八大排序(超详细,万字总结)
目录??????????????
前言
常见的排序有八种,分别是插入排序,希尔排序,选择排序,堆排序,冒泡排序,快速排序,归并排序,计数排序。
其中快速排序,堆排序,归并排序的时间复杂度较低,是我们常用的排序算法。
此文章将对每个排序算法的 思想,代码实现,时间复杂度分析,最好最坏情况分析展开讨论
1.插入排序
1.1思想
想象我们在摸扑克牌时,每摸到一张牌,就把他插到他应该在的地方
所谓插入排序,就是从第二个元素开始到最后一个元素结束,把他放到前面有序序列的合适位置。
也就是说原本[0, end]是有序的,现在要把end+1位置上的元素放到区间里面,使得[0, end + 1]这段区间是有序的
动画演示:
1.2代码实现
void InsertSort(int arr[], int size)
{
for (int i = 0; i < size - 1; i++)
{
//[0, end] 是有序的,把arr[end + 1]插入到[0, end]中,使[0, end + 1]有序
int end = i;
//把arr[end + 1]先存起来,不然后面后移元素时会覆盖掉
int temp = arr[end + 1];
//序列没有走完而且没有找到正确位置
while (end >= 0 && arr[end] > temp)
{
//当还没找到正确位置时,把元素往后移
arr[end + 1] = arr[end];
end--;
}
arr[end + 1] = temp;
//要是序列走完了还没有找到正确位置,那temp就是最小的,要把他放到arr[0],这时候end == -1
}
}1.3时间复杂度分析
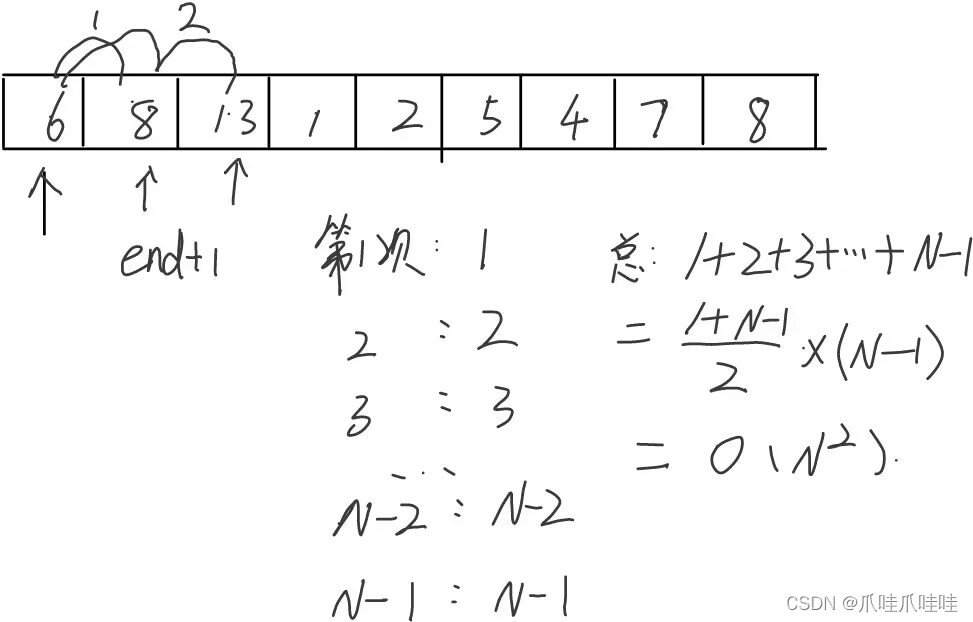
1.4最好最坏情况
最好:序列有序,因为arr[end] > temp,所以循环第一次就跳出来了,此时的时间复杂度是O(n)
最坏:序列倒序,如上图所示,时间复杂度是O(n^2)
插入排序对近乎有序的序列排序,效率是非常高的。所以插入排序是O(n^2)排序算法中最牛逼的。
2.希尔排序
2.1思想
我们知道插入排序对于接近有序的序列排序 效率是非常高的,那么我们考虑把一个无序的序列先变成接近有序的序列,再用插入排序。
这就是希尔排序的思想,希尔排序可以说是插入排序的增强版。先预排一下,让序列接近有序。再用插入排序,那么这样子效率可以提升很多。
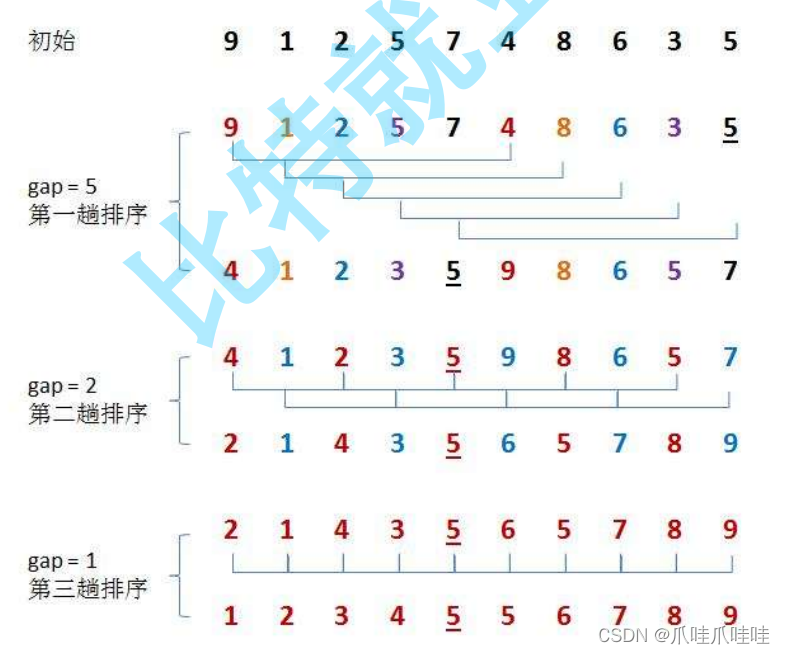
当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。
2.2代码实现
void ShellSort(int arr[], int size)
{
int gap = size;
while (gap > 1)
{
gap /= 2;
//遍历,间隔为gap的有多组
for (int i = 0; i < size - gap; i++)
{
int end = i;
int temp = arr[end + gap];
//挪数据
while (end >= 0 && arr[end] > temp)
{
arr[end + gap] = arr[end];
end -= gap;
}
arr[end + gap] = temp;
}
}
}2.3时间复杂度分析
gap每次除以2,外层循环logN次
当gap很大时,遍历+挪数据差不多是N次
当gap很小或者等于1时,原本应该是N^2,但此时已经接近有序,差不多也是N次
所以综合看来,时间复杂度是O(N * log N)
2.4最好最坏情况
希尔排序的效率跟? 数据规模, gap取值, 数据特点都有关系,不能一概而论。但希尔排序是一个效率较高的排序算法
3.选择排序
3.1思想
选择排序的思想很简单
第一趟遍历[0, n?- 1], 找出最小的元素,与arr[0]做交换
第二趟遍历[1, n?- 1], 找出最小的元素,与arr[1]做交换
......
