linux 中 ext2文件系统实现
ext2文件系统结构
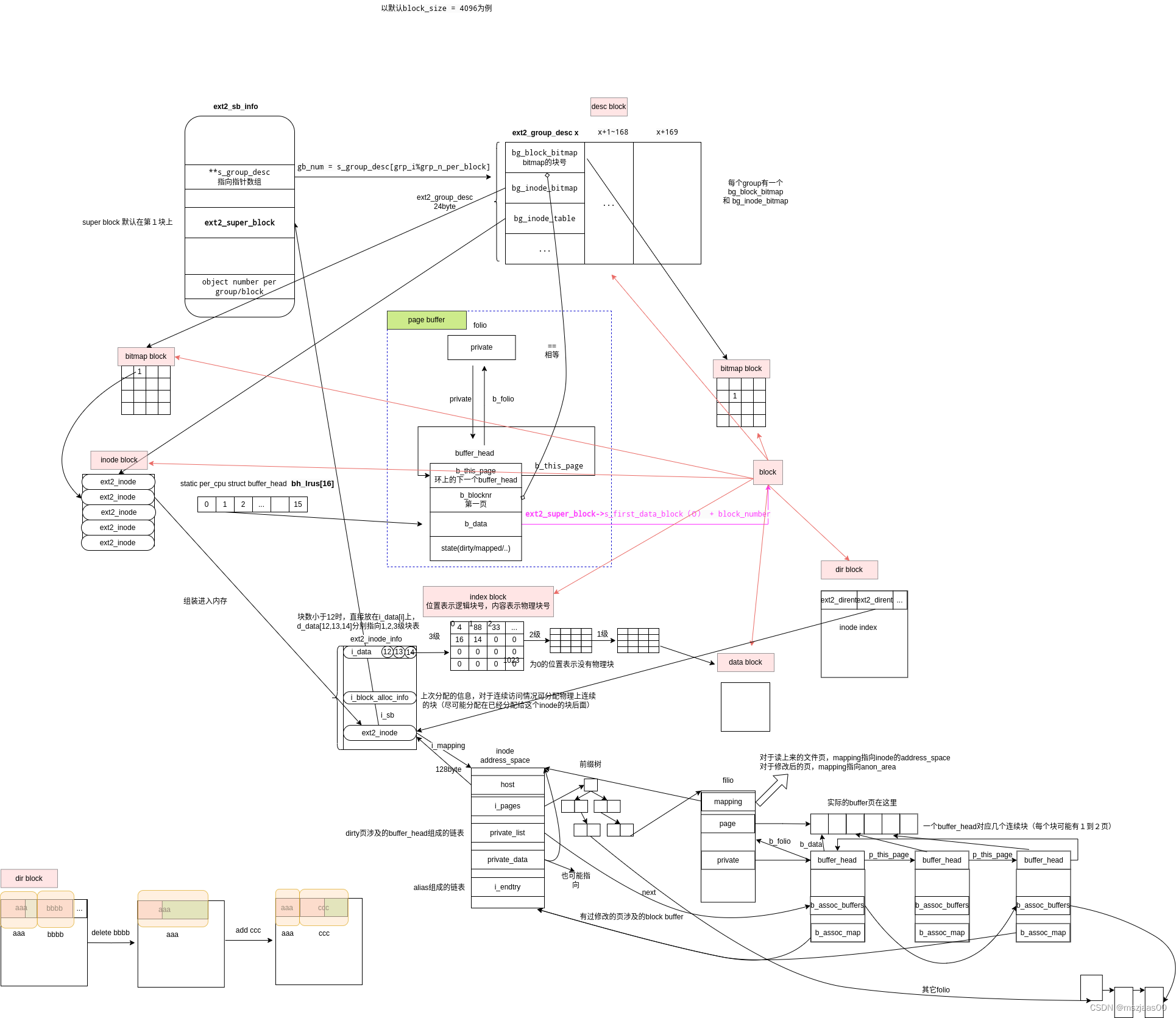
图片的svg下载链接(图中关于buffer的部分,上下两部分是重复的,是从不同维度下看的buffer结构)
linux内核本身不提供ext2文件系统的格式化功能,可以参考busybox中对mkfs.ext2的实现(mkfs.ext2.c)格式化过程简述如下:
mkfs_ext2_main():
计算每个部分的资源
填充super_block
填充group_desc_blocks,desc中主要包含三部分数据块的块号
bg_block_bitmap,
bg_inode_bitmap,
bg_inode_table
在每个group的bitmap块中标记这些元数据块的位置为已分配(其中第一块还会有super_block)
将inode_table空间初始化为0
添加. .. lost_found 这三个目录项。在busybox中块大小与总大小有关,总磁盘大小至少是64k,64k-512m是4096B,512m-4T是8192B(4T以上不考虑了)。一个group中装的block数是一块bitmap块所能承载的数(比如一块4096byte时,能代表的块数是4k*8=32k个块)
从代码流程可以看出ext2系统的布局如下:

没有引导块,super block存了整体信息,group desc存了group信息所在块号(最重要的是三种块的块号:block分配bitmap、inode分配的bitmap、inode 实际存储信息的多个块)。这两部分信息有多个备份。真正的inode和文件内容存在data block上。
ext2中inode分配
inode分配的实现在ext2_new_inode,每次尝试从inode数和block数都占用不多的group分配inode(find_group_orlov),然后从这组的bitmap中找一个合适的位置setbit,它对应了inode_table 中一段实际的磁盘空间。从slab中分配一个包含inode节点的struct ext2_inode_info,将找到的inode号填入inode->ino中,这里不需要访问设备。将inode_table对应位置所在块和inode bitmap 所在块标记为dirty(mark_buffer_dirty),之后就在合适时间等着刷盘就好了(这个链路可以参考linux buffer的回写的触发链路)。
注:存在设备上的inode状态中信息大部分来自于inode 结构。但在内存中会对这个inode结构做一个封装(ext2_inode_info),inode结构存在ext2_inode_info->vfs_inode位置。可以通过EXT2_I(struct inode *inode)函数找到inode对应的ext2_inode_info。
