Java中的Stream流收集器
目录
????????Java 中 Stream 流用来帮助处理集合,类似于数据库中的操作。
? ? ? ? 在 Stream 接口中,有一个抽象方法 collect,你会发现 collect 是一个归约操作(高级规约),就像 reduce 一样可以接受各种做法作为参数,将流中的元素累积成一个汇总结果。具体的做法可以通过Collector 接口来定义。// collect和reduce都是Stream接口中的汇总方法,collect方法接收一个Collector(收集器)作为参数
????????收集器(Collector)非常有用,Collector 接口中方法的实现决定了如何对流执行归约操作。//收集器用来定义收集器如何收集数据
????????一般来说,Collector 会对元素应用一个转换函数,并将结果累积在一个数据结构中,从而产生这一过程的最终输出。
????????Collectors 实用类提供了很多静态工厂方法,可以方便地创建常见收集器的实例,所以只要拿来用就可以了。最直接和最常用的收集器比如?toList、toSet、toMap 等静态方法。
1、归约和汇总
????????使用?Collectors 进行规约和汇总,比如统计汇总,查找最大值和最小值,拼接字符串等。
????????本节示例会使用到如下代码:
public class Dish {
private final String name;
private final boolean vegetarian;
private final int calories;
private final Type type;
public Dish(String name, boolean vegetarian, int calories, Type type) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
}
public String getName() {
return name;
}
public boolean isVegetarian() {
return vegetarian;
}
public int getCalories() {
return calories;
}
public Type getType() {
return type;
}
public enum Type {MEAT, FISH, OTHER}
@Override
public String toString() {
return name;
}
public static final List<Dish> menu = Arrays.asList(
new Dish("pork", false, 800, Type.MEAT),
new Dish("beef", false, 700, Type.MEAT),
new Dish("chicken", false, 400, Type.MEAT),
new Dish("french fries", true, 530, Type.OTHER),
new Dish("rice", true, 350, Type.OTHER),
new Dish("season fruit", true, 120, Type.OTHER),
new Dish("pizza", true, 550, Type.OTHER),
new Dish("prawns", false, 400, Type.FISH),
new Dish("salmon", false, 450, Type.FISH));
}????????汇总操作:Collectors 类专门为汇总提供了一些工厂方法,用来满足各种类型的统计需要。
public static void main(String[] args) {
//1、计数
Long count0 = menu.stream().collect(Collectors.counting());
long count1 = menu.stream().count();
//2、汇总和
Integer summingInt = menu.stream().collect(Collectors.summingInt(Dish::getCalories));
//3、求平均数
Double averagingInt = menu.stream().collect(Collectors.averagingInt(Dish::getCalories));
//4、一次性求:计数量、总和、最大值、最小值、平均值
IntSummaryStatistics statistics = menu.stream().collect(Collectors.summarizingInt(Dish::getCalories));
//使用统计后的值
double average = statistics.getAverage();
long sum = statistics.getSum();
int max = statistics.getMax();
int min = statistics.getMin();
long count = statistics.getCount();
}? ? ? ? 上述示例中,使用 summarizingInt 工方法返回的收集器功能很强大,通过一次 summarizing 操作你就可以统计到元素的个数,并得到总和、平均值、最大值和最小值。
????????查找流中的最大值和最小值:Collectors.maxBy 和 Collectors.minBy,来计算流中的最大或最小值。这两个收集器接收一个 Comparator 参数来比较流中的元素。
public static void main(String[] args) {
//比较器
Comparator<Dish> comparator = Comparator.comparing(Dish::getCalories);
//收集器