第n - 1趟,遍历[n - 2, n - 1],找出最小的元素,与arr[n - 2]做交换
动画演示:
3.2代码实现
此处的代码做了优化,一趟同时选出最大的和最小的,把时间缩短几乎一半,但选择排序效率还是很低,可以说是最差的一个排序方法
void SelectSort(int arr[], int size)
{
int begin = 0, end = size - 1;
while (begin < end)
{
int mini = begin, maxi = end;
for (int i = begin; i <= end; i++)
{
if (arr[i] < arr[mini])
{
mini = i;
}
if (arr[i] > arr[maxi])
{
maxi = i;
}
}
Swap(&arr[mini], &arr[begin]);
if (begin == maxi)
{
maxi = mini;
}
Swap(&arr[maxi], &arr[end]);
++begin;
--end;
}
}3.3时间复杂度分析
第一趟:n?
第二趟:n - 1
.......
第n - 1趟:1
根据等差数列,时间复杂度是O(n^2)
3.4最好最坏情况
选择排序太鸡肋,不管什么情况(尽管本来就有序),时间复杂度都是O(n^2)
4.堆排序
4.1思想
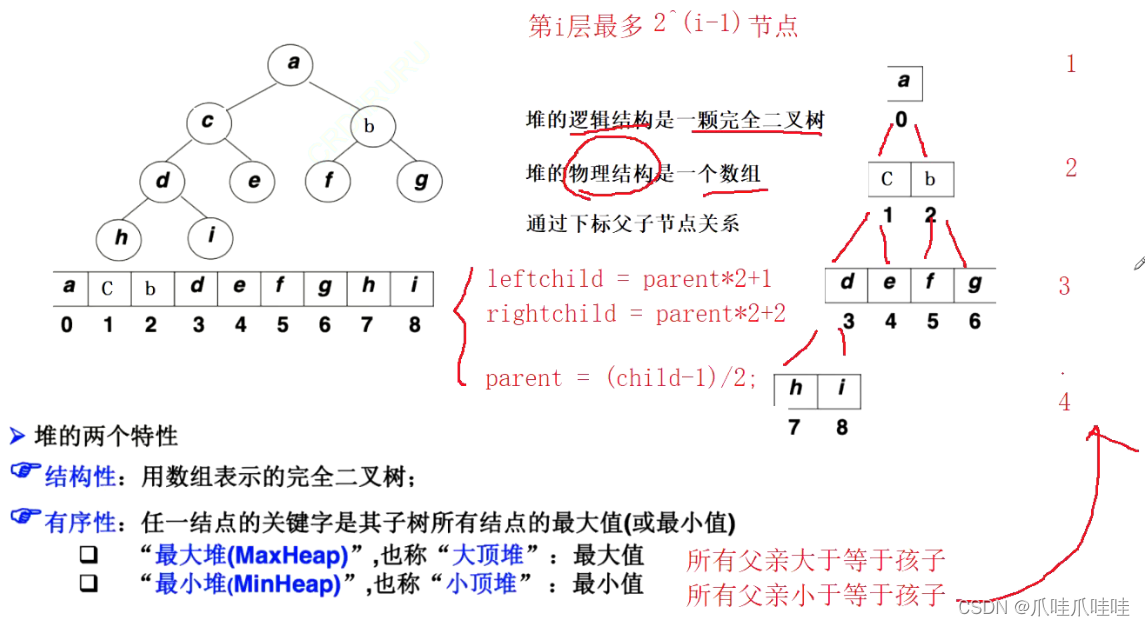
大根堆的堆顶是最大的,小根堆的堆顶是最小的。
通过建堆以及向下调整算法,可以取最大或者最小元素,取出来再找次小或者次大的元素。
这就是堆排序的思路。
4.2代码实现
以升序,建大堆为例。
向解释下什么是向下调整算法:向下调整算法是指,这个堆不一定是大根堆,但堆顶的左右子树都是大根堆,经过调整,使得这个堆变成大根堆。向下调整算法的时间复杂度是O(logN)
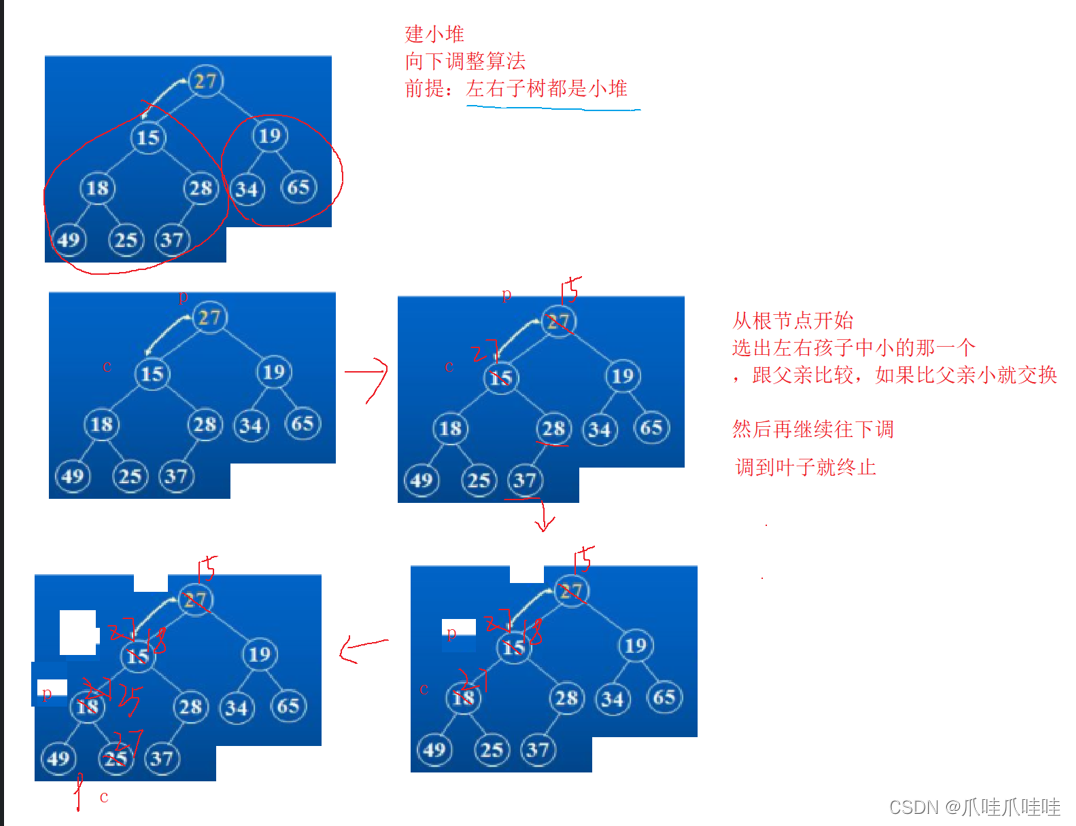
建堆:我们要排序的数组中元素一般是随机的,很难做到堆顶的左右子树都是大堆,那怎么办呢?我们可以从最后一个非叶子节点开始,自下向上使用向下调整算法。建堆的时间复杂度是O(N)
升序为什么建大根堆呢?因为大根堆的堆顶就是最大的元素,只需要把堆顶元素放到最后面,最后面的元素放到堆顶,然后进行向下调整即可,时间复杂度是O(logN)
如果建小堆,把最小值取出来之后,堆的结构全乱了,要重新建堆。如果你要说把最后一个和堆顶交换,排完序之后是降序,再反转数组不就好了。。。建大堆不用反转直接就排好了,何必要反转一下呢?