另外当分配一个路径时,每个dir inode有一个对应的block,上面存了ext2_dirent,它是可变长的结构(因为路径的名称可长可短)。当要删除一个路径时,不需要将后面的dirent向前补齐,而是将dirent与前一个dirent合并。所以在分配时也是同理,需要遍历dirent,将合适的dirent的空闲部分切下来作为新的dirent。
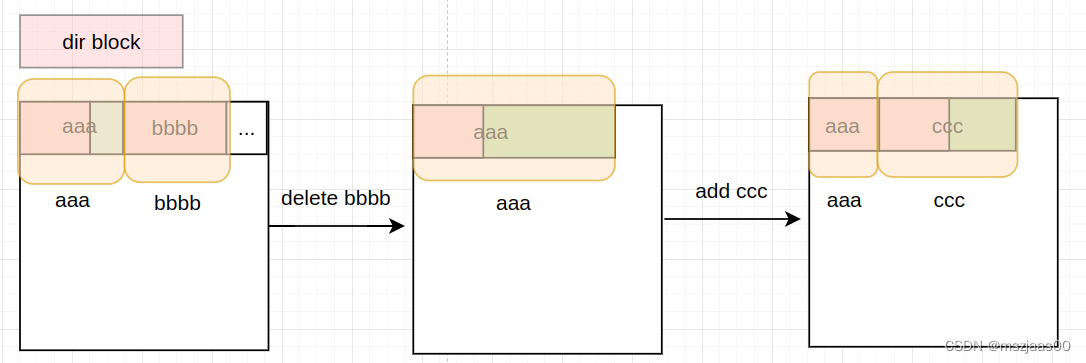
ext2中inode的访问
每个inode 的ext2_inode_info中有一个i_data数组,当一个inode文件中分配块数少于12时,可以直接使用i_data的前12个元素作为逻辑块1-12所对应的物理块号。当一个文件块数超过12小于1024(一个block所能装int类型的数量)时,i_data的第13位(index = 12)指向1级列表所在的块,这块中每一项表示对应逻辑块(12-1023)的物理块号。
依此类推,1K-1M之间的逻辑块用i_data[13]所指向的二级块表来索引,1M-1G之间的逻辑块用i_data[14]所指向的三级块表来索引。

当读取一个block时,首先通过inode的块表找到对应逻辑块的物理块号(ext2_block_to_path)。将物理块加载到内存中,封装成一个buffer_head结构,并返回(ext2_get_block)。
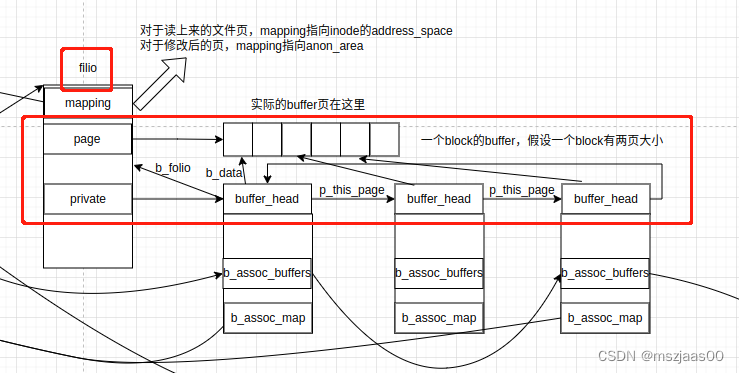
buffer_head是设备与buffer之间的一个扭带,它映射了设备上的一片区域(在代码中一个buffer_head对应几个连续的block)。真正的buffer内容存在struct page对应的页空间上(页与struct page的转换关系可以参考:linux中 struct page 与物理地址的关系)
下图中filio是对page的封装,可以理解为一段连续物理内存页的集合,第一页的folio->page上存了页区间的第一个struct page,其后连续的struct folio填满了folio对应的区间。(下图中画的page指向一段页,实际上不是指针关系,而是上面链接提到的,struct page结构地址本身映射了一块内存),这些实际的物理内存组成了一段buffer。区间第一页的folio->private是buffer_head的链表,其上存了这个buffer与块设备上block内容的对应关系,其中buffer_head->b_data指向一个block大小的buffer。(下图中更正:一个buffer_head不一定对应一个块,可以对应几个连续块)
当修改文件中一段内容时,它对应的块的buffer_head会链在inode->private_list所在链表上。等待后期刷盘时遍历。如下图所示:
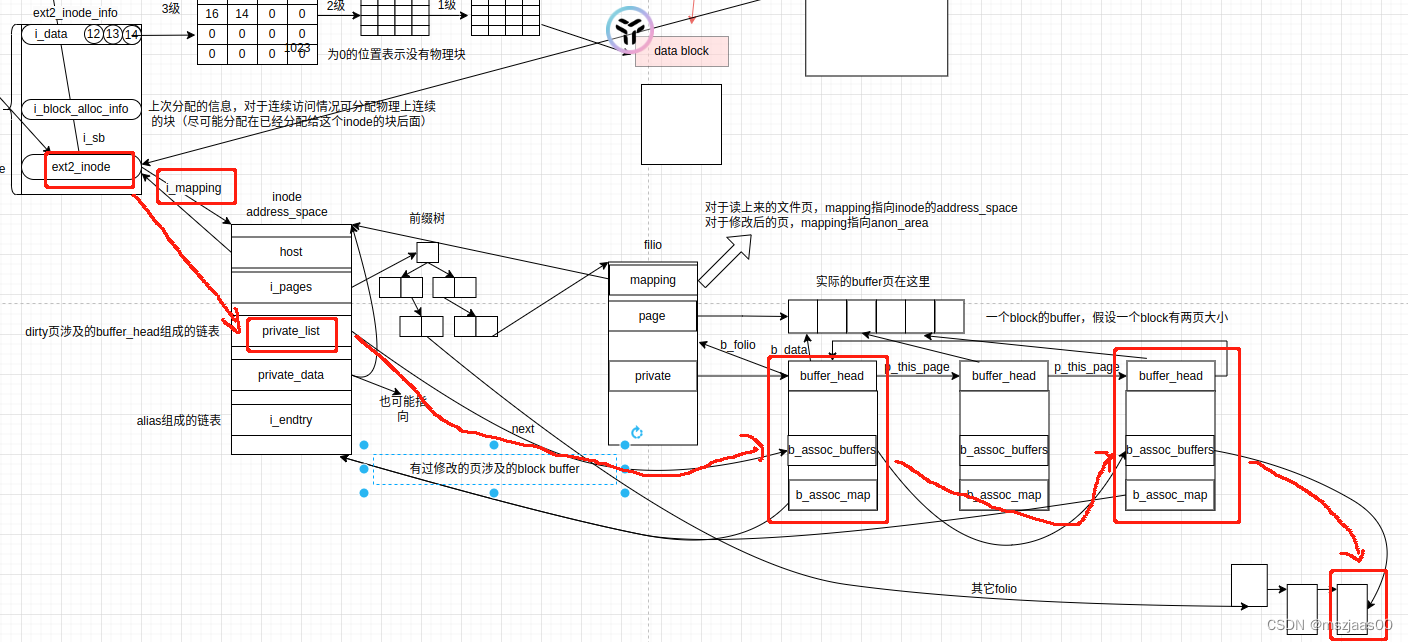
