java进阶||jdk进阶之循环
发布时间:2024年01月09日
从18年学java到现在除了各种各样的数据类型和集合烧不了要遍历这些变量, for循环这时就少不了啦(当然还有8后引入的神器泛型)
先来看一段精髓业务代码, 使用了多个新特性当然也少不了循环和分支判断 代码较长解析在后面
private CommonPage<List<Object>> handleStandardAsphaltDiseases(CommonPage<List<AsphaltCementDiseaseInfoDO>> page) {
Set<Map.Entry<String, LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>>>> entrySet = page.getData().stream()
.collect(Collectors.groupingBy(AsphaltCementDiseaseInfoDO::getStakeDataYearMonth, LinkedHashMap::new, Collectors.groupingBy(AsphaltCementDiseaseInfoDO::getDiseaseName, LinkedHashMap::new, Collectors.toList())))
.entrySet();
//遍历entrySet集合
for (Iterator<Map.Entry<String, LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>>>> it = entrySet.iterator(); it.hasNext();) {
Map.Entry<String, LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>>> entry = it.next();
//System.out.println(entry);
}
//for (Map.Entry<String, LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>>> entry : entrySet){
// Map<String, List<AsphaltCementDiseaseInfoDO>> diseaseNameMap = entry.getValue();
// System.out.println(diseaseNameMap);
//}
BigDecimal roadWidth = new BigDecimal("3.75");
List<Object> result = Lists.newArrayList();
for (Map.Entry<String, LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>>> entry : entrySet) {
LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>> diseaseNameMap = entry.getValue();
List<AsphaltCementDiseaseInfoDO> stripRepairs = diseaseNameMap.get(STRIP_REPAIR);
boolean filled = CollectionUtils.isNotEmpty(stripRepairs);
//AsphaltCementDiseaseInfoDO asphaltDo = new AsphaltCementDiseaseInfoDO();
//声明纵裂和横裂两个数组
List<AsphaltCementDiseaseInfoDO> longitudinalCracks = diseaseNameMap.getOrDefault(LONGITUDINAL_CRACK, Lists.newArrayList());
List<AsphaltCementDiseaseInfoDO> transverseCracks = diseaseNameMap.getOrDefault(TRANSVERSE_CRACK, Lists.newArrayList());