代码实现:
void AdjustDown(int arr[], int n, int root)
{
int parent = root;
int child = parent * 2 + 1; //初始化为左孩子
while (child < n)
{
//选出左右孩子中大的那一个
if (child + 1 < n && arr[child] < arr[child + 1])
{
child += 1;
}
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
//向下更新
parent = child;
child = parent * 2 + 1;
}
//已经是大堆了
else
{
break;
}
}
}
void HeapSort(int arr[], int size)
{
for (int i = (size - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, size, i);
}
int end = size - 1;
while (end > 0)
{
Swap(&arr[end], &arr[0]);
AdjustDown(arr, end, 0);
end--;
}
}4.3时间复杂度分析
第一次建堆执行N次
向下调整了N-1次,向下调整是O(logN)
所以时间复杂度是O(N*logN)
4.4最好最坏情况
时间复杂度固定是O(N*logN)
5.冒泡排序
5.1思想
冒泡排序是我们最早接触的排序算法,其思想也很简单
从第一个元素开始,两两相比,按照排序方式做交换
第一趟,最大的元素到了最后
第二趟,次大的元素到了次后
.......总共n - 1趟
动画演示:
5.2代码实现
此代码中做了优化,当某一趟一次交换也没有做,那么也就是已经有序了,不需要再冒泡了,直接结束就可以了
void BubbleSort(int arr[], int size)
{
for (int i = 0; i < size - 1; i++)
{
int flag = 1;
for (int j = 0; j < size - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
Swap(&arr[j], &arr[j + 1]);
flag = 0;
}
}
if (flag) return;
}
}5.3时间复杂度分析
第一趟,n - 1
第二趟,n - 2
......