这里想到一个问题,当父进程fork了一个子进程,这个子进程中通过copy on write 的方式修改了一个文件的内容,会发生什么改变呢?答案是什么也不会发生,因为copy on write是在逻辑地址上做的文章(原理可以参考这篇:理解linux中反向映射与应用),这里的buffer都是物理地址。
ext2中inode块的分配
由于底层访问接口中一次只加载一个block,为了让逻辑上连续的块在物理设备上也尽可能连续,每次为inode分配逻辑块时,会启发性地,一次分配多个连续的块(ext2_get_blocks),我们重点分析下这个启发式过程。
其中每个文件可能有自己的reserve window,但并不保证分配的块一定属于这个文件,有可能在分配reserve window之前其间的物理块早被多个其它文件分配过。reserve window的作用只是说先占着,别的文件分配时会跳过这个区域,从而保证一个文件在分配时物理块尽可能在一起。分配window时的算法保证这个reserve winodw的区域至少有一个空闲块(alloc_new_reservation)。
ext2_get_blocks():
// 将块号分解为块表的分量
ext2_block_to_path();
// 将块表链路上的块都找到,收集到chain中
// chain节点Indirect的key=下层物理块号,p=下层逻辑块号所在地址
ext2_get_branch();
// 选定一个目标块用来分配,原则是尽可能与同一文件分配过的块挨着
// 如果上次分配的逻辑块号与物理块号刚好可用,则选定这个块号
// 否则在这个块中向左找分配过的物理块号,选定接在它(逻辑上分配过的块的物理块号)后面。
// 如果这一逻辑块中前面没有分配过的块,则选承载这级块表的物理块的后面一块。
// 如果这是新文件,没有分配过块表,则在inode所在group的1/16*x分配
// (x在0到15之间,目的是让新文件分配的物理块尽可能隔开,这样可以使同一文件的物理块尽可能挨着)
ext2_find_goal();
// 启发式计算一次性分配多少连续块(分配长度),
// 这里不要求物理块连续,会在后面将分配长度削减到连续物理块数:
// 如果块表的最后一级是中间块,则分配长度为传入的maxblocks块。
// 如果maxblocks数量跨过了这个中间块,则分配长度为从逻辑块位置到这个中间块表结束的块数。
// 如果块表的最后一级是叶子块,则分配长度为选定逻辑块后没有分配过的连续逻辑块块数。
ext2_blks_to_allocate();
// 分配块表子链
// 传入参数indirect_blks指最后一级块表到分配data块还差几层
// blks和goal指上面启发式计算的分配长度和启始分配块
ext2_alloc_branch():
