Unicode编码
前言
一、Unicode ?
Unicode 是一种字符编码标准,旨在为世界上所有的字符(包括各种语言、符号和特殊字符)提供唯一的数字标识符。它的目标是统一字符的表示方式,以解决不同字符集和编码方案之间的兼容性问题。
传统的字符编码方案(如 ASCII)只能表示有限的字符集,无法涵盖全球范围内的字符需求。为了解决这个问题,Unicode 出现了。Unicode 使用四个十六进制数字(通常使用 “U+” 前缀表示)来表示每个字符,例如 U+0041 表示字符 “A”。
Unicode 的优势和应用包括:
-
全球性:Unicode 覆盖了全球范围内的字符需求,包括各种语言的字符、符号、标点符号、数学符号、货币符号等。
-
兼容性和互操作性:Unicode 提供了一种统一的字符编码方案,减少了不同系统和平台之间的字符兼容性问题,使得数据在不同环境下的传输和处理更加可靠和一致。
-
多语言处理:Unicode 支持多种语言的混合处理,使得在同一文本中可以混合使用不同语言的字符。
-
标准化:Unicode 是一个国际标准,由 Unicode 联盟维护和推进,各种软件、平台和设备都可以根据该标准进行开发和实现。
在工作中,Unicode 的使用广泛而重要。下面是一些应用场景:
-
多语言支持:在开发应用程序、网站或其他软件时,使用 Unicode 编码可以确保对多种语言的支持,使用户能够输入、显示和处理不同语言的字符。
-
数据交换和存储:在数据交换和存储过程中,使用 Unicode 编码可以保证数据的准确性和完整性,避免字符集转换问题和数据损失。
-
国际化和本地化:在进行国际化和本地化开发时,使用 Unicode 编码可以确保应用程序能够适应不同的语言环境,并正确处理各种字符和字符串操作。
-
数据库和文件处理:在数据库和文件处理过程中,使用 Unicode 编码可以支持各种语言的数据存储和检索,确保数据的一致性和可靠性。
需要注意的是,Unicode 本身只是一个字符编码标准,具体实现和使用仍然需要根据不同的编程语言、平台和工具进行适配和支持。
二、前端工程师使用Unicode
作为前端工程师,在处理 Unicode 编码时需要注意以下几个方面:
-
字符编码声明:确保在 HTML 文件中正确声明字符编码。使用
<meta>标签指定文档的字符编码,常见的是使用<meta charset="utf-8">来声明使用 UTF-8 编码。 -
字符串处理:在 JavaScript 中,字符串默认使用 Unicode 编码。大多数 JavaScript 引擎都支持 Unicode 字符串的处理。你可以直接使用字符串中的 Unicode 转义序列,例如
\uXXXX表示一个 Unicode 字符,其中XXXX为 Unicode 编码的十六进制表示。
示例代码:
const str = '\u4F60\u597D'; // 使用 Unicode 转义序列表示 "你好"
console.log(str); // 输出:你好
- 字符串长度计算:由于 Unicode 编码中的某些字符可能占据多个字节,因此在计算字符串的长度时需要注意。在 JavaScript 中,可以使用
length属性获取字符串的字符数。
示例代码:
const str = 'Hello, 你好!';
console.log(str.length); // 输出:11,包括 7 个英文字符和 2 个中文字符
- 输入和验证:当处理用户输入时,要注意验证和处理 Unicode 字符。确保输入的字符符合预期,并对输入内容进行适当的验证和转义,以避免安全问题。
在实际应用中,Unicode 编码的应用场景包括但不限于:
- 支持多语言的网站和应用程序开发。
- 字符串处理、正则表达式操作等。
- 处理特殊字符、表情符号等。
在代码中使用 Unicode 编码非常简单,只需使用 \uXXXX 的格式表示 Unicode 字符。例如,const str = '\u4F60\u597D'; 表示字符串 “你好”。
