20、清华、杭州医学院等提出:DA-TransUNet,超越TranUNet,深度医学图像分割框架的[皇帝的新装]
前言:
本文由清华电子工程学院、杭州医学院、大阪大学免疫学前沿研究所、日本科学技术高等研究院信息科学学院、东京法政大学计算机与信息科学专业共同作者,于2023年11月14号发表于arXiv的《Electrical Engineering and Systems Science》期刊。
论文:
《DA-TransUNet: Integrating Spatial and Channel Dual Attention with Transformer U-Net for Medical Image Segmentation》
代码:

1、Abstract
由于强大的深度表示学习,自动医学图像分割取得了巨大的进展。Transformer的影响导致了对其变种的研究,并在很大程度上取代了传统的CNN模块。然而,这种趋势常常忽视了Transformer的固有特征提取能力以及通过微小调整对模型和Transformer模块的潜在改进。
本研究提出了一种新颖的深度医学图像分割框架,名为DA-TransUNet,旨在将Transformer和双重注意力块引入传统U形架构的编码器和解码器中。与先前基于Transformer的解决方案不同,作者的DA-TransUNet利用了Transformer的注意力机制和DA-Block的多方面特征提取,可以有效地结合全局、局部和多尺度特征,增强医学图像分割能力。
与此同时,实验结果表明,在U-Net结构中,在Transformer层之前添加了一个双重注意力块,以促进特征提取。此外,将双重注意力块纳入跳跃连接中可以增强特征传递到解码器,从而提高图像分割性能。在各种医学图像分割基准测试中,实验结果表明,DA-TransUNet明显优于最先进的方法。
2、 Introduction
在定量疾病、辅助评估疾病预后和评估治疗效果过程中,精确划定病变区域起着至关重要的作用。对于病理诊断而言,手动分割准确可靠,成本相对较低,但在标准化临床环境中至关重要。相反,自动分割可确保可靠一致的处理过程,提高效率,减少劳动力和成本,并保持准确性。因此,在临床诊断领域存在对异常准确的自动医学图像分割技术的巨大需求。
在过去的十年中,卷积神经网络(CNN)如全卷积网络(FCN)、U-Net及其改进模型已取得显著成功。ResUNet是在这一时期出现的,受到残差概念的影响。类似地,UNet++强调了跳跃连接的改进,而DAResUNet则在U-Net中结合了双重注意力块和残差块(Res-Block)。这两种架构都受益于编码器-解码器思想的影响,跳跃连接为解码器提供了初始特征,弥合了编码器和解码器之间的语义差距。然而,感知场的限制和卷积操作中的偏差可能会损害分割的准确性。
此外,无法建立长程依赖关系和全局上下文进一步限制了性能的改进。值得注意的是,Transformer最初是为NLP中的序列到序列建模而开发的,但在计算机视觉(CV)领域也发现了其效用。例如,视觉Transformer(ViTs)通过将图像分为多个小图像模块,然后将这些小图像模块的先前嵌入序列作为输入馈送到Transformer中,取得了良好的结果。Transformer的能力进一步推动了分割的准确性。受到ViT的启发,TransUNet进一步将ViT的功能与U-Net在医学图像分割领域的优势相结合。