ext2_alloc_blocks():
// 尝试分配至少indirect_blks(新块表项)+1个块,
// 其中前面的作为data块,后面的作为新块表块
while (分配的连续块还不够用)
ext2_new_blocks();
// 将buffer_head与这个分配的连续data块绑定(不包含块表块)
map_bh(bh_result, bno);
// 如果分配的块数超过了最后一级块表的边界,只有一种可能
// 就是新分配的块表块接在了新分配的data 块后面。
// 则在buffer_head上标记一下,后面刷盘时,除了刷data block外,
// 连带要检查一下后面的块,因为它可能是这个data block所在的块表块。
// 一起刷盘更能保证原子性(write_boundary_block)
set_buffer_boundary(bh_result);
ext2_new_blocks():
先尝试从选定块的group上的reserve window分配
如果不能分配,其它group只取free block大于reserve window 的一半的reserve window分配
如果用reserve window分配不成功,尝试不用reserve window分配,还是先goal group,再其它group。
实现用了同一个入口函数 ext2_try_to_allocate_with_rsv
ext2_try_to_allocate_with_rsv():
在尝试reserve_window的场景,尝试通过扩张reserve window的方式来满足分配大小,
在有指定目标物理块的情况下,尝试让window覆盖目标块
如果忽略了目标物理块,则尝试从整个group去分配。
扩张有几个原则:1、如果window内已经分配过一半以上,尝试扩张一倍大小。
2、如果覆盖了目标块,尝试让reserve window覆盖请求的大小
3、扩张后的块内必须至少有一个free的block
然后调ext2_try_to_allocate从bitmap中去找一个空闲块。
当扩张大小不足以覆盖请求大小时,尝试缩短请求连续块数
在不尝试reserve_window的场景,直接调ext2_try_to_allocate找空闲块
ext2_try_to_allocate():
// 找空闲块有一定算法:
// 先从start位置到64 align 的位置结束找free bit.
// 如果没找到,尝试找空字节(以8bit为单位找)。
// 如果还没找到,才尝试从start位置开始,一个bit一个bit地找。
find_next_usable_block();
// 当找到空闲bit后,由于上面算法有以8bit为单位找的情况
// 因而向前找7个bit,看有没有连续的空闲块可用
for (i = 0;