第n - 1趟,1
根据等差数列,时间复杂度是O(n^2)
5.4最好最坏情况
最好:数组有序,遍历一遍就可以了。
最坏:逆序,与上方时间复杂度分析的一样
我们发现冒泡排序和插入排序一样,都是有序的时候是最好的,那么哪个更好一些呢?其实是插入排序更好一些。
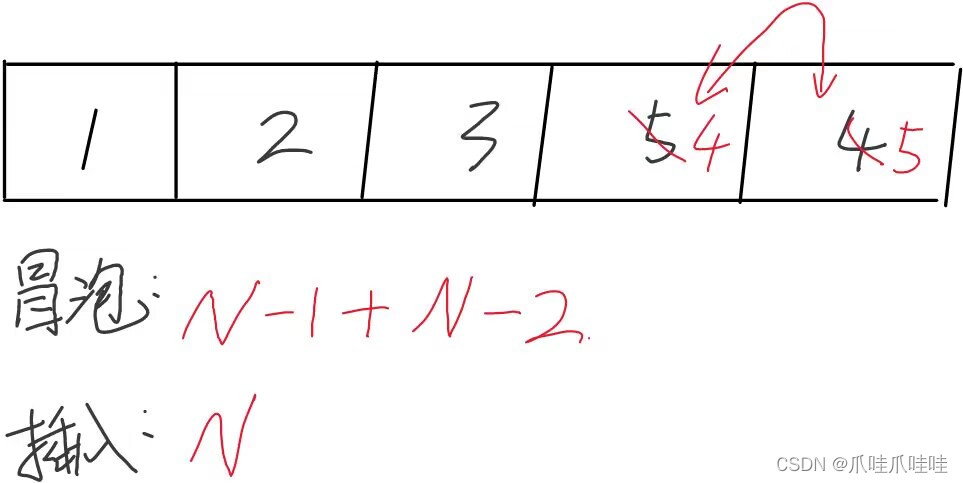
考虑上面这种情况,冒泡排序要进行两趟,第一趟把5放到最后面了,第二趟没有做交换,flag == 1,退出,所以认为执行了N?- 1 + N - 2次
对于插入排序,只进行一趟,执行了N - 1 + 1 = N次 (挪动了一次数据)
除了有序的情况,冒泡排序的效率比选择排序还要低,因为每比较一次都有可能要交换,选择排序只需要一趟只需要交换一次,所以冒泡排序和选择排序都是效率很低的排序算法,不建议使用
6.快速排序
6.1思想
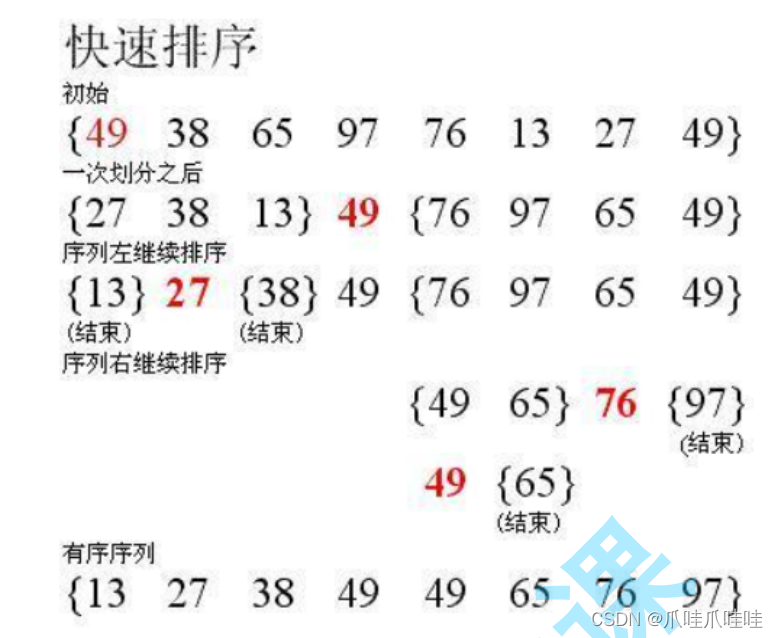
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序 元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有 元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所 有元素都排列在相应位置上为止。?
简单来说,就是每一趟任取一个元素,放到他正确的位置上,左边的全部比他小,右边的全部比他大。左右再分,直到分到左右只剩一个元素。?
快速排序是基于递归的分治算法
6.2代码实现
6.2.1单趟排序
6.2.1.1挖坑法
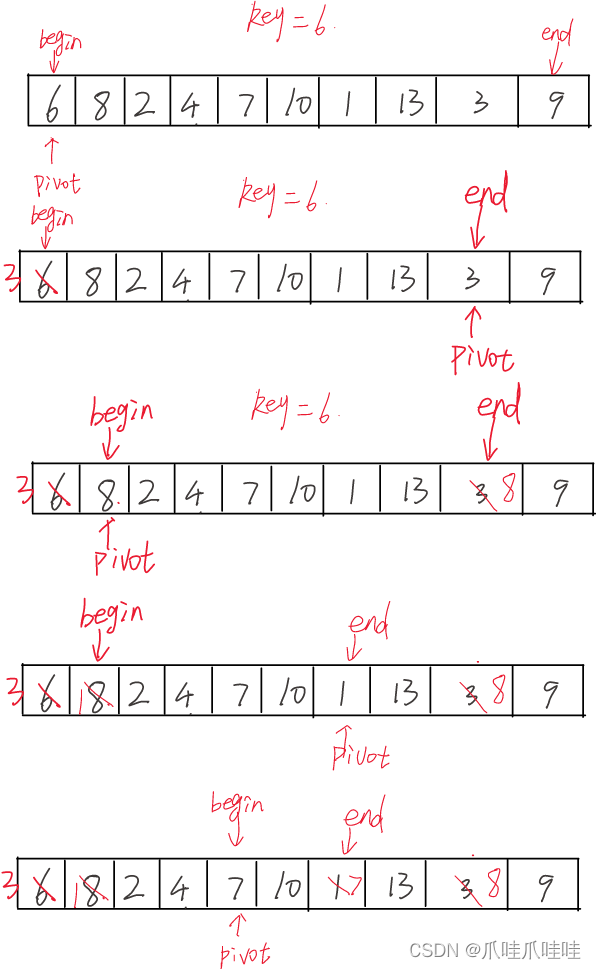
思路:我们让arr[0]做key,pivot(洞)最开始指向arr[0],然后从end向左找比key小的(end--),找到了就让arr[pivot] = arr[end],pivot更新为end。
然后从begin向右找大(begin++),找到了就让arr[pivot] = arr[begin],pivot更新为begin。
pivot指向的位置的值一定覆盖了另一个位置上的值
最终begin end pivot指向同一个位置,把key给给arr[pivot]。
一定要先从end向左找,因为要和覆盖左边的pivot,pivot最开始指向的是arr[0](在最左侧)
代码实现:
int partSort1(int arr[], int left, int right)
{
int begin = left;
int end = right;
int key = arr[begin];
int pivot = begin;
while (begin < end)
{
while (begin < end && arr[end] >= key)
{
end--;
}
arr[pivot] = arr[end];
pivot = end;
while (begin < end && arr[begin] <= key)
{
begin++;
}
arr[pivot] = arr[begin];
pivot = begin;
}
arr[pivot] = key;
return pivot;
}6.2.1.2左右指针法
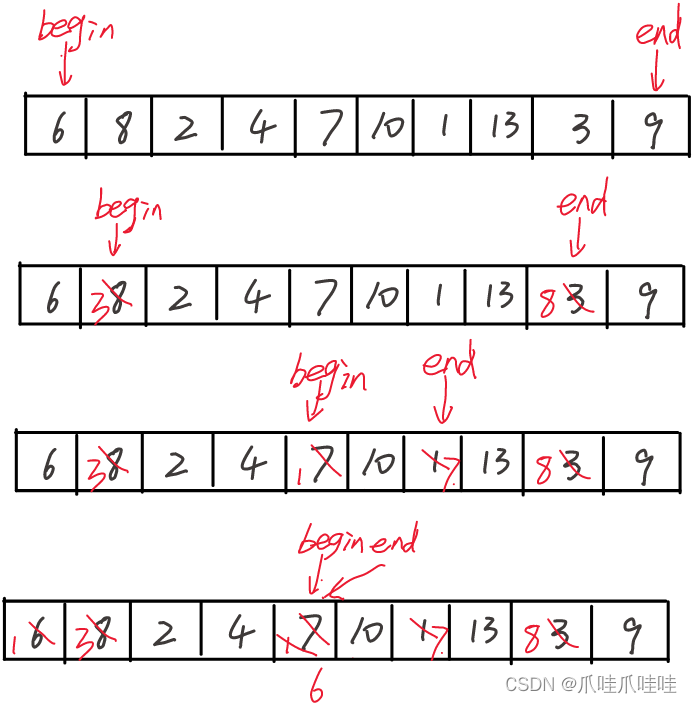
思路:
begin和end最初指向第一个和最后一个元素
end向左找小于key的,找到了停下来
begin向右找大于key的,找到了停下来
交换arr[end]和arr[begin]
......
重复这系列操作,直到begin和end相遇,再把arr[0] 和arr[begin]交换
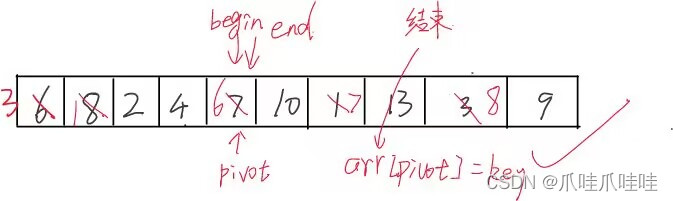
注意:一定是先end向左找再begin向右找,因为这样,无论是end遇到begin还是begin遇到end,他们指向的值一定是比arr[0]小的
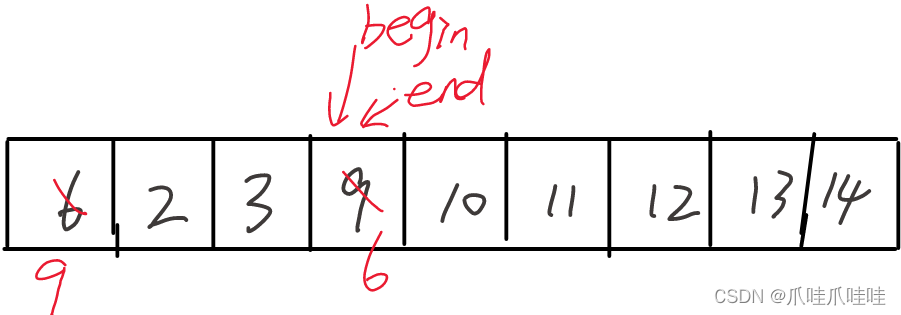
