深度学习第5天:GAN生成对抗网络
发布时间:2023年12月18日

??主页 Nowl
🔥专栏 《深度学习》
📑君子坐而论道,少年起而行之
??
一、GAN
1.基本思想
想象一下,市面上有许多仿制的画作,人们为了辨别这些伪造的画,就会提高自己的鉴别技能,然后仿制者为了躲过鉴别又会提高自己的伪造技能,这样反反复复,两个群体的技能不断得到提高,这就是GAN的基本思想
2.用途
我们知道GAN的全名是生成对抗网络,那么它就是以生成为主要任务,所以可以用在这些方面
- 生成虚拟数据集,当数据集数量不够时,我们可以用这种方法生成数据
- 图像清晰化,可以将模糊图片清晰化
- 文本到图像的生成,可以训练文生图模型
GAN的用途还有很多,可以在学习过程中慢慢发现
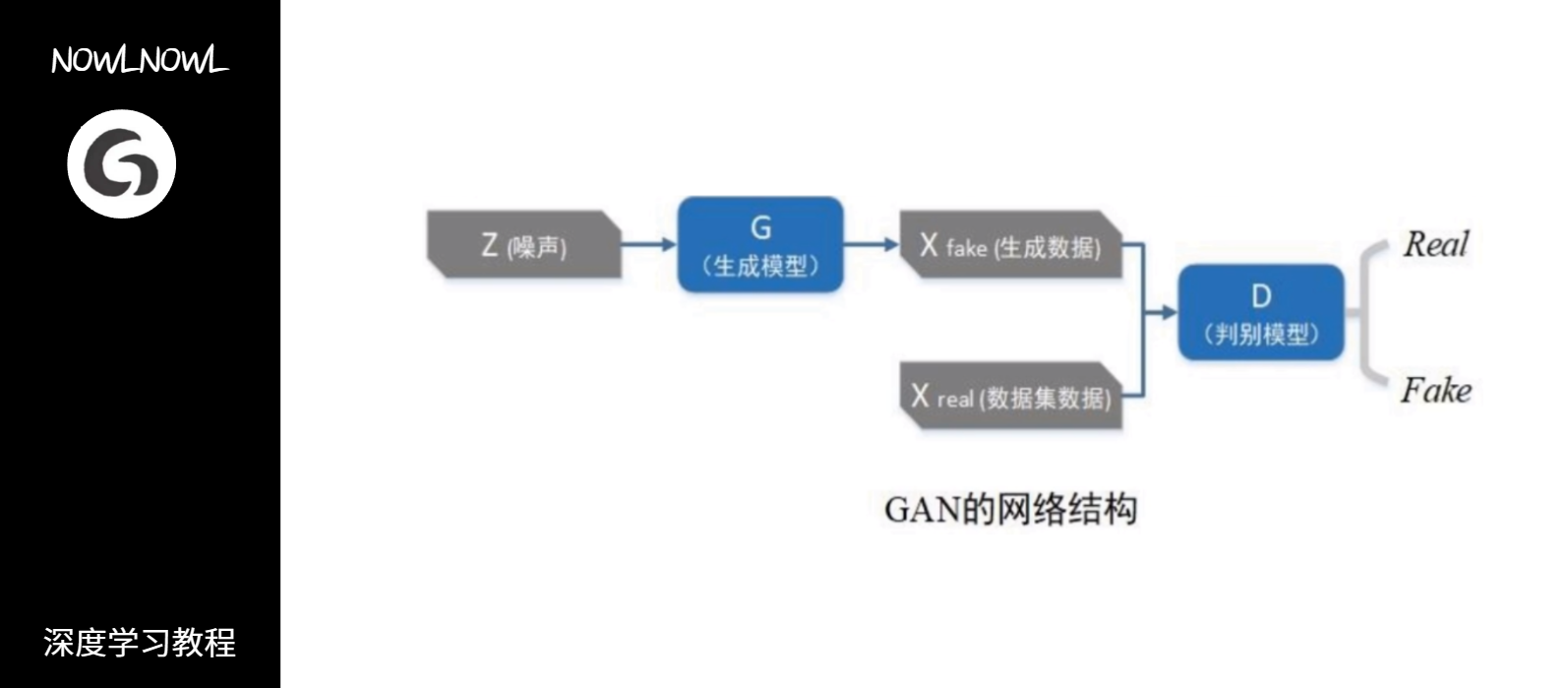
3.模型架构
GAN的主要结构包含一个生成器和一个判别器,我们先输入一堆杂乱数据(被称为噪声)给生成器,接着让判别器将生成器生成的数据与真实的数据作对比,看是否能判别出来,以此往复训练
二、具体任务与代码
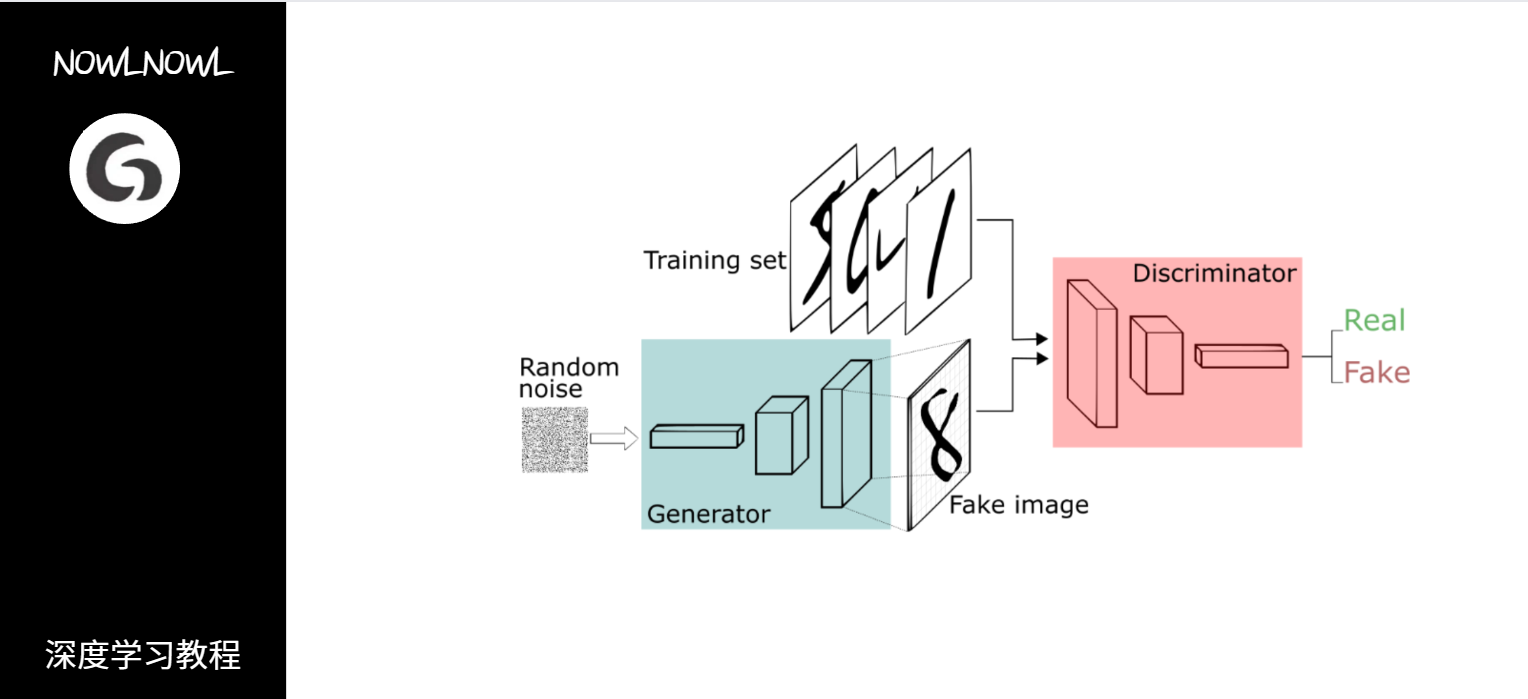
1.任务介绍
相信很多人都对手写数字数据集不陌生了,那我们就训练一个生成手写数字的GAN,注意:本示例代码需要的运行时间较长,请在高配置设备上运行或者减少训练回合数
2.导入库函数
先导入必要的库函数,包括torch用来处理神经网络方面的任务,numpy用来处理数据
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd.variable import Variable
from torchvision import transforms, datasets
import numpy as np
3.生成器与判别器
使用torch定义生成器与判别器的基本结构,这里由于任务比较简单,只用定义线性层就行,再给线性层添加相应的激活函数就行了
# 定义生成器(Generator)和判别器(Discriminator)的简单网络结构
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Tanh()
)
def forward(self, noise):
return self.model(noise)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, image):
return self.model(image)
4.预处理
这一部分定义了模型参数,加载了数据集,定义了损失函数与优化器,这些是神经网络训练时的一些基本参数
# 定义一些参数
batch_size = 100
learning_rate = 0.0002
epochs = 500
# 加载MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
mnist_data = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
data_loader = torch.utils.data.DataLoader(dataset=mnist_data, batch_size=batch_size, shuffle=True)
# 初始化生成器、判别器和优化器
generator = Generator()
discriminator = Discriminator()
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 损失函数
