JAVA序列化(创建可复用的 Java 对象)
JAVA 序列化(创建可复用的 Java 对象)
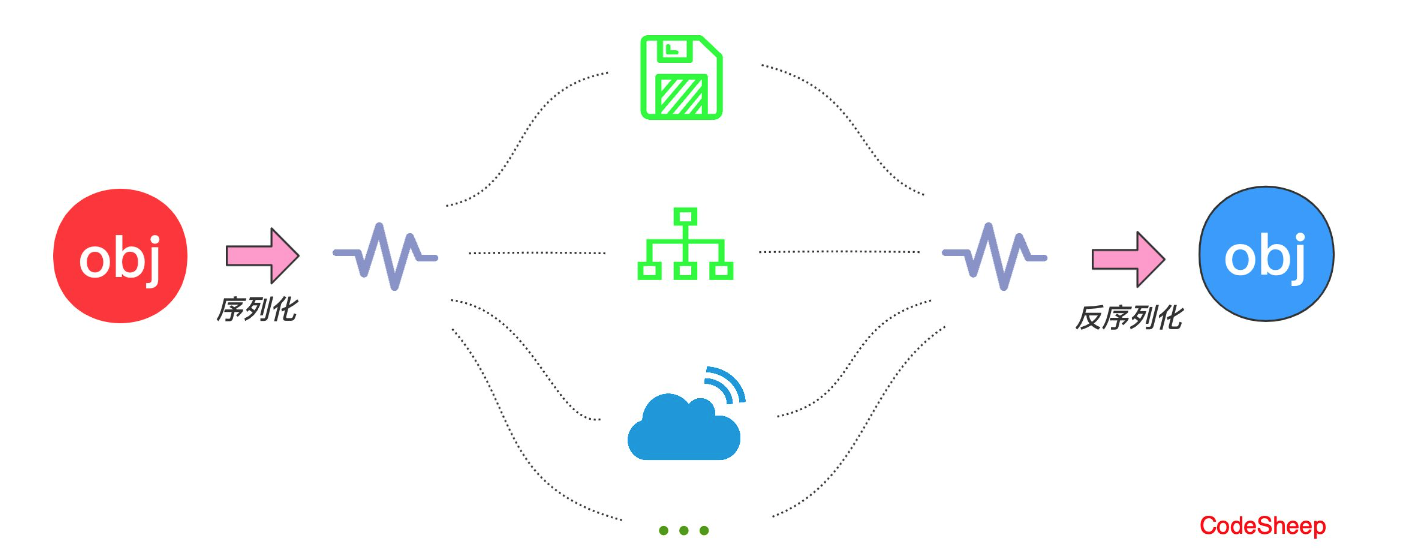
保存(持久化)对象及其状态到内存或者磁盘
Java 平台允许我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比 JVM 的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。
Java 对象序列化就能够帮助我们实现该功能。
序列化对象以字节数组保持-静态成员不保存
使用 Java 对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
序列化用户远程对象传输
除了在持久化对象时会用到对象序列化之外,当使用 RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java序列化API为处理对象序列化提供了一个标准机制,该API简单易用。
Serializable 实现序列化
在 Java 中,只要一个类实现了 java.io.Serializable 接口,那么它就可以被序列化。
ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化
通过 ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化。
writeObject 和 readObject 自定义序列化策略
在类中增加 writeObject 和 readObject 方法可以实现自定义序列化策略。
序列化 ID
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)
序列化并不保存静态变量
序列化子父类说明
要想将父类对象也序列化,就需要让父类也实现 Serializable 接口。
Transient 关键字阻止该变量被序列化到文件中
-
在变量声明前加上 Transient 关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
-
服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
JAVA 复制
将一个对象的引用复制给另外一个对象,一共有三种方式。第一种方式是直接赋值,第二种方式是浅拷贝,第三种是深拷贝。所以大家知道了哈,这三种概念实际上都是为了拷贝对象。
直接赋值复制
直接赋值。在 Java 中,A a1 = a2,我们需要理解的是这实际上复制的是引用,也就是说 a1 和 a2 指向的是同一个对象。因此,当 a1 变化的时候,a2 里面的成员变量也会跟着变化。
浅复制(复制引用但不复制引用的对象)
创建一个新对象,然后将当前对象的非静态字段复制到该新对象,如果字段是值类型的,那么对该字段执行复制;如果该字段是引用类型的话,则复制引用但不复制引用的对象。因此,原始对象及其副本引用同一个对象。
class Resume implements Cloneable{
public Object clone() {
try {
return (Resume)super.clone();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
深复制(复制对象和其应用对象)
深拷贝不仅复制对象本身,而且复制对象包含的引用指向的所有对象。
class Student implements Cloneable {
String name;
int age;
Professor p;
Student(String name, int age, Professor p) {
this.name = name;
this.age = age;
this.p = p;
}
public Object clone() {
Student o = null;
try {
o = (Student) super.clone();
} catch (CloneNotSupportedException e) {
System.out.println(e.toString());
}
o.p = (Professor) p.clone();
return o;
}
}
序列化(深 clone 一中实现)
在 Java 语言里深复制一个对象,常常可以先使对象实现 Serializable 接口,然后把对象(实际上只是对象的一个拷贝)写到一个流里,再从流里读出来,便可以重建对象。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 造纸化学品,将以3.6%的复合年增长率增长
- 软件测试开发工程师常用的测试工具详解
- 单元测试基本概念
- 【python】神经网络
- 【C++】通过getline读取一行输入
- 电脑触摸板用法大全
- AI大模型引领未来智慧科研暨ChatGPT在地学、GIS、气象、农业、生态、环境等领域中的高级应用
- linux进程和计划任务
- java并发编程十五 ReentrantReadWriteLock和StampedLock介绍
- 【数据结构】模式匹配之KMP算法与Bug日志—C/C++实现