02-黑马程序员大数据开发:分布式计算和分布式资源调度
1. 分布式计算概述
目标:了解什么是计算?什么是分布式计算?
计算是对数据进行处理,使用统计分析等手段得到需要的结果;
分布式计算是多台服务器协同工作,共同完成一个计算任务。
分布式计算模式:分散->汇总模式?(MapReduce)和 中心调度->步骤执行模式(Apache Spark,Flink; 比较复杂,中间会有数据交换的过程);
2. MapReduce概述
MapReduce是Hadoop中的分布式计算组件,可以以“分散->汇总〞模式为分布式计算框架,可供开发人员开发相关程序(Java,Python等语言)进行分布式数据计算。
- Map功能接口:提供了 “分散〞的功能,由服务器分布式对数据进行处理
- Reduce功能接口:提供了 “汇总(聚合)〞的功能,將分布式的处理结果进行统计汇总
(现在基本没人写了,版本太老了,只是对Hive框架做一个铺垫)
MapReduce的运行机制:
- 将要执行的需求,分解为多个Map Task和 Reduce Task
- 将Map Task和 Reduce Task分 配到对应的服务器去执行
3. YARN概述
目标:了解MapReduce和YARN的关系;了解为什么需要资源调度;了解YARN的作用。
1. YARN:Hadoop内提供的进行分布式资源调度的组件,用以做集群的资源(内存、CPU等)调度
? ? ? ? a. ?资源:服务器硬件资源,如CPU、内存、硬盘、网络等
? ? ? ? b. 资源调度:管控服务器硬件资源,提供更好的利用率
? ? ? ? c. 分布式资源调度:?管控整个分布式服务器集群的全部资源,整合进行统一调度
2. 为什么需要资源调度?
?????????将资源统一管控进行分配可以提高资源利用率
3.?程序如何在YARN内运行?
- 程序向YARN申请所需资源
- YARN为程序分配所需资源供程序使用
4.MapReduce和YARN的关系
?? ? ? ?- YARN用来调度资源给MapReduce,分配和管理它所需的运行资源
?? ? ? ?- 所以,MapReduce需要YARN才能运行(普遍情况)
4. YARN架构
4.1 核心架构
目标:1.?掌握YARN的运行角色和角色之间的关系;2.?理解使用容器做资源分配和隔离
1. 主从架构:
ResourceManager:整个集群的资源调度者,负责协调调度各个程序所需的资源;(总经理)
NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。(10个厂的厂长)
2. YARN基于容器精准的给程序开辟资源:根据程序的需求,开辟出来对应的容器:
- 容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段
- 创建一个资源容器,即 由NodeManager占用这部分资源
- 然后应用程序在NodeManager创建的这个容器内运行
- 应用程序无法突破容器的资源限制。
4.2 辅助架构
目标:1. 了解什么是历史服务器?2. 了解什么是代理服务器。