criterion = nn.BCELoss()
5.模型训练
这一部分开始训练模型,通过反向传播逐步调整模型的参数,注意模型训练的过程,观察生成器和判别器分别是怎么在训练中互相作用不断提高的
# 训练 GAN
for epoch in range(epochs):
for data, _ in data_loader:
data = data.view(data.size(0), -1)
real_data = Variable(data)
target_real = Variable(torch.ones(data.size(0), 1))
target_fake = Variable(torch.zeros(data.size(0), 1))
# 训练判别器
optimizer_D.zero_grad()
output_real = discriminator(real_data)
loss_real = criterion(output_real, target_real)
loss_real.backward()
noise = Variable(torch.randn(data.size(0), 100))
fake_data = generator(noise)
output_fake = discriminator(fake_data.detach())
loss_fake = criterion(output_fake, target_fake)
loss_fake.backward()
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
output = discriminator(fake_data)
loss_G = criterion(output, target_real)
loss_G.backward()
optimizer_G.step()
print(f'Epoch [{epoch+1}/{epochs}], Loss D: {loss_real.item()+loss_fake.item()}, Loss G: {loss_G.item()}')
6.图片生成
这一部分再一次随机生成了一些噪声,并把他们传入生成器生成图片,其中包含一些格式转化过程,再通过matplotlib绘图库显示结果
# 生成一些图片
num_samples = 16
noise = Variable(torch.randn(num_samples, 100))
generated_samples = generator(noise)
generated_samples = generated_samples.view(num_samples, 1, 28, 28).detach()
import matplotlib.pyplot as plt
import torchvision.utils as vutils
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title("Generated Images")
plt.imshow(
np.transpose(
vutils.make_grid(generated_samples, nrow=4, padding=2, normalize=True).cpu(), (1, 2, 0)
)
)
plt.show()
7.不同训练轮次的结果对比


文章来源:https://blog.csdn.net/MuRanstr/article/details/134893649
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!