具体而言,它使用Transformer的编码器来处理图像,并使用传统的CNN和跳跃连接进行准确的上采样特征恢复。Swin-UNet将Swin-transform块与U-Net结构相结合,取得了良好的结果。
在基于医学图像分割的上述工作中,基于U-Net的特点和Transformer的特点都进行了改进。在某种程度上,上述工作是令人鼓舞的,但仍存在一些局限性:
-
在传统的U形医学图像分割模型中,扩展的卷积过程导致全局信息的不足,使得全局特征获取变得困难。
-
引入注意力机制后,已经将许多注意力模块添加到U-Net中。然而,挑战在于对这些模块进行最佳定位和利用,以辅助特征提取。
-
Transformer在提取特征方面具有强大的能力,同时能够保留全局信息。然而,如何进一步激发Transformer的潜力,并有效地结合CNN和Transformer的特征,是一个值得思考的问题。
-
跳跃连接是U-Net模型中非常重要的一部分,它弥合了编码器和解码器之间的语义差距。但尚未解决的问题是优化这些连接,使解码器能够检索和返回更精确的特征图,从而增强模型的鲁棒性。
根据上述提到的问题和限制,作者提出了DA-TransUNet。作者相信广泛使用Transformers并不像利用一个经过优化的单一Transformer那样有影响力。因此,作者专注于增强U-Net和Transformer的集成。为了提高Transformer层内特征的准确性,作者引入了Dual Attention Block。该块集成了Dual Attention Network for Scene Segmentation中的Position Attention Block(PAM)和Channel Attention Block(CAM)。Dual Attention Block位于嵌入层中,提供了强大的特征提取能力。
考虑到编码器-解码器和跳跃连接的结构,作者使用Dual Attention Block对三层跳跃连接中编码器传递的特征进行特征优化,这有助于解码器-编码器结构进一步减少语义差异,生成统一的特征表示。这种融合方法可以充分利用不同方面的全局和局部特征,并使它们相互补充,从而提高模型的医学图像分割性能。与传统的U形结构一致,编码器用于获取上下文特征和跳跃连接,解码器用于融合统一特征。与大多数基于CNN的编码器不同,作者在编码中包含了一个Transformer模块,进一步提取远距离的上下文特征,从而极大地提高了编码能力。
为了提高解码器的能力,作者进一步优化了跳跃连接传递的特征。由于这些增强,解码和医学图像分割能力都得到了显著提升。作者使用了CVC-ClinicDB数据集、Kvasir SEG数据集、Kvasir-Instrument数据集、Synapse数据集和Chest X-ray mask and label数据集来评估DA-TransUNet的有效性。
作者主要在Synapse、CVC-ClinicDB、ISIC2018、kvasir-seg、Kvasir-Instrument数据集以及Chest X-ray mask and label数据集上评估了DA-TransUNet的有效性。DA-TransUNet展示了显著的效果,这可以通过可量化的指标来证明。