Optional<Dish> collect = menu.stream().collect(Collectors.maxBy(comparator));
}????????连接字符串:joining 工厂方法返回的收集器会把对流中每一个对象应用 tostring 方法得到的所有字符串连接成一个字符串。如下所示:
String joining = menu.stream().map(Dish::getName).collect(Collectors.joining(","));
//joining:
pork,beef,chicken,french fries,rice,season fruit,pizza,prawns,salmon????????广义的规约汇总:事实上,前边所有的收集器,都是一个可以用 reducing 工厂方法定义的归约过程的特殊情况而已。Collectors.reducing 工厂方法是所有这些特殊情况的一般化。如下所示:
public static void main(String[] args) {
//1、计数
Long count0 = menu.stream().collect(Collectors.counting());
Integer count1 = menu.stream().map(i -> 1).collect(Collectors.reducing(0, (a, b) -> a + b));
//2、汇总和
Integer summingInt = menu.stream().collect(Collectors.summingInt(Dish::getCalories));
Integer sum = menu.stream().map(Dish::getCalories).collect(Collectors.reducing(0, (a, b) -> a + b));
//3、求最大值
Optional<Dish> max0 = menu.stream().collect(Collectors.maxBy(Comparator.comparing(Dish::getCalories)));
Optional<Dish> max1 = menu.stream().collect(Collectors.reducing((a, b) -> a.calories > b.calories ? a : b));
}????????到此,你可能想知道,Stream接口的 collect 和 reduce 方法有何不同?因为两种方法通常会获得相同的结果。
????????这个区别在于,reduce 方法旨在把两个值结合起来生成一个新值,它是一个不可变的归约。与此相反,collect 方法的设计就是要改变容器,从而累积要输出的结果。//语义上的区别
????????怎么理解这个区别呢?来看一段滥用 reduce 方法的代码:
public static void main(String[] args) {
Stream<Integer> stream = Arrays.asList(1, 2, 3, 4, 5, 6).stream();
List<Integer> numbers = stream.reduce(new ArrayList<Integer>(), //1、初始值:List
(List<Integer> list, Integer e) -> { //2、转换函数:将Integer变为->List
list.add(e);
return list;
},
(List<Integer> list1, List<Integer> list2) -> {//3、累计函数:多个List合并成一个List
list1.addAll(list2);
return list1;
});
System.out.println(numbers); //[1, 2, 3, 4, 5, 6]
}????????上面的代码片段是在滥用 reduce 方法,因为它在原地改变了作为累加器的 List。//不能说上边方法错误,但是看起来有点炫技的意思,代码很复杂,做的事情却很少,而且使用并发流时还会存在线程安全问题
????????同样的问题,对比下 collect 方法的实现,你会发现非常的简单:
public static void main(String[] args) {
Stream<Integer> stream = Arrays.asList(1, 2, 3, 4, 5, 6).stream();
List<Integer> numbers = stream.collect(Collectors.toList());
}? ? ? ? 一般来说,函数式编程通常会提供了多种方法来执行同一个操作。所以,我们需要根据情况选择最佳解决方案。收集器在某种程度上比 Stream 接口上直接提供的方法用起来更复杂,但好处在于它们能提供更高水平的抽象和概括,也更容易重用和自定义。
2、分组
????????数据库中一个常见操作是根据一个或多个属性对集合中的项目进行分组。
? ? ? ? 简单分组:用?Collectors.groupingBy?工厂方法返回的收集器就可以轻松地完成这项任务,如下所示:
public static void main(String[] args) {
//1、简单分组
Map<Type, List<Dish>> grouping0 = menu.stream().collect(Collectors.groupingBy(Dish::getType));
//2、自定义分组条件
Map<String, List<Dish>> grouping1 = menu.stream().collect(Collectors.groupingBy(r -> {
if (r.getCalories() <= 400) {
return "低热量";
} else if (r.getCalories() <= 700) {
return "普通";
} else {
return "高热量";
}
}));