如果先begin向右找,再end向左找,有可能他们相遇时,指向的是大于arr[0] 的,如下图所示
代码实现:
int partSort2(int arr[], int left, int right)
{
int begin = left;
int end = right;
int key = arr[begin];
while (begin < end)
{
while (begin < end && arr[end] >= key)
{
end--;
}
while (begin < end && arr[begin] <= key)
{
begin++;
}
Swap(&arr[end], &arr[begin]);
}
Swap(&arr[left], &arr[begin]);
return begin;
}6.2.1.3前后指针法
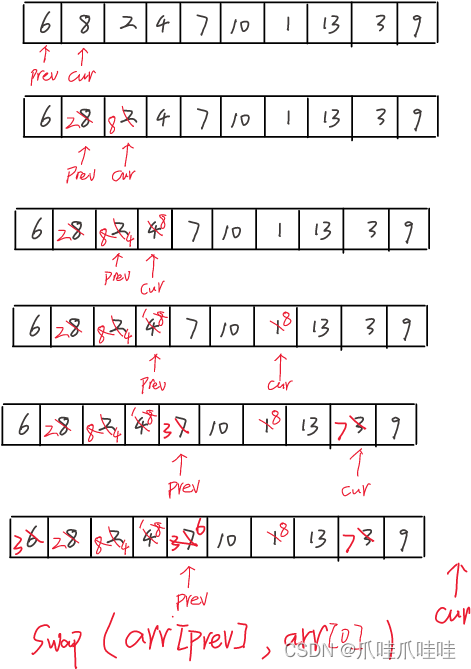
思路:找小的往前仍,大的往后仍。
代码实现:
int partSort3(int arr[], int left, int right)
{
int prev = left;
int cur = left + 1;
while (cur <= right)
{
//cur 和 prev一样就没必要交换了,前几个都是比key小的时候会发生这种情况
if (arr[cur] < arr[left] && ++prev != cur)
{
Swap(&arr[prev], &arr[cur]);
}
++cur;
}
Swap(&arr[prev], &arr[left]);
return prev;
}6.2.2整体代码
void QuickSort(int arr[], int left, int right)
{
if (left >= right)
return;
int keyIndex = partSort1(arr, left, right);
QuickSort(arr, left, keyIndex - 1);
QuickSort(arr, keyIndex + 1, right);
}6.2.3三数取中优化
当数组是有序的时候,递归深度是n - 1,时间复杂度是O(N^2)
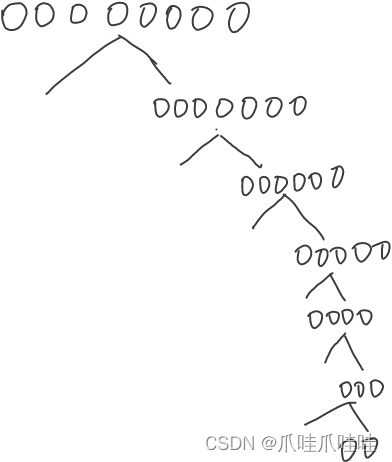
那我们让arr[0] 尽量是平均数,尽量形成完全二叉树,深度从n变成logn,效率会高很多
代码实现:
int getMidIndex(int arr[], int left, int right)
{
int mid = (left + right) >> 1;
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right]) return mid;
else if (arr[right] < arr[left]) return left;
else return right;
}
else
{
if (arr[mid] > arr[right]) return mid;
else if (arr[right] > arr[left]) return left;
else return right;
}
}6.2.4小区间优化:
分治分治分分分,最后左右两边仅剩很少的元素时,这时考虑这个小区间直接使用插入排序,因为元素个数少,这时的插入排序速度不比快速排序慢,甚至要更快(因为近似有序),下面是几个原因:
1.部分有序性:在实际情况下,许多数组在某种程度上是部分有序的,即某些元素已经接近它们的最终排序位置。插入排序对于部分有序的数组表现良好,因为它只需要少量的操作来将一个元素插入到已排序部分,而不需要重新排列整个数组,可能会比快速排序效率高
2.低开销:插入排序是一种简单的算法,不需要递归调用或分割数组,这减少了额外的开销。快速排序等分而治之的算法在小数组上可能需要更多的递归调用和分割操作,这些操作会引入额外的开销。
3.缓存友好性:插入排序通常对计算机的缓存友好,因为它在原地排序数组,而且只涉及相邻元素的比较和交换。这有助于减少缓存未命中和数据移动的成本,从而提高排序性能。