作者的主要贡献总结如下:
-
提出了DA-TransUNet,这是一种将位置和通道信息的双重注意力机制集成到Transformer编码器-解码器框架中的新颖架构。这种方法提高了编码器-解码器结构的灵活性和功能性,从而提高了医学图像分割任务的性能。
-
提出了一个经过精心设计的双重注意力编码机制,将其定位在Transformer层之前,可以增强其特征提取能力,并丰富U-Net结构中编码器的功能。
-
通过将Dual Attention Block纳入每个层的跳跃连接中,增强了跳跃连接的有效性。这一修改经过消融研究的支持,可以将更准确的特征传递给解码器,从而改善图像分割性能。
-
提出的DA-TransUNet方法在多个医学图像数据集上实现了最先进的性能,这证明了作者方法的有效性和对医学图像分割的推进贡献。
3、Related Work
在接下来的部分中,作者提出了DA-TransUNet的架构,如图1所示。作者首先对整体架构进行概述,然后按照以下顺序详细介绍其主要组成部分:双重注意力块作为专门的特征提取模块、编码器、跳跃连接和解码器。
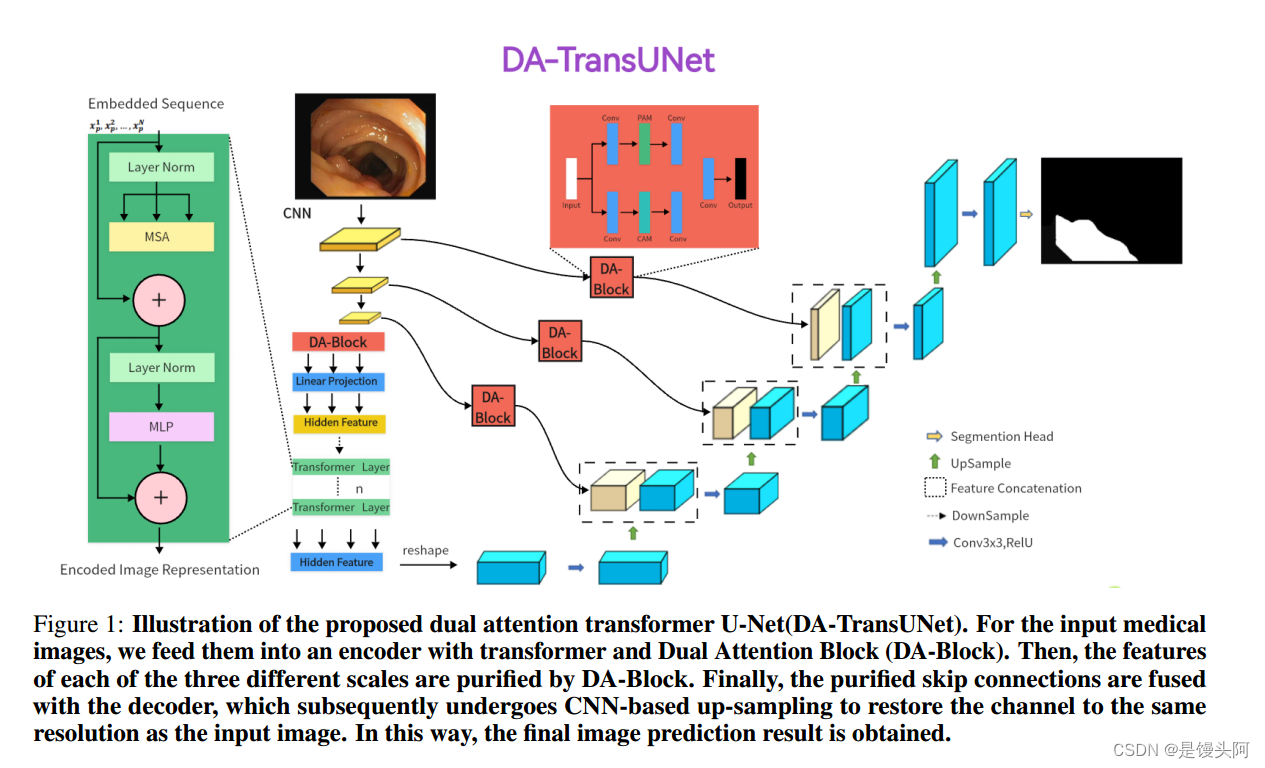
3.1 DA-TransUNet介绍
在图1的基础上,作者概述了DA-TransUNet架构。该模型分为三个核心部分:编码器、解码器和跳跃连接。
具体而言,编码器将传统的卷积神经网络(CNN)与Transformer层相结合,并通过独特引入的双重注意块进行增强。相比之下,解码器主要采用传统的卷积机制。双重注意力块在实现高效的跳跃连接方面起到关键作用。DA-TransUNet架构的目标是提高图像分割性能。它通过协同整合传统的卷积机制、Transformer层和专门的双重注意力块来实现这一目标。同时,该架构利用跳跃连接促进优秀的特征提取,并准确恢复输入图像。
为了阐明作者提出的DA-TransUNet模型设计的理论基础,有必要考虑U-Net架构和Transformer在特征提取方面的局限性和优势。Transformer通过自注意力机制在全局特征提取方面表现出色,但它们在定位属性方面天然受限,忽视了多方面的特征视角。另一方面,传统的U-Net架构擅长局部特征提取,但缺乏全局上下文建模的能力。
为了解决这些限制,作者将方向性注意块(DA-Block)整合到Transformer层之前和编码器-解码器跳跃连接中。这样做有两个目的:
-
首先,它优化了输入到Transformer的特征图,使全局特征提取更加细致和精确;
-
其次,跳跃连接中的DA-Block优化了从编码器传递的特征,从而帮助解码器重建更准确的特征图。
因此,作者提出的架构融合了这两种基础技术的优势,并弥补了它们的不足,从而实现了一个能够进行多角度特征提取的强大系统。
接下来,作者详细介绍了DA-TransUNet模型的操作流程。
-
首先,输入图像经过三轮卷积和下采样,得到尺寸为(1024,14,14)的特征图。
-
然后,使用卷积双重注意块进行特征提取,将尺寸减小为(768,14,14)。作者选择这些尺寸以在计算效率和特征表达能力之间保持平衡。
-