需要注意的是,大多数现代前端框架和库对 Unicode 编码提供了良好的支持,无需过多关注细节,直接在代码中使用对应的字符即可。如果需要进行字符编码转换、字符串处理等高级操作,则可以使用相关的库或工具,如 iconv-lite、punycode 等。
三、Javascript中处理 Unicode
在 JavaScript 中,可以使用内置的字符串函数和操作符来处理 Unicode。下面是一些常用的方式:
-
字符串长度和访问字符:
- 使用
length属性获取字符串中字符的数量。例如:const len = str.length; - 使用索引访问特定位置的字符。例如:
const char = str[index];
- 使用
-
Unicode 编码值获取和字符转换:
-
使用
charCodeAt()方法获取指定索引位置处字符的 Unicode 编码值。例如:const code = str.charCodeAt(index); -
使用
fromCharCode()方法将 Unicode 编码值转换为对应的字符。例如:const char = String.fromCharCode(code);
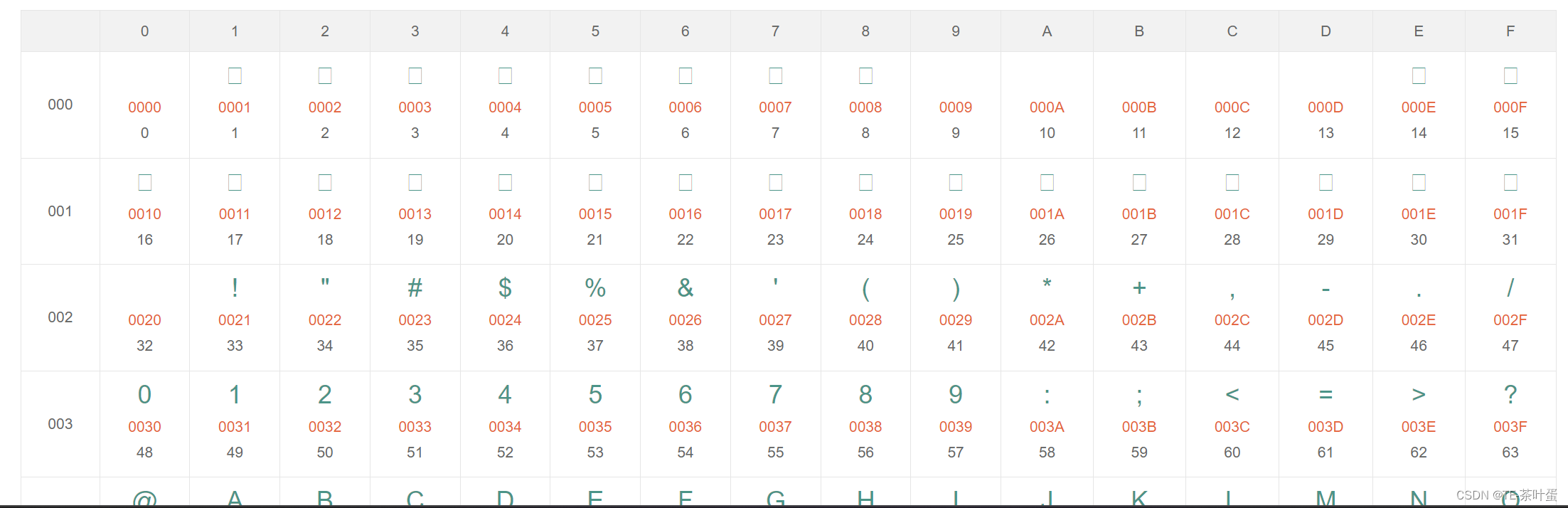
-
Unicode编码对照表(部分截图)
-
字符串迭代:
- 使用
for...of循环遍历字符串中的每个字符。例如:
for (const char of str) { // 处理每个字符 } ``` - 使用
-
正则表达式匹配:
- 使用 Unicode 属性转义来匹配特定的 Unicode 字符类别。例如,
/\p{L}/u可以匹配所有的字母字符。
- 使用 Unicode 属性转义来匹配特定的 Unicode 字符类别。例如,
-
字符串处理函数:
- 使用内置的字符串函数来处理和转换 Unicode 字符串。例如:
toUpperCase()、toLowerCase()、normalize()等。
- 使用内置的字符串函数来处理和转换 Unicode 字符串。例如:
示例代码:
const str = 'Hello, 你好!';
console.log(str.length); // 输出:11
console.log(str.charAt(7)); // 输出:你
console.log(str.charCodeAt(7)); // 输出:20320
console.log(String.fromCharCode(20320)); // 输出:你
for (const char of str) {
console.log(char); // 逐个输出字符串中的字符
}
const regex = /\p{L}/u;
console.log(str.match(regex)); // 匹配所有的字母字符
console.log(str.toUpperCase()); // 输出:HELLO, 你好!
console.log(str.normalize()); // 输出:Hello, 你好!
上述代码演示了处理 Unicode 字符的几种常见方式。
需要注意的是,在一些较旧的 JavaScript 引擎中,对于一些特殊的 Unicode 字符或操作可能会存在兼容性问题。为了确保最佳的兼容性,建议使用最新的 JavaScript 版本,或者使用 JavaScript 的标准库和第三方库来处理 Unicode 字符。
总结
本文简单介绍了Unicode编码的相关知识
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- (N-139)基于springboot,vue宠物领养系统
- Allegro在走线时有很多断线(有个小方框)如何处理?
- 前端面试题--TypeScript
- 开发利器——C语言必备实用第三方库
- 使用C语言的strtok函数来分割字符串
- 008 标识符和关键字
- AOP与日志(下)
- CentOS7部署bamboo9.4.2-postgresql版
- 关于“Python”的核心知识点整理大全43
- 响应式Web开发项目教程(HTML5+CSS3+Bootstrap)第2版 例3-1 CSS3过渡