最终代码实现:
void QuickSort(int arr[], int left, int right)
{
if (left >= right)
return;
//三数取中
int index = getMidIndex(arr, left, right);
Swap(&arr[left], &arr[index]);
int keyIndex = partSort1(arr, left, right);
//小区间优化
if (keyIndex - 1 - left > 10)
{
QuickSort(arr, left, keyIndex - 1);
}
else
{
InsertSort(arr + left, keyIndex - 1 - left + 1);
}
if (right - keyIndex - 1 > 10)
{
QuickSort(arr, keyIndex + 1, right);
}
else
{
InsertSort(arr + keyIndex + 1, right - keyIndex - 1 + 1);
}
/*QuickSort(arr, left, keyIndex - 1);
QuickSort(arr, keyIndex + 1, right);*/
}6.3时间复杂度分析
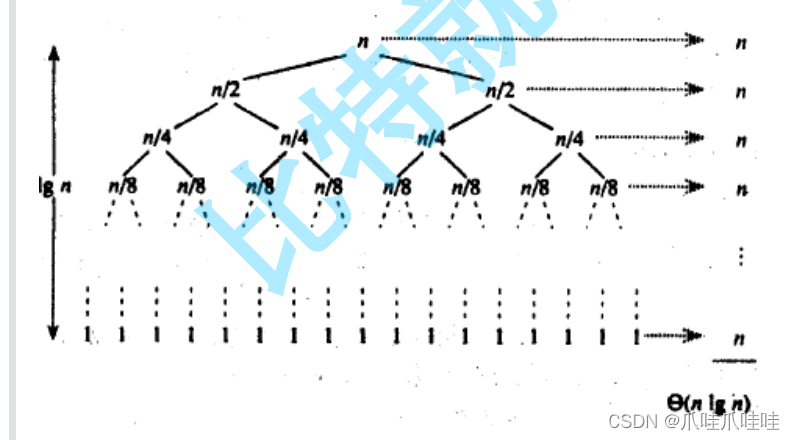
共logn层,每层执行n次,时间复杂度为O(N*logN)
6.4最好最坏情况
最坏的情况是有序,时间复杂度O(N^2),三数取中可以避免这个情况
最好情况是完全二叉树,时间复杂度O(N * logN)
6.5非递归实现
有时递归深度太深,会导致栈溢出。
所以我们用数据结构中的栈模拟操作系统中的栈,因为两者都有先进后出的特性
代码实现:
#include "Sort.h"
#include <stack>
#include <iostream>
using namespace std;
typedef pair<int, int> PI;
//前后指针法
int partSort(int arr[], int left, int right)
{
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (arr[cur] < arr[left] && ++prev != cur)
{
Swap(&arr[prev], &arr[cur]);
}
++cur;
}
Swap(&arr[prev], &arr[left]);
return prev;
}
void QuickSortNonR(int arr[], int left, int right)
{
stack<pair<int, int>> st;
PI p1(left, right);
st.push(p1);
while (!st.empty())
{
int left = st.top().first;
int right = st.top().second;
st.pop();
int keyIndex = partSort(arr, left, right);
//[left, keyIndex - 1], keyIndex, [keyIndex + 1, right]
if (keyIndex + 1 < right)
{
PI pright(keyIndex + 1, right);
st.push(pright);
}
if (left < keyIndex - 1)
{
PI pleft(left, keyIndex - 1);
st.push(pleft);
}
}
}7.归并排序
7.1思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法 (Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序 列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。?
