岭回归(Ridge Regression)
发布时间:2024年01月10日
什么是机器学习
岭回归(Ridge Regression)是一种线性回归的扩展,它通过在损失函数中添加正则化项(L2范数)来解决线性回归中可能存在的过拟合问题。正则化项有助于限制模型的参数,使其不过分依赖于训练数据,从而提高模型的泛化能力。
岭回归的目标函数可以表示为:
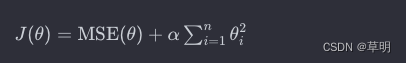
其中:
J(θ)是岭回归的目标函数MSE(θ)是均方误差(Mean Squared Error)α是正则化参数θ1, θ2, ... , θn是模型的参数
训练岭回归模型的过程是通过最小化目标函数找到最适合数据的参数。正则化项对模型的参数进行惩罚,使得参数趋向于较小的值,从而减小模型对训练数据的过拟合程度。
代码示例(使用 Python 和 scikit-learn)
以下是一个使用 scikit-learn 库进行岭回归的简单示例:
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import numpy as np
import matplotlib.pyplot as plt
# 生成随机数据
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 创建岭回归模型
ridge_model = Pipeline([
('scaler', StandardScaler()), # 特征标准化
('ridge', Ridge(alpha=1, solver='cholesky')) # 岭回归模型
])
# 拟合模型
ridge_model.fit(X, y)
# 预测新数据
X_new = np.array([[1.5]])
y_pred = ridge_model.predict(X_new)
print("预测结果:", y_pred[0][0])
# 绘制散点图和拟合的直线
plt.scatter(X, y, color='blue')
plt.plot(X, ridge_model.predict(X), color='red', linewidth=3)
plt.xlabel("自变量")
plt.ylabel("因变量")
plt.title("岭回归")
plt.show()
在这个例子中,我们使用了 scikit-learn 的 Ridge 类来构建岭回归模型。模型中的 alpha 参数表示正则化强度,你可以根据实际问题调整这个参数。模型还包括一个 StandardScaler,用于对输入特征进行标准化。这是因为在岭回归中,正则化项对参数的惩罚是基于特征的尺度计算的,因此标准化可以确保各个特征的尺度一致。
文章来源:https://blog.csdn.net/galoiszhou/article/details/135494609
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 随身WiFi问题解答大全!随身wifi怎么选?随身wifi排行榜第一名
- 透彻掌握GIT基础使用
- Mysql 报错Parameter ‘@xxx‘ must be defined
- LeetCode刷题12:贪心算法解决1402.做菜顺序
- Ubuntu系统开不了机左上角一直显示一个白色的杠
- Vue3使用事件总线(Event Bus)实现发布订阅模式
- 璀璨2023,共赴2024——Tempo大数据分析产品年度回顾
- MySQL之导入以及导出&远程备份v
- 【unity】屏幕事件
- 青云租和香港上市公司SPROCOMM INTEL共同推出中国领先手机供应链平台