率更好,但 hash 的分散性就不好,需要二次 hash 来作为补偿,没有采用这一设计的典型例子是 Hashtable
5.put与扩容
put 流程
-
HashMap 是懒惰创建数组的,首次使用才创建数组
-
计算索引(桶下标)
-
如果桶下标还没人占用,创建 Node 占位返回
-
如果桶下标已经有人占用
-
已经是 TreeNode 走红黑树的添加或更新逻辑
-
是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑
-
-
返回前检查容量是否超过阈值,一旦超过进行扩容
1.7 与 1.8 的区别
-
链表插入节点时,1.7 是头插法,1.8 是尾插法
-
1.7 是大于等于阈值且没有空位时才扩容,而 1.8 是大于阈值就扩容
-
1.8 在扩容计算 Node 索引时,会优化
扩容(加载)因子为何默认是 0.75f
-
在空间占用与查询时间之间取得较好的权衡
-
大于这个值,空间节省了,但链表就会比较长影响性能
-
小于这个值,冲突减少了,但扩容就会更频繁,空间占用也更多
6.源码分析
待补充
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 盈科数智视频管理平台简介
- 排序算法-归并排序(含C语言代码示例)
- YoloV8改进策略:BN和LN的自适应结合的BCN| 正则化改进|有效涨点|代码二次改进,加注释详解
- SAP ABAP 报表程序status报错 无法将此项功能指派给按钮解决办法
- 2024年面试工具篇Jmeter接口面试题及答案
- [陇剑杯 2021]jwt
- Java 面试题 - 集合篇
- 【算法】代码随想录刷题记录 | 4. 字符串篇(含KMP算法详细步骤及代码)
- Ansible自动化运维工具
- drools开源规则引擎介绍以及在Centos上的具体部署方案,让你的业务规则能够独立于应用程序本身