接下来,将特征图从三维数组(196,768)扁平化,并输入到Transformer层中,输出具有相同尺寸的特征。这个扁平化步骤使得Transformer能够更有效地处理特征,因为它需要二维输入。
-
然后,这些特征被重新恢复为三维形状(768,14,14),作为解码器的输入。解码器通过三个阶段的上采样、卷积和跳跃连接生成一个尺寸为(64,112,112)的特征图。选择三个阶段的设计是为了在上采样过程中逐渐优化特征,提供更准确的重建。
-
最后的上采样步骤将图像恢复到原始尺寸。
3.2 医学图像分割建模中跳跃连接的应用
跳跃连接在U-Net中的目标是弥合编码器和解码器之间的语义差距,有效恢复细粒度的物体细节。对跳跃连接进行了3个主要的改进:
-
首先,增加了它们的复杂性。U-Net++重新设计了跳跃连接,将一个类似于Dense结构的组件加入到跳跃连接中,而U-Net3++则将跳跃连接改为了一个全尺度的跳跃连接。
-
其次,RA-UNet引入了一种用于精确特征提取的三维混合残差注意力方法,应用于跳跃连接。
-
第三种改进是编码器和解码器特征图的组合:在BCDU-Net中,将双向卷积长短期记忆(LSTM)模块添加到跳跃连接中,作为经典跳跃连接的另一种扩展。与第二种方法相一致,作者在每个跳跃连接层中整合了双重注意力块,增强了解码器的特征提取能力,从而提高了图像分割的准确性。
3.3 注意力机制在医学图像中的应用
注意力机制对于引导模型关注相关特征,从而提高性能至关重要。近年来,双重注意力机制在多个领域得到了广泛应用。在场景分割中,双重注意力网络(DANet)采用空间和通道注意力机制来提高性能。一个模块化的DANs框架被提出,巧妙地融合了视觉和文本注意力机制。这种协同的方法可以选择性地关注两种类型数据中的关键特征,从而提高任务特定的性能。
此外,双重注意力模块(DuATM)的引入在音频-视觉事件定位领域具有突破性的意义。该模型在学习上下文感知特征序列和执行注意力序列比较方面表现出色,有效地整合了面向听觉的视觉注意力机制。此外,双重注意力机制已经应用于医学分割,并取得了有希望的结果。多级双重注意力U-Net用于息肉分割将双重注意力和U-Net结合应用于医学图像分割。虽然在医学图像分割方面取得了重大进展,但在探索双重注意力块在医学图像分割领域的潜力方面仍有很大的研究空间。
4、本文方法
在接下来的部分中,作者提出了DA-TransUNet架构,如图1所示。作者首先概述整体架构,然后按照以下顺序详细介绍其主要组件:双重注意力块作为专门的特征提取模块,编码器,跳跃连接,最后是解码器。
4.1 DA-TransUNet概述
在图1的基础上,作者概述了DA-TransUNet架构。该模型由三个核心部分组成:编码器、解码器和跳跃连接。特别是,编码器将传统的卷积神经网络(CNN)与Transformer层融合,并且通过独特引入的双重注意力块进一步丰富。
相反,解码器主要使用传统的卷积机制。双重注意力块在实现高效跳跃连接方面起着关键作用。DA-TransUNet架构的目标是增强图像分割性能。它通过协同地整合传统的卷积机制、Transformer层和专门的双重注意力块来实现这一目标。同时,该架构采用跳跃连接来促进优秀的特征提取,并准确恢复输入图像。