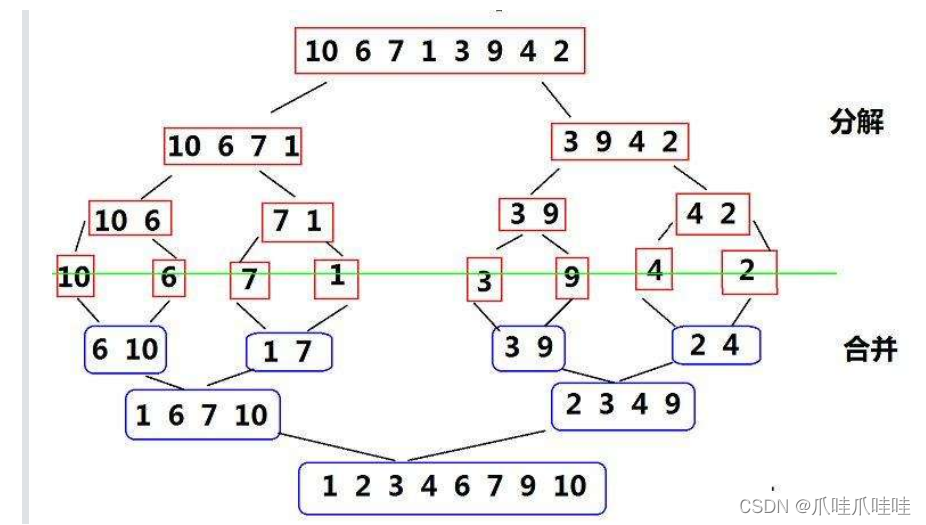
7.2代码实现
分解过程:假设有数组中八个元素,分为左右各四个,左右再分成左右各两个,最后分为左右各一个
合并过程:如上图,左右两个元素,合并成一个有序的? ?只有两个元素的数组。
两个这种数组合并成一个有序的? 含四个元素的数组。
两个这样的数组合并成一个有序的? 含全部元素的数组。
排序完成
需要创建一个临时数组存储有序的小区间。再把临时数组的值赋给原数组。
#include "Sort.h"
void _MergeSort(int arr[], int tmp[], int left, int right)
{
if (left >= right)
{
return;
}
int mid = (left + right) >> 1;
_MergeSort(arr, tmp, left, mid);
_MergeSort(arr, tmp, mid + 1, right);
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] > arr[begin2])
{
tmp[index++] = arr[begin2++];
}
else
{
tmp[index++] = arr[begin1++];
}
}
while (begin1 <= end1)
{
tmp[index++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = arr[begin2++];
}
for (int i = left; i <= right; i++)
{
arr[i] = tmp[i];
}
}
void MergeSort(int arr[], int size)
{
int* tmp = (int*)malloc(sizeof(int) * size);
_MergeSort(arr, tmp, 0, size - 1);
free(tmp);
}7.3时间复杂度分析
总共有logN层,每层比较n次,时间复杂度是O(N * logN)
7.4最好最坏情况
归并排序必须要分解到只剩一个元素,再比较排序,所以没有最好最坏情况,时间复杂度都是O(N*logN)
8.计数排序
8.1思想
计数排序是非比较排序算法,其基本思想是创建一个数组,这个数组的长度是这个序列中最大元素的值。(可以优化)
统计每个元素arr[i]出现了多少次,记录到count[arr[i]]中。
从count[0] 开始,根据里面统计的出现了多少次,赋值给原数组。
8.2代码实现
void CountSort(int arr[], int size)
{
//找到最大最小值,确定范围,方便映射
//映射是指,比如说原数组元素是2 3 4。那么计数数组只需要开3个大小,对应0 1 2
int maxi = arr[0], mini = arr[0];
for (int i = 1; i < size; i++)
{
if (arr[i] > maxi) maxi = arr[i];
if (arr[i] < mini) mini = arr[i];
}
int range = maxi - mini + 1;
int* count = (int*)malloc(sizeof(int) * range);
//先初始化为0
for (int i = 0; i < range; i++)
{
count[i] = 0;
