第十四章 集合(Map)
一、Map 接口
1. Map 接口实现类(JDK8)的特点(P531)
(1)Map 与 Collection 并列存在。用于保存具有映射关系的数据:Key-Value。
(2)Map 中的 key 和 value 可以是任何引用类型的数据,会封装到 HashMaps$Node 对象中。
(3)Map 中的 key 不允许重复,原因和Hashset一样。
(4)Map 中的 value 可以重复。
(5)Map 的 key 可以为 null,value 也可以为 null。注意 key 为null,只能有一个。
(6)key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value。
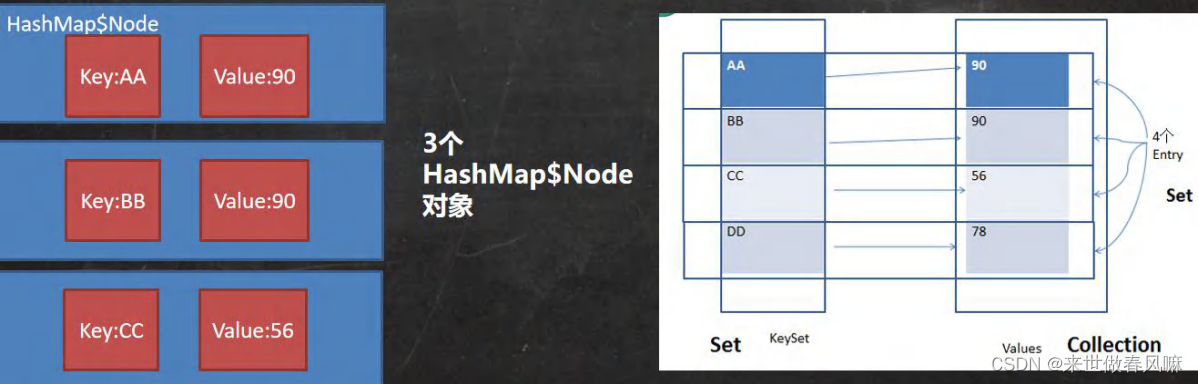
(7)Map 存放数据的 key-value 示意图,一对 K-V 是放在一个 HashMap的Node 中的,又因为 Node 实现了 Entry 接口,有些书上也说一对 K-V 就是一个Entry(如图)。
public class Demo {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("name","Tom");
Set entrySet = map.entrySet(); // Set<Map.Entry<K,V>>
Set keySet = map.keySet(); // Set<K>
Collection values = map.values(); //Collection<V>
}
}
解读:
(1)为了方便程序员的遍历,会创建EntrySet集合。
即:transient Set<Map.Entry<K,V>> entrySet;
(2)entrySet中,定义的类型是 Map.Entry,但是实际上存放的还是 HashMap$Node
即:static class Node<K,V> implements Map.Entry<K,V>
(3)Map.Entry提供了两个重要方法
K getKey();
V getValue();
2. Map 接口常用方法
(1)put:添加
(2)remove:根据键删除映射关系
(3)get:根据键获取值
(4)size:获取元素个数
(5)isEmpty:判断个数是否为0
(6)clear:清除
(7)containskey:查找键是否存在
二、Map 接口 六大遍历方式(P534)
1. keySet 的两种方式
public class Demo {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("name","Tom");
map.put("age",12);
Set keySet = map.keySet();
// (1) 增强for
for (Object key : keySet) {
System.out.println(key + "-" + map.get(key));
}
// (2) 迭代器
Iterator it = keySet.iterator();
while (it.hasNext()) {
Object key = it.next();
System.out.println(key + "-" + map.get(key));
}
}
}
2. 直接获取 values 的两种方法
public class Demo {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("name", "Tom");
map.put("age", 12);
Collection values = map.values();
// (1) 增强for
for (Object value : values) {
System.out.println(value);
}
// (2) 迭代器
Iterator it = values.iterator();
while (it.hasNext()) {
Object value = it.next();
System.out.println(value);
}
}
}
3. EntrySet 的两种方式
public class Demo {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("name", "Tom");
map.put("age", 12);
Set entrySet = map.entrySet();
// (1) 增强for
for (Object entry : entrySet) {
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
// (2) 迭代器
Iterator it = entrySet.iterator();
while (it.hasNext()) {
Object entry = it.next();
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
}
}
三、HashMap 底层机制(P537)
1. 扩容机制[和HashSet相同]
(1)HashMap 底层维护了 Node 类型的数组 table,默认为 null。
(2)当创建对象时,将加载因子(loadfactor)初始化为0.75。
(3)当添加 key-val 时,通过 key 的哈希值得到在 table 的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,继续判断该元素的 key 和准备加入的key 是否相等,如果相等,则直接替换 val ;如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
(4)第1次添加,则需要扩容table容量为16,临界值(threshold)为12。
(5)以后再扩容,则需要扩容 table 容量为原来的2倍,临界值为原来的2倍,即24,依次类推。
(6)在 Java8 中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且 table 的大小 >= MIN_TREEIFY_CAPACITY(默认64)就会进行树化(红黑树)。
四、Map 接口实现类 - Hashtable(P540)
1. Hashtable的基本介绍
(1)存放的元素是键值对:即K-V。
(2)Hashtable 的 键和值都不能为 null,否则会抛出空指针异常。
(3)Hashtable 是线程安全的(synchronized),HashMap 是线程不安全的。
2. Hashtable 的底层
(1)底层有数组 Hashtable$Entry[] ,初始化大小为11
(2)if (count>=threshold)满足时,就进行扩容。
按照 int newCapacity=(oldcapacity<<1)+1;的大小扩容。
3. Hashtable 和 HashMap 对比

五、Map 接口实现类 - Properties(P542)
(1)Properties 类继承自 Hashtable 类井且实现了 Map 接口,也是使用一种键值对的形式来保存数据。
(2)Properties 还主要用于 xxx.properties 文件中,加载数据到 Propertie s类对象,并进行读取和修改。
未完待
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java反编译工具jd-gui下载与使用
- [VScode]Jupyter自动生成目录
- VK36W6D SOP16抗干扰液位检测/6点水位检测芯片/液体检测IC
- 民宿预约管理系统(JSP+java+springmvc+mysql+MyBatis)
- 深圳激光打标机价格:品质与价值的完美结合
- Qt基础-QSpinBox控件使用
- centos6 | 更新镜像云
- 搭建DNS 服务
- mysql 小表A驱动大表B在内关联时候,怎么写sql?那么左关联呢?右关联有怎么写?
- 软件自动化测试较于手工测试有什么优势?软件测试外包公司推荐