为了阐明作者提出的DA-TransUNet模型设计的理论基础,必须考虑U-Net架构和Transformer在特征提取方面的限制和优势。Transformer通过其自注意力机制在全局特征提取方面表现出色,但它们固有地局限于单向关注位置属性,忽视了多方面的特征视角。另一方面,传统的U-Net架构擅长局部特征提取,但缺乏全面的全局上下文化能力。
为了解决这些限制,作者在Transformer层之前和编码器-解码器跳跃连接之中整合了方向注意力块(DA-Block)。这具有双重目的:首先,它精炼了输入到Transformer的特征图,实现了更加细致和精确的全局特征提取;其次,跳跃连接中的DA-Block优化了来自编码器的传输特征,帮助解码器重构出更准确的特征图。因此,作者提出的架构将两种基础技术的优势融合起来,减轻了它们的弱点,从而形成了一个具有多角度特征提取能力的强大系统。
接下来,作者详细介绍DA-TransUNet模型的操作流程。首先,输入图像经过三轮卷积和下采样,得到尺寸为(1024,14,14)的特征图。然后,使用卷积双重注意力块进行特征提取,将尺寸减小为(768,14,14)。作者选择这些尺寸以在计算效率和特征表达能力之间保持平衡。接下来,将特征图从三维展平为二维数组(196,768),并输入到Transformer层,输出相同尺寸的特征。这个展平步骤使得Transformer能够更有效地处理特征,因为它需要二维输入。
然后,将特征图重新转换为三维形状(768,14,14),作为解码器的输入。解码器使用三个阶段的上采样、卷积和跳跃连接,生成尺寸为(64,112,112)的特征图。选择三个阶段的设计是为了在上采样过程中逐渐细化特征,提供更准确的重建结果。最后一个上采样步骤将图像恢复到原始尺寸。
4.2 双重注意力块(DA-Block)
如附图2所示,双重注意力块(DA-Block)是一个特征提取模块,它集成了基于位置和基于通道的特征提取组件,允许从两个不同的角度进行特征提取。从不同角度提取特征可以增强获得的特征的精度和细粒度。虽然Transformer具有出色的特征提取能力,可以关注不同的位置,但它可能会忽视医学图像中对精度的要求。
相反,DA-Block不仅在基于位置的特征提取方面表现出色,还在基于通道的特征提取方面表现出色。与单一特征提取相比,多角度特征提取可以获得更准确、更详细的特征,从而提高模型的分割能力。
因此,作者将其纳入编码器和跳跃连接中,以增强模型的分割性能。DA-Block包括两个主要组件:一个带有位置注意力模块(PAM),另一个包含通道注意力模块(CAM),这两个组件都借鉴了用于场景分割的双重注意力网络中的设计。

PAM(位置注意力模块):?如图3所示,这是PAM,它可以捕捉特征图中任意两个位置之间的空间依赖关系,通过对所有位置特征的加权求和来更新特定特征。权重由两个位置之间的特征相似性确定,因此PAM在提取有意义的空间特征方面非常有效。
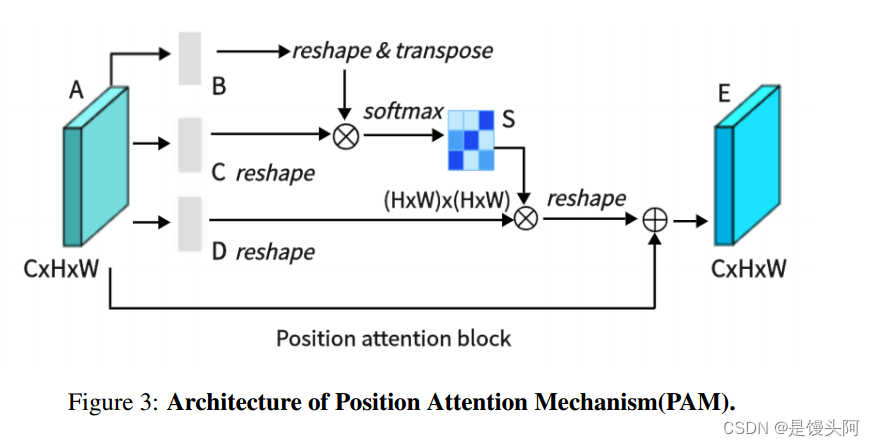
解释:


通道注意力模块(CAM):
如图 4 所示,这是 CAM,它在提取通道特征方面表现优异。与 PAM(位置注意力模块)不同,作者直接将原始特征重塑为![]()
然后对 A 和其转置执行矩阵乘法。接下来,作者应用一个 softmax 层,以获得通道注意力图?