}
//统计个数
for (int i = 0; i < size; i++)
{
count[arr[i] - mini]++;
}
//赋给原数组
for (int i = 0, j = 0; i < range; i++)
{
while (count[i] > 0)
{
arr[j++] = i + mini;
count[i]--;
}
}
free(count);
}8.3时间复杂度分析
找最大最小值,统计次数,?执行了N次
初始化,赋给原数组 执行了range次
所以时间复杂度O(N + range)
8.4最好最坏情况
计数排序的时间复杂度也是固定的
但是计数排序有一些局限性:
1.只能操作整数
2.如果元素间隔非常大,那是计数排序是很慢的,比如数组中只有两个值,【0, 10^9】,计数排序执行了几乎10^9次,而别的排序方法只需要比较一次即可
所以计数排序对间隔非常大的序列排序是非常慢的,对于间隔很小的序列排序是非常快的。
稳定性分析
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记 录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍 在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
冒泡排序:稳定。因为可以控制,当两个值相等时不交换
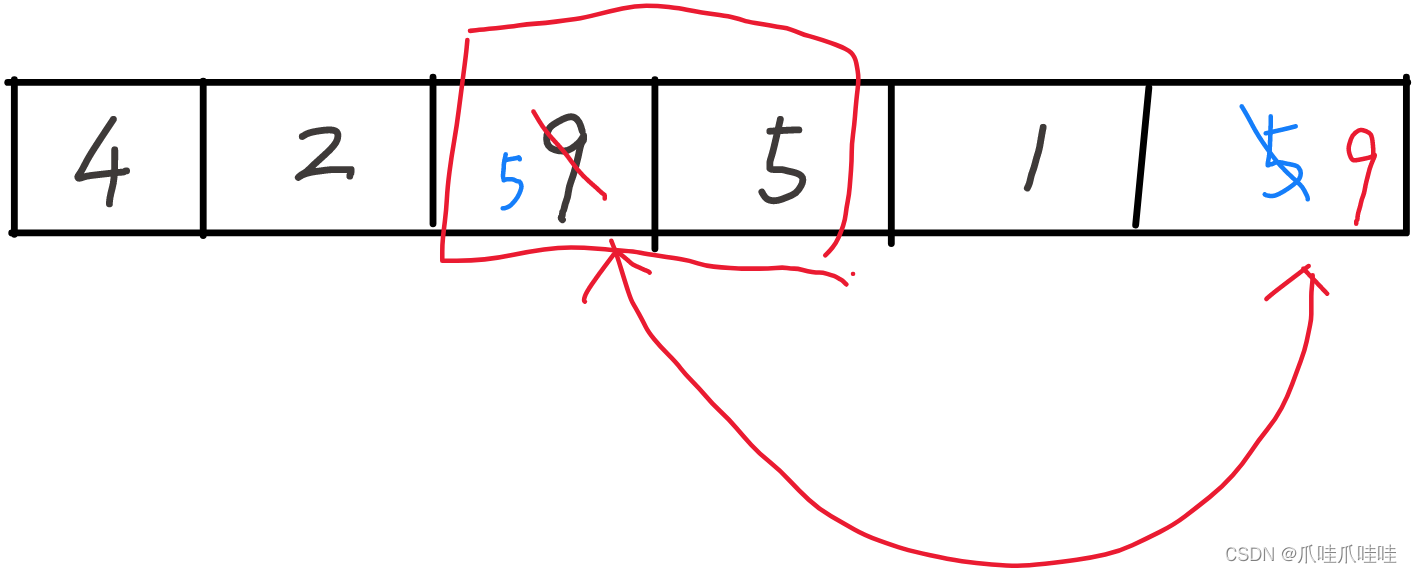
选择排序:不稳定。交换的时候可能把原来的相对位置打乱了。如图,原来蓝5在黑5右边,交换后蓝5在黑5左边
插入排序:稳定。遇到相同的不挪就可以了
希尔排序:不稳定。预排序时相同的值分到了不同的组,可能会不稳定,如图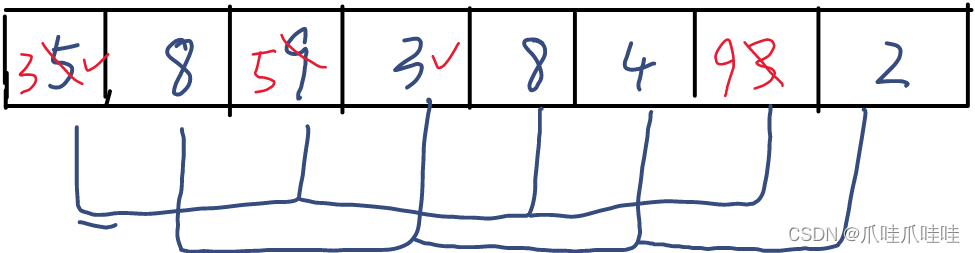
堆排序:不稳定。建好堆之后第一个元素和最后一个元素交换时,可能会导致不稳定
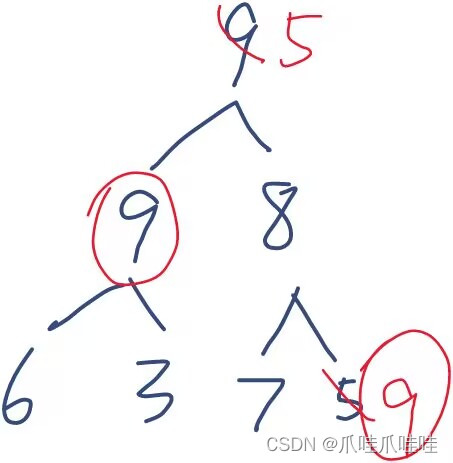
归并排序:稳定。让左边组的先下来,就是稳定的
快速排序:不稳定。考虑一个简单的例子:[3, 2, 3, 1, 4],经过一次快速排序后可能变成 [1, 2, 3, 3, 4]。可以看到,原来在数组中位置靠前的元素3和原来位置靠后的元素3的相对顺序发生了变化。
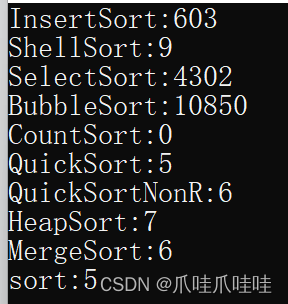
附运行时间图,方便大家比较
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- YoloV8改进策略:Agent Attention|Softmax与线性注意力的融合研究|有效涨点|代码注释与改进|全网首发(唯一)
- 【ACL 2023】 The Art of Prompting Event Detection based on Type Specific Prompts
- 酒店预订订房小程序源码系统+多商户入驻 完全开源可二开 附带完整的搭建教程
- 目标检测YOLO实战应用案例100讲-基于深度学习的实时车道线与目标检测多任务实现(中)
- 打开任务管理器的13种方法,总有一款适合你
- spring常用注解(一)springbean生命周期类
- js shift方法的使用
- Typora(morkdown编辑器)的安装包和安装教程
- C++期末复习总结继承
- 35岁了,怎么办?