System.out.println(grouping1);
}
//1、简单分组
{MEAT=[pork, beef, chicken], OTHER=[french fries, rice, season fruit, pizza], FISH=[prawns, salmon]}
//2、自定义分组条件
{普通=[beef, french fries, pizza, salmon], 低热量=[chicken, rice, season fruit, prawns], 高热量=[pork]}????????多级分组:Collectors.groupingBy 工厂方法创建的收集器,它除了普通的分类函数之外,还可以接受 Collector 类型的第二个参数。那么要进行多级分组的话,就可以把一个内层 groupingBy 传递给外层 groupingBy,如下所示:
public static void main(String[] args) {
Map<Type, Map<String, List<Dish>>> grouping = menu.stream().collect(
Collectors.groupingBy(Dish::getType, //一级分类函数
Collectors.groupingBy(r -> { //二级分类函数
if (r.getCalories() <= 400) {
return "低热量";
} else if (r.getCalories() <= 700) {
return "普通";
} else {
return "高热量";
}
})));
//分组:
{
FISH={普通=[salmon], 低热量=[prawns]},
MEAT={普通=[beef], 低热量=[chicken], 高热量=[pork]},
OTHER={普通=[french fries, pizza], 低热量=[rice, season fruit]}
}????????按子组收集数据:上边可以把第二个 groupingBy 收集器传递给外层收集器来实现多级分组。但是,传递给第一个 groupingBy 的第二个收集器可以是任何类型,而不一定是另一个 groupingBy,如下所示:
public static void main(String[] args) {
//1、简单分组
Map<Type, List<Dish>> groupingBy = menu.stream().collect(Collectors.groupingBy(Dish::getType));
//2、分组后计数
Map<Type, Long> collect0 = menu.stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.counting()));
//3、分组后获取最大值
Map<Type, Optional<Dish>> collect1 = menu.stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.maxBy(Comparator.comparing(Dish::getCalories))));
//4、分组后获取最大值
Map<Type, Dish> collect2 = menu.stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.collectingAndThen(
Collectors.maxBy(Comparator.comparing(Dish::getCalories)), Optional::get)));
//5、分组后按名称倒序排序
Map<Type, List<Dish>> collect3 = menu.stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.collectingAndThen(
Collectors.toList(),
list -> list.stream().sorted(Comparator.comparing(Dish::getName).reversed()).collect(Collectors.toList()))));
//6、分组后更该返回映射
Map<Type, Set<String>> collect4 = menu.stream().collect(Collectors.groupingBy(Dish::getType, Collectors.mapping(r -> {
if (r.getCalories() <= 400) {
return "低热量";
} else if (r.getCalories() <= 700) {
return "普通";
} else {
return "高热量";
}
}, Collectors.toSet())));
}
//1、简单分组:{MEAT=[pork, beef, chicken], OTHER=[french fries, rice, season fruit, pizza], FISH=[prawns, salmon]}
//2、分组后计数:{MEAT=3, OTHER=4, FISH=2}
//3、分组后获取最大值:{OTHER=Optional[pizza], FISH=Optional[salmon], MEAT=Optional[pork]}
//4、分组后获取最大值:{OTHER=pizza, FISH=salmon, MEAT=pork}
//5、分组后按名称倒序排序:{MEAT=[pork, chicken, beef], OTHER=[season fruit, rice, pizza, french fries], FISH=[salmon, prawns]}
//6、分组后更该返回映射:OTHER=[普通, 低热量], FISH=[普通, 低热量], MEAT=[普通, 低热量, 高热量]}????????这里要注意一下,普通的单参数 groupingBy(f)(其中 f 是分类函数)实际上是 groupingBy(f,toList()) 的简便写法。