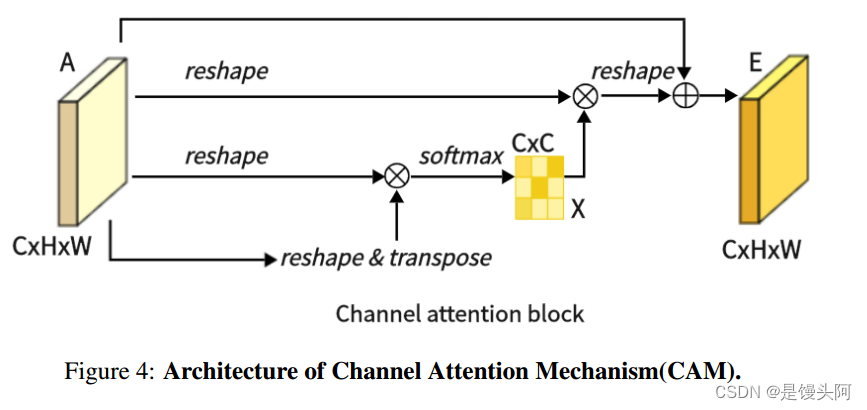
DA(双重注意力模块):如图 2 所示,作者提出了双重注意力模块(DA-Block)的架构。这种架构将位置注意力模块(PAM)强大的位置特征提取能力与通道注意力模块(CAM)的通道特征提取优势相结合。
此外,当与传统卷积方法相结合时,DA-Block 展现出卓越的特征提取能力。DA-Block 包含两层,第一层以 PAM 为主导,第二层以 CAM 为主导。
这种复杂的 DA 块架构将位置注意力模块和通道注意力模块的优势无缝集成,从而提高特征提取效果,使其成为提高模型整体性能的关键组成部分。
4.3 编码器(Transformer 与双重注意力模块)
如图 1 所示,编码器架构包括3个关键组件:3个卷积块、双重注意力模块、嵌入层以及专为 Transformer 设计的层。尤其重要的是,在 Transformer 层之前加入 DA-Block。这个设计选择受到了净化通过3个卷积块获得特征的需要,使它们更适合通过 Transformer 进行全局特征提取。
Transformer 架构在保持全局上下文方面发挥着至关重要的作用,而 DA 模块则增强了 Transformer 的特征获取能力,使其在捕捉有力的全局上下文信息方面表现得更加出色。这种协同方法和谐地融合了全局和局部特征,有效地平衡了它们的集成。
三个卷积块的组成遵循了 U-Net 及其多样化版本的架构,无缝地将卷积操作与下采样过程相结合。每个卷积层将输入特征图的大小减半,并将维度加倍,这种配置在保持计算效率的同时最大限度地提高了特征表达力。双重注意力模块在位置和通道级别提取特征,增强特征表示的深度,同时保留输入映射的内在特性。
嵌入层起到了关键的中间层作用,实现了所需的维度适应,为后续的 Transformer 层次奠定基础。将 Transformer 层集成到模型中是一种战略选择,使模型具备了传统 CNN 层无法单独实现的优秀全局特征提取能力。
在编码器部分,输入图像经过三个连续的卷积块,逐步扩大感受野以包含重要特征。随后,DA 模块通过应用基于位置和通道的关注机制来优化特征。接着,重塑的特征在嵌入层的帮助下经历维度转换,然后导入 Transformer 框架以提取全面的全局特征。
这种有序的进展确保了在连续卷积层的整个过程中信息的全面保留。最终,Transformer 生成的特征图经过重新构建和引导,通过中间层传递到解码器。
通过融合卷积神经网络、变压器架构和双重注意力机制,编码器配置最终形成了一种强大的特征提取能力,从而实现了一种共生能力的发电站。