if(filled){
for(AsphaltCementDiseaseInfoDO asphalt : stripRepairs){
asphalt.setFilled(Boolean.TRUE);
if (asphalt.getLength().doubleValue() < 4.3){
longitudinalCracks.add(asphalt);
}else {
transverseCracks.add(asphalt);
}
}
}
int minLen = Math.min(longitudinalCracks.size(), transverseCracks.size());
String[] stakeDataYearMonth = entry.getKey().split("\\|");
BigDecimal chapBlockCrack = calculateChapBlockCrackArea(diseaseNameMap);
for (int i = 0; i < minLen; i++) {
StandardAsphaltDiseaseInfoVO standard = StandardAsphaltDiseaseInfoVO.builder()
.dataYearMonth(stakeDataYearMonth[1])
.stake(divide100(Long.valueOf(stakeDataYearMonth[0])))
.roadWidth(roadWidth)
.longitudinalCrack(buildCrack(longitudinalCracks.get(i)))
.transverseCrack(buildCrack(transverseCracks.get(i)))
.lineNo(page.getData().get(i).getLineNo())
.dir(page.getData().get(i).getDir())
.diseaseName(page.getData().get(i).getDiseaseName())
.chapBlockCrack(i == 0 ? chapBlockCrack : null)
.build();
//标准表病害名称细分
if (page.getData().get(i).getDiseaseName().equals("坑槽")){
standard.setPits("坑槽");
}
if (page.getData().get(i).getDiseaseName().equals("泛油")){
standard.setMeshCrack("泛油");
}
if (page.getData().get(i).getDiseaseName().equals("拥包")) {
standard.setPacking("拥包");
}
if (page.getData().get(i).getDiseaseName().equals("网裂")) {
standard.setMeshCrack("网裂");
}
result.add(standard);
}
if(longitudinalCracks.size() > minLen){
int maxLen = longitudinalCracks.size();
for (int i = minLen; i < maxLen; i++) {
StandardAsphaltDiseaseInfoVO standard = StandardAsphaltDiseaseInfoVO.builder()
.dataYearMonth(stakeDataYearMonth[1])
.stake(divide100(Long.valueOf(stakeDataYearMonth[0])))
.roadWidth(roadWidth)
.longitudinalCrack(buildCrack(longitudinalCracks.get(i)))
.transverseCrack(Crack.builder().build())
.lineNo(page.getData().get(i).getLineNo())