3、分区
????????分区是分组的特殊情况,由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函数。分区函数返回一个布尔值,这意味着得到的分组 Map 的键类型是 Boolean,于是它最多可以分为两组——true是一组,false是一组。
//1、分区
Map<Boolean, List<Dish>> partitioningBy = menu.stream().collect(Collectors.partitioningBy(Dish::isVegetarian));
//2、分区后分组
Map<Boolean, Map<Type, List<Dish>>> collect = menu.stream().collect(Collectors.partitioningBy(Dish::isVegetarian,
Collectors.groupingBy(Dish::getType)));
//1、分区:{false=[pork, beef, chicken, prawns, salmon], true=[french fries, rice, season fruit, pizza]}
//2、分区后分组:{false={FISH=[prawns, salmon], MEAT=[pork, beef, chicken]}, true={OTHER=[french fries, rice, season fruit, pizza]}}????????//分区即是一种特殊的分组,也可以看成是一个保留过滤元素的过滤操作
4、理解收集器接口
????????Collector 接口包含了一系列方法,为实现具体的归约操作(即收集器)提供了范本。Collector 接口中实现的许多收集器,例如 toList 或 groupingBy,这也意味着我们可以为 Collector 接口提供自己的实现,从而自由地创建自定义归约操作。
????????首先看看 Collector 接口的定义,它列出了接口的签名以及声明的五个方法。
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
}- T 是流中要收集的项目的泛型。
- A 是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。
- R 是收集操作得到的对象(通常但并不一定是集合)的类型。
????????分析 Collector 接口声明的五个方法,你会发现前四个方法都会返回一个会被 collect 方法调用的函数,而第五个方法 characteristics 则提供了一系列特征,也就是一个提示列表,告诉 collect 方法在执行归约操作的时候可以应用哪些优化。//四个操作函数 + 一个特征值列表
????????(1)建立新的结果容器:supplier 方法
????????Supplier 方法在调用时它会创建一个空的累加器实例,供数据收集过程使用。在对空流执行操作的时候,这个空的累加器也代表了收集过程的结果。//所以lambda收集后不会出现Null的情况
public Supplier<List<T>> supplier() {
return () -> new ArrayList<T>(); //提供一个集合作为累加器实例
}????????(2)将元素添加到结果容器:accumulator 方法
????????accumulator 方法会返回执行归约操作的函数。该函数将返回 void,因为累加器是原位更新,即函数的执行改变了它的内部状态以体现遍历的元素的效果。比如,把当前元素添加至已经遍历过的元素的列表://定义如何把流中的元素放到累加器中
public BiConsumer<List<T>, T> accumulator() {
return (list, element) -> list.add(element); //定义归约操作
}????????(3)对结果容器应用最终转换:finisher方法
????????在遍历完流后,finisher 方法必须返回在累积过程的最后要调用的一个函数,以便将累加器对象转换为整个集合操作的最终结果。如果累加器对象恰好与预期的最终结果符合,就无需进行转换。//累加器的对象类型为T,期待返回的最终对象类型也为T,就无需转换?
public Function<List<T>, List<T>> finisher() {
return i -> i; //无转换,直接返回
}? ? ? ? 使用以上三个方法就已经足以对流进行顺序归约,这个逻辑流程如下所示:

????????但是为什么还需要另外两个方法呢?答案是并行。
????????(4)合并两个结果容器:combiner方法
????????combiner 方法会返回一个供归约操作使用的函数,它定义了对流的各个子部分进行并行处理时,各个子部分归约所得的累加器要如何合并。//并行时,对子流进行合并处理
public BinaryOperator<List<T>> combiner() {
return (list1, list2) -> {
list1.addAll(list2);
return list1;
};
}????????有了 combiner 方法,就可以对流进行并行归约了。这个流程就像是这样:
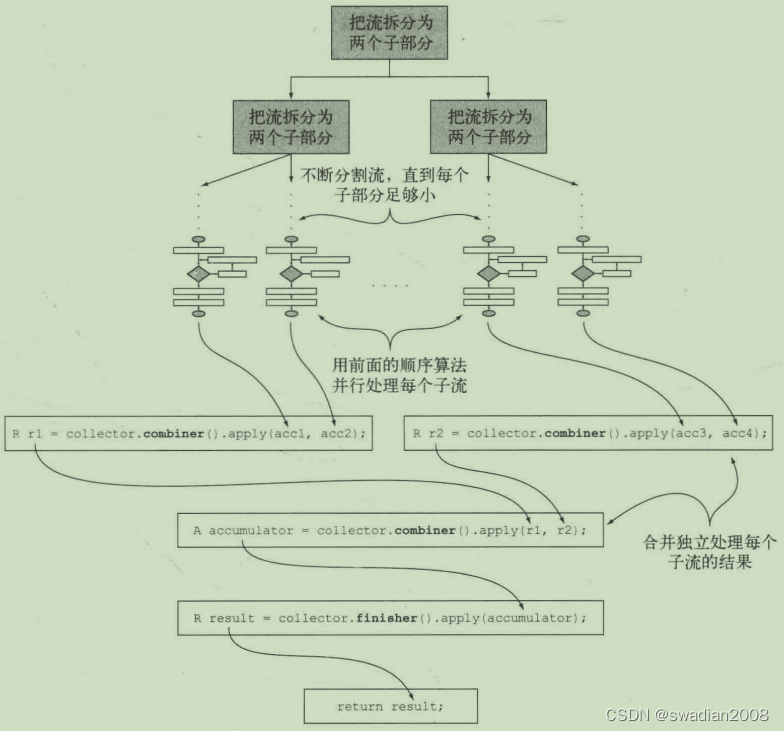
????????(5)特征值列表:characteristics 方法
????????characteristics 会返回一个不可变的 characteristics 集合,它定义了收集器的行为——尤其是关于流是否可以并行归约,以及可以使用哪些优化的提示。Characteristics 是一个包含三个特征值的枚举。
- UNORDERED——归约结果不受流中项目的遍历和累积顺序的影响。//无序