1. YARN的架构除了:ResourceManager集群资源管家和NodeManager单机资源管家
? ? ?还可以搭配两个辅助角色使得YARN集群运行更加稳定:
? ? ? ? a. ?代理服务器:为了减少通过YARN进行基于网络的攻击的可能性;开启代理服务器,能够最大限度保障WEB UI的访问是安全的;?
? ? ? ? ? ? ? ? 默认作为资源管理器RM的一部分进行运行,但是配置在单独模式下运行更安全(见部署环节)。
?? ? ? ?b. 历史服务器:记录YARN历史运行的程序的信息以及产生的日志并提供WEB UI站点供用户使用浏览器查看。
2. ?程序看日志不是日常操作吗?为何需要一个单独的历史服务器?回答这个问题要从YARN的运行机制说起。
YARN在运行时,本质上说是做资源的管控的,开辟容器,程序运行在容器内部,容器之间是隔离的,那么日志也会在容器内部;如果我们想看某一的map的日志比较麻烦,如果有一个历史服务器,就能够将这些零散的map日志搜集到一起存储在HDFS中,让我们可以在浏览器中查看。
?总结:YARN的架构有哪些角色
- 核心角色 : ResourceManager和 NodeManager
- 辅助角色:代理服务器ProxyServer,保障 WEB UI访问的安全性
- 辅助角色:历史服务器JobHistoryServer,记录历史程序运行信息和日志
5. MapReduce&YARN的部署
5.1 完成MapReduce框架的运行配置 和 完成YARN集群的部署
部署说明:??????? ?
?
cd /export/server/hadoop/etc/hadoop/
ll
vim mapred-env.sh
vim mapred-site.xml第三章-06-[实操]YARN集群部署_哔哩哔哩_bilibili
MapReduce配置文件?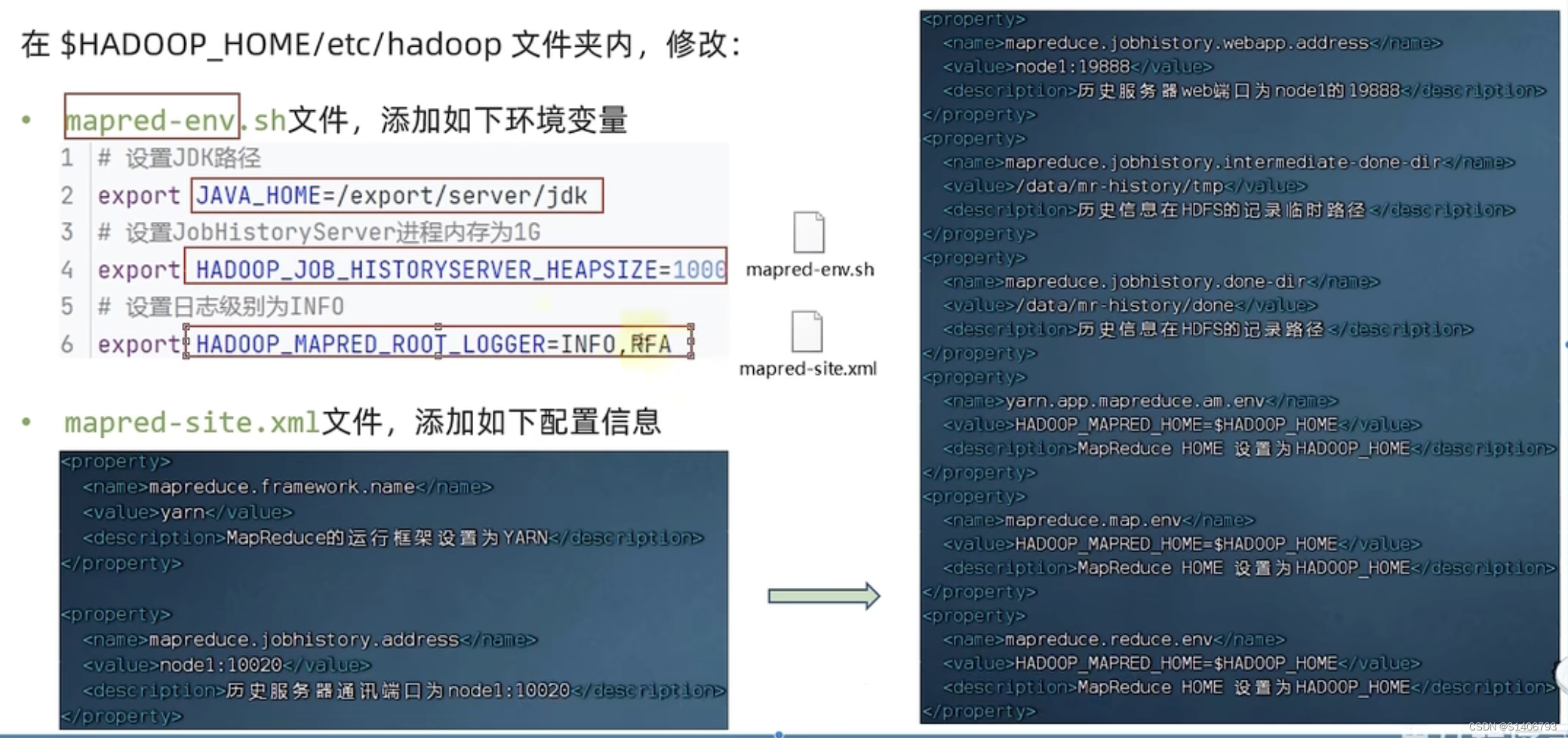
?YARN ??配置文件

集群启动命令介绍



6. MapReduce&YARN初体验
6.1 集群启停命令:掌握集群进程的启停命令
第三章-07-[实操]YARN集群的启停命令_哔哩哔哩_bilibili
6.2 提交MapReduce任务到YARN执行【现在MapReduce代码用的很少】
第三章-08-[实操]提交MapReduce任务到YARN执行_哔哩哔哩_bilibili

?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- DPDK单步跟踪(3)-如何利用visual studio 2019和visual gdb来单步调试dpdk
- 协议网关BL110轻松实现多种协议转MQTT、OPC UA,支持8种主流工业协议转换
- nodejs01
- 哪个存储引擎执行 select count(*) 更快
- 极智芯 | 解读自动驾驶芯片之芯驰驾之芯系列
- Python--对于类的一些练习
- 2624. 蜗牛排序
- 力扣长度最小的子数组(c++实现)
- 002-python(8种)基础数据类型(int,float,bool,str)
- tomcat优化