4.4 双注意力跳连接
与其他 U 结构模型类似,作者也在编码器和解码器之间加入了跳连接,以弥合它们之间存在的语义差距。为了进一步缩小这个语义差距,作者在三个跳连接层中的每个层引入了双重注意力块(DA 块),如图 1 所示。
这个决策基于作者的观察,即传统的跳连接通常传输冗余特征,而 DA 块可以有效地过滤这些冗余特征。将 DA 块集成到跳连接中,使它们能够从位置和通道两个方面对稀疏编码特征进行细化,提取更多有价值的信息同时减少冗余。通过这种方式,DA 块有助于解码器更准确地重建特征图。此外,引入 DA 块不仅增强了模型的鲁棒性,而且有效地降低了过拟合敏感度,有助于提高模型的整体性能和泛化能力。
4.5 解码器
如图 1 所示,图的右半部分代表了解码器。解码器的主要功能是从编码器获得的功能和通过跳连接接收的功能中重构原始特征图,使用上采样等操作。这种重构对于在图像中保留语义信息的同时恢复空间细节至关重要。
因此,作者采用跳连接和解码器来恢复原始特征图。解码器架构包括特征融合、分割头和三个上采样卷积块。特征融合涉及将经过跳连接传递的特征图与现有特征图集成。分割头负责将特征图恢复到原始尺寸。三个上采样卷积块使输入特征图的大小在每一步中增加两倍。
在解码器的范围内,工作流程包括将输入图像通过卷积块,然后进行上采样,使特征图的大小增加两倍,并将它们的维度减少一半。接着,跳连接传递的特征被融合,上采样和卷积继续。经过这个过程的三次循环后,生成的特征图经过最后一次上采样,并通过分割头将其恢复到原始尺寸。
凭借这种架构,解码器表现出强大的解码能力,并能根据编码器和跳连接传递的特征有效恢复原始特征图。
5、Experiments
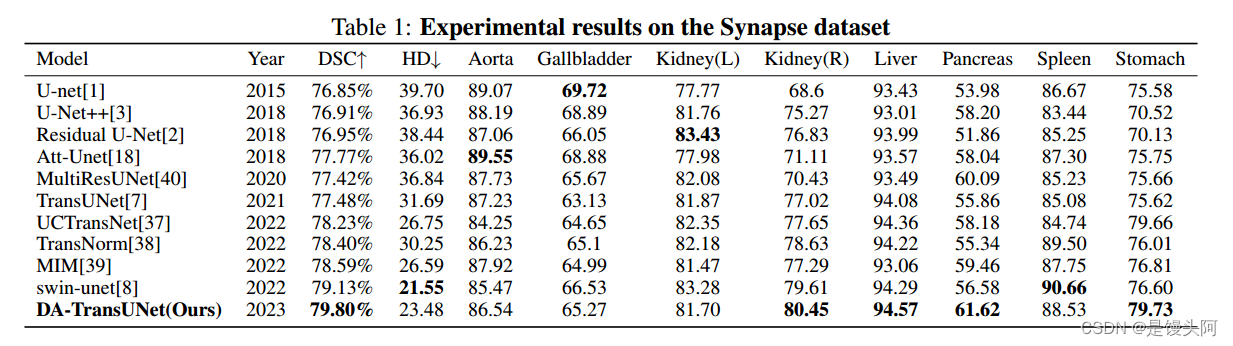
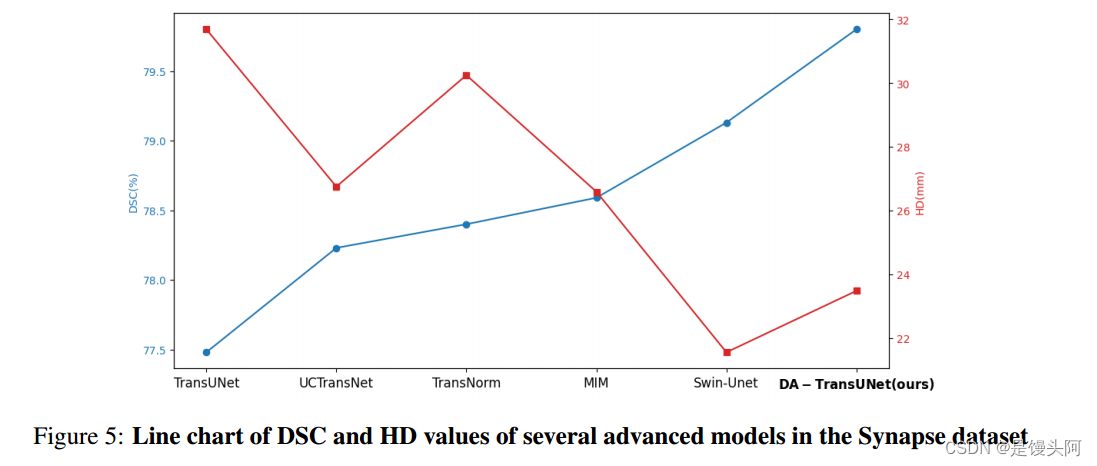

5.1 消融实验
作者在 Synapse 数据集上对 DA-TransUNet 模型进行了消融实验,以讨论不同因素对模型性能的影响。具体包括:1)编码器中的 DA-Block。2)跳连接中的 DA-Block。
5.1.1 编码器和跳连接中 DA-Block 的效果
在本研究中(见表 3),作者测试了在编码层和跳连接中包含 DA-Block 是否有助于提高模型的分割能力。同样,DA-TransUNet(带有 DA-Block 的编码器)和 DATransUNet(没有添加 DA-Block)之间的区别显著提高了性能。在编码器的 Transformer 之前加入 DA-Block 显著提高了系统的有效性。这使得所有八个器官的特征学习效果提升。通过为解码器提供更精细的特征,有助于减少上采样过程中的特征消失,降低过拟合风险,提高模型稳定性。