.dir(page.getData().get(i).getDir())
.build();
result.add(standard);
}
}
if(transverseCracks.size() > minLen){
int maxLen = transverseCracks.size();
for (int i = minLen; i < maxLen; i++) {
StandardAsphaltDiseaseInfoVO standard = StandardAsphaltDiseaseInfoVO.builder()
.dataYearMonth(stakeDataYearMonth[1])
.stake(divide100(Long.valueOf(stakeDataYearMonth[0])))
.roadWidth(roadWidth)
.longitudinalCrack(Crack.builder().build())
.transverseCrack(buildCrack(transverseCracks.get(i)))
.lineNo(page.getData().get(i).getLineNo())
.dir(page.getData().get(i).getDir())
//.diseaseName(page.getData().get(i).getDiseaseName())
.build();
result.add(standard);
}
}
}
CommonPage<List<Object>> resultPage = page.buildWithoutData();
resultPage.setData(result);
return resultPage;
}
析:
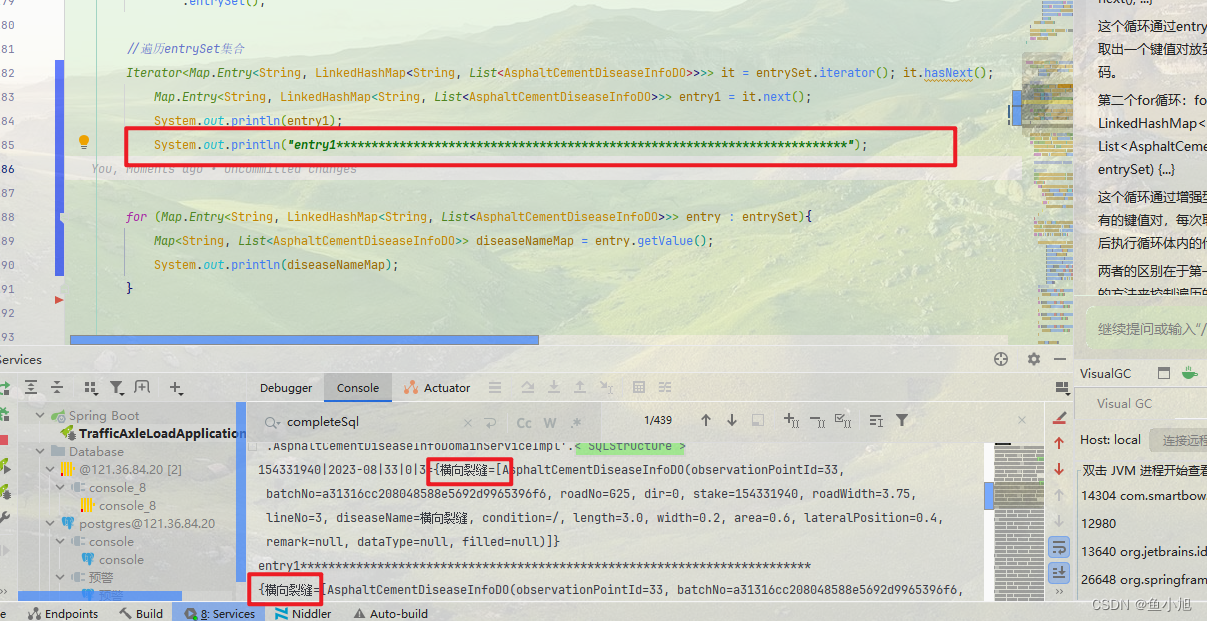
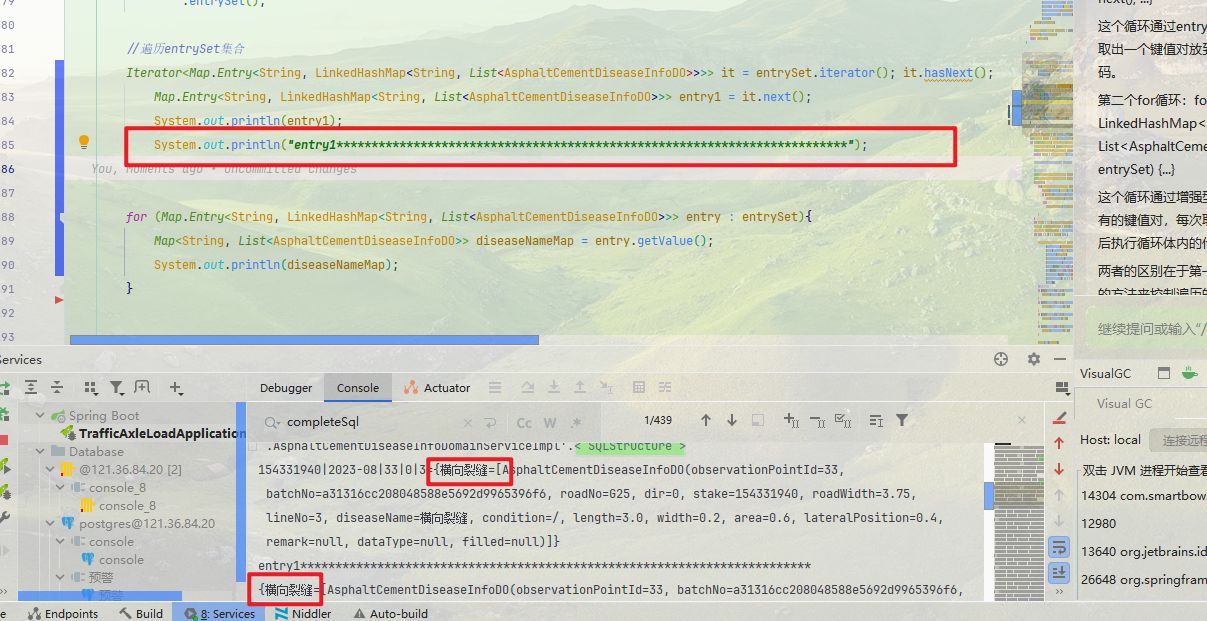
里面涵盖了全部for循环的使用 ( 当然包含我注释掉提交的时候会删除了两种尝试 )
增强型和迭代还是有区别的
单纯从打印来看迭代的前面会有一坨东西, 这个也是Set集合中的一部分元素, 不过已经实现了业务这些可有可无, 所以建议还是使用迭代
防丢图及链接bak
下图是经CSDN外链识别后转成图, 见文末
强烈建议使用图传存储图片(防丢)

for循环现在常用的就三种
最常用
for(int i=0;i<= 10; i++){
}
增强型for循环
这个也叫for … each循环
第二个for循环:for (Map.Entry<String, LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>>> entry : entrySet) {...}
这个循环通过增强型for循环(也叫foreach循环)来遍历所有的键值对,每次取出一个键值对直接放到entry变量中,然后执行循环体内的代码。
两者的区别在于第一个循环使用了迭代器,可以通过迭代器的方法来控制遍历的过程,比如可以跳过某些元素、在遍历过程中删除元素等;而增强型for循环则比较简单,只能依次遍历每个元素。
Iterator迭代器
第一个for循环:Iterator<Map.Entry<String, LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>>>> it = entrySet.iterator(); while(it.hasNext()) { Map.Entry<String, LinkedHashMap<String, List<AsphaltCementDiseaseInfoDO>>>> entry = it.next(); ...}
//这个循环通过entrySet的迭代器来遍历所有的键值对,每次取出一个键值对放到entry变量中,然后执行循环体内的代码。
//另一个写法就是去掉外层for循环可以直接对元素进行迭代也更符合规范, 不过在正式开发中加上更容易区分
文章来源:https://blog.csdn.net/qq_43476358/article/details/135484950
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!