- CONCURRENT——accumulator 函数可以从多个线程同时调用,且该收集器可以并行归约流。如果收集器没有标为 UNORDERED,那它仅在用于无序数据源时才可以并行归约。//并行
- IDENTITY_FINISH——这表明完成器方法返回的函数是一个恒等函数,可以跳过。这种情况下,累加器对象将会直接用作归约过程的最终结果。
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH, CONCURRENT));
}????????至此,收集器的 5 个方法我们都分析完了,然后把上述分析过程的代码组装在一起,就成了一个我们自己定义的?ToList 收集器了,完整的代码如下所示:
import java.util.ArrayList;
import java.util.Collections;
import java.util.EnumSet;
import java.util.List;
import java.util.Set;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
import static java.util.stream.Collector.Characteristics.CONCURRENT;
import static java.util.stream.Collector.Characteristics.IDENTITY_FINISH;
public class ToListCollector<T> implements Collector<T, List<T>, List<T>> {
@Override
public Supplier<List<T>> supplier() {
return () -> new ArrayList<T>();
}
@Override
public BiConsumer<List<T>, T> accumulator() {
return (list, item) -> list.add(item);
}
@Override
public Function<List<T>, List<T>> finisher() {
return i -> i;
}
@Override
public BinaryOperator<List<T>> combiner() {
return (list1, list2) -> {
list1.addAll(list2);
return list1;
};
}
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH, CONCURRENT));
}
}????????接下来,我们使用Java提供和收集器和自己写的收集器测验一下:
public static void main(String[] args) {
List<String> collect0 = menu.stream().map(Dish::getName).collect(Collectors.toList());
List<String> collect1 = menu.stream().map(Dish::getName).collect(new ToListCollector<>());
}????????注意,这里我们需要使用 new 来实例化我们自定义的收集器。对比执行的结果,你会发现两个函数的结果都是一样的,这是因为我们实现的?ToList 收集器,大致上就是 Java 实现ToList 收集器的逻辑,下边是? Java 实现ToList 收集器的源码:
public static <T> Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, //供应源
List::add, //累加器
(left, right) -> { left.addAll(right); return left; }, //组合器
CH_ID); //特征值列表
}? ? ? ? // 上边貌似少了一个 finisher方法,其实这个方法在?CollectorImpl 中给了默认实现,请跟源码
????????最后,对于 IDENTITY_FINISH 的收集操作,还有一种方法可以得到同样的结果而无需从头实现新的 Collectors 接口。Stream 有一个重载的 collect 方法可以接受另外三个函数:supplier、accumulator 和 combiner,其语义和 Collector 接口的相应方法返回的函数完全相同。那么上边的收集操作同样可以写成如下形式:
ArrayList<String> collect2 = menu.stream().map(Dish::getName).collect(
ArrayList::new, //供应源
List::add, //累加器
List::addAll); //组合器????????第二种形式虽然比前一个写法更为紧凑和简洁,却不那么易读。另外值得注意的是,第二种形式中的 collect 方法不能传递任何 characteristics,所以它永远都是一个 IDENTITY_FINISH 和 CONCURRENT 但并非 UNORDERED 的收集器。
????????至此,全文结束。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Kafka与Spring Boot等应用框架的集成及消息驱动模型
- 【Linux】线程的概念理解,从感知理解到全面深入
- 【精选】MyBatis思维导图分享,全是干货,思维导图带代码你们见过吗?
- 江大白|万字长文,深入浅出Transformer,值得收藏!(测试代码已跑通)
- java常见面试题:如何使用Java进行多线程编程和并发控制?
- 亚信安慧AntDB数据库自主研发技术再获国际认可
- K8S动态PV
- 数据库练习题
- zabbix定义报警媒介
- JavaScript总结(三)