同样,从 DA-TransUNet(带有 DA-Block 的编码器)和 DA-TransUNet(没有添加 DA-TransUNet)可以看出,在编码器的 Transformer 之前添加 DA-Block 也是一种显著的改进。为 Transformer 提供更精确的特征可以大大提高 Transformer 学习特征的能力。最后,根据表 3 的结果,可以得出在编码器的跳连接和 Transformer 层之前添加 DA-Block 提取特征是有效的。将 DA-Block 添加到跳连接中可以优化解码器的特征,而将其添加到编码器中可以增强 Transformer 的特征学习能力。
5.1.2 在不同层跳连接中添加 DA-Block 的效果
在本研究中(见表 4),作者测试了在哪些层跳连接中添加 DA-Block 能够最大程度地提高模型分割率。如表所示,DA-TransUNet(第一层具有 DA 块)、DATransUNet(第二层具有 DA 块)、DA-TransUNet(第三层具有 DA 块)和 DA-TransUNet(第一、第二和第三层均具有 DA 块),可以看出,在跳连接的任何一层添加 DA-Block 都对模型分割率有显著提高,而在编码层添加 DA-Block 之外。

根据表 4,可以看到在每个跳连接层添加 DA-Block 效果最佳。传统的跳连接仅将编码层的特征传递给解码层,而不考虑传递特征的质量。根据实验结果,可以得出向解码层提供更精确的特征可以极大地提高模型的特征学习能力和图像分割能力。
6. Dog.Black Professor

快圣诞了,狗蛋学者的新装也到啦
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 360度全景展示效果图怎么制作?
- JOSEF约瑟 双位置继电器 DCS-12/110V 线圈电压直流110V 板前安装
- Milvus数据一致性介绍及选择方法
- 2023光伏“洗牌”,鼎捷数智方案如何助力企业抓住时代契机?
- 自动驾驶轨迹规划之碰撞检测(一)
- XSS漏洞:一道关于DOM型XSS的题目
- java——运算符
- Lazada物流禁运规则是什么?Lazada物流禁运商品有哪些?——站斧浏览器
- 如何在 Python 3 中使用 while 循环
- 【PostgreSQL】从零开始:(二十七)数据类型-UUID 类型