i < 7 && grp_goal > start && !ext2_test_bit(grp_goal - 1,bitmap_bh->b_data);
i++, grp_goal--);
// 返回连续块的开始位置和块数
*count = num;
return grp_goal - num;
向ext2文件写内容
write的调用到真正操作如下:
write
->ksys_write
->vfs_write
->new_sync_write
->call_write_iter
->ext2_file_write_iter (ext2 的 op hook)
->generic_file_write_iter
->__generic_file_write_iter
->generic_perform_write
->file->f_mapping->a_opsfile的f_mapping就是inode->i_mapping,inode->i_mapping是在从slab拿一个ext2_inode_info时callback hook(init_once)中填充的。而file->f_mapping是在alloc_file时填充的(f_mapping = inode->i_mapping)。
写的过程分为write_begin,copy_page_from_iter_atomic,write_end三步。
第一步ext2_write_begin时,会做两件事,一个是准备buffer,为buffer分配页(会将folio->mapping 置为inode的i_mapping,filemap_add_folio),另一个是准备块,为刷盘区间的逻辑块分配物理块 (get_block)。
第二步迭代传入的用户空间的data,copy到buffer中(copy_page_from_iter_atomic)。
第三步ext2_write_end,标记buffer为dirty(__block_commit_write)。
在写完之后,会调一次sync,来刷盘(generic_file_write_iter->generic_write_sync)。从dirty到刷盘链路可以参考linux buffer的回写的触发链路
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 住宅IP代理實用指南
- 1.电子基础
- Android 车联网——PowerHalService介绍(九)
- 一体机定制_工控触控一体机安卓主板方案
- 组件通信方式
- 嵌入式高薪岗位分析——linux应用开发
- 约翰瑟尔的故事
- 15-网络安全框架及模型-BLP机密性模型
- SpringCloud Config配置中心详解及环境搭建
- NLP论文阅读记录-ACL 2023 | 10 Best-k Search Algorithm for Neural Text Generation