XTuner 大模型单卡低成本微调原理
发布时间:2024年01月11日
Finetune简介
微调模式:
- 增量预训练微调
- 使用场景:让基座模型学习到一些新知识,如某个垂直领域的常识
- 训练数据:文章、书籍、代码等
- 指令跟随微调
- 使用场景:让模型学会对话模板,根据人类指令进行对话
- 训练数据:高质量的对话、问答数据

增量预训练微调
增量预训练微调不需要问题,只需要回答,是一个一个的陈述句的数据集
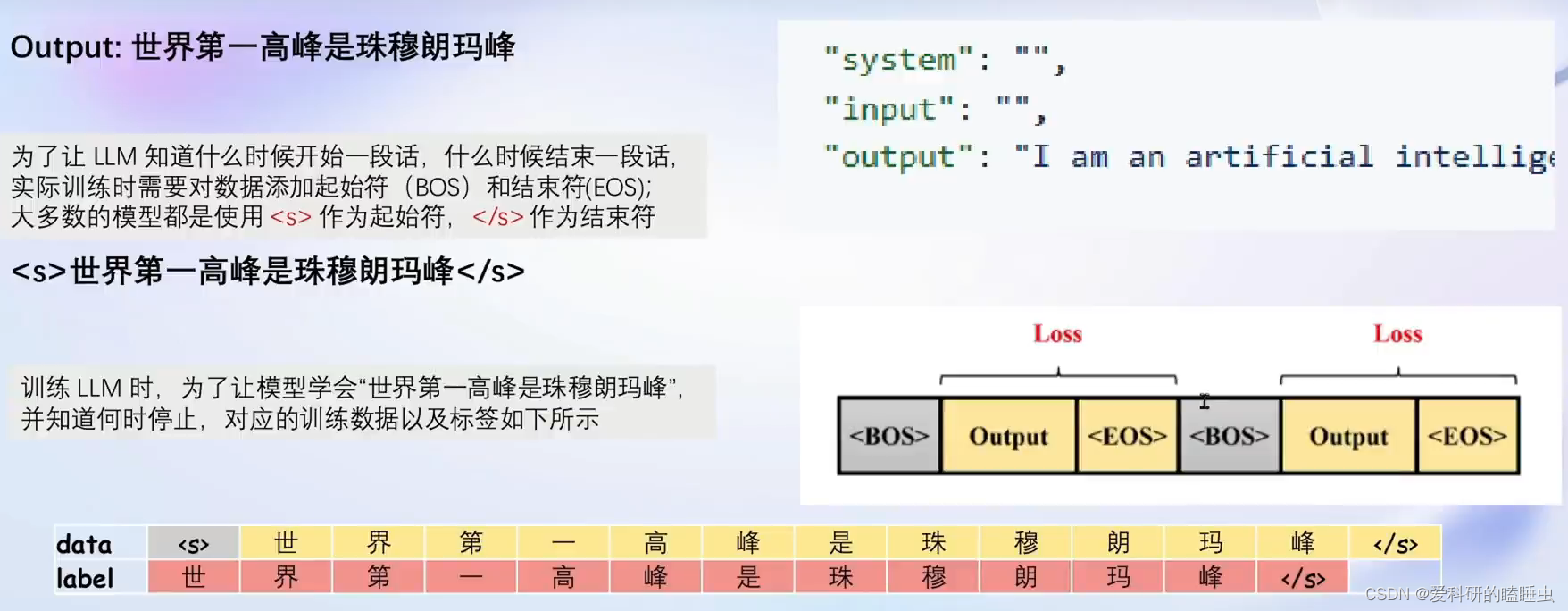
指令跟随微调
不进行指令微调时,只是单纯的拟合训练数据集中分布,并不知道是问模型一个问题。为了让模型更加明白我们的意图就要在预训练好的模型上进行指令跟随微调
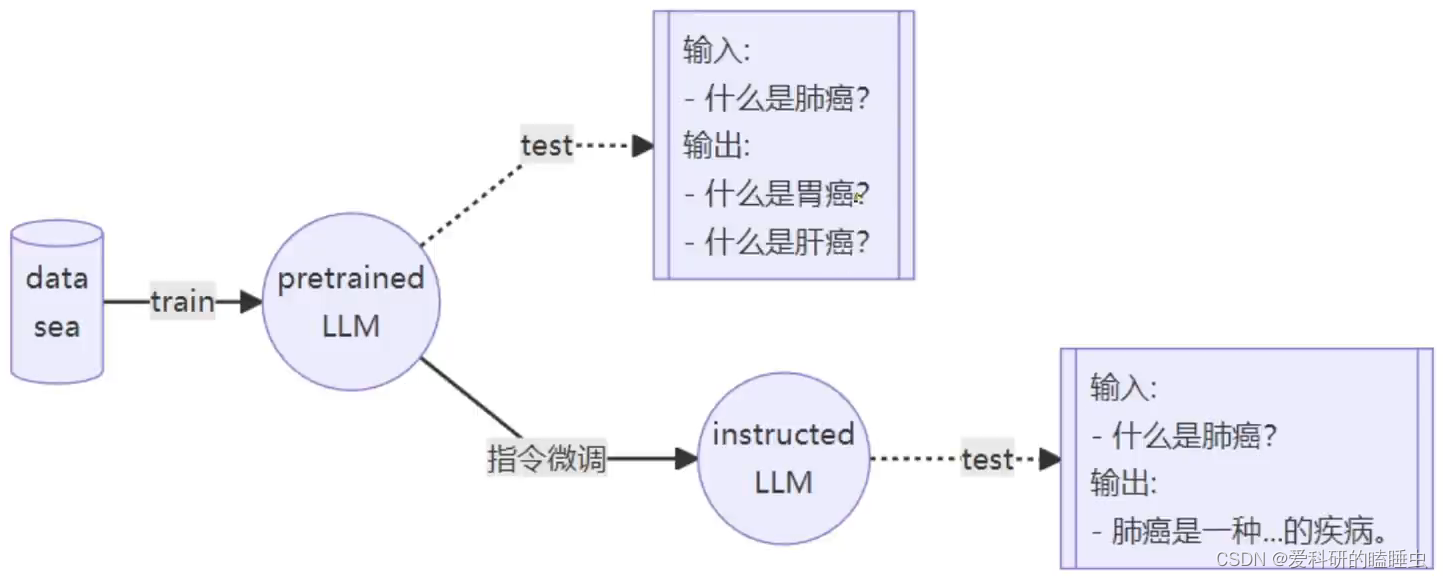
指令跟随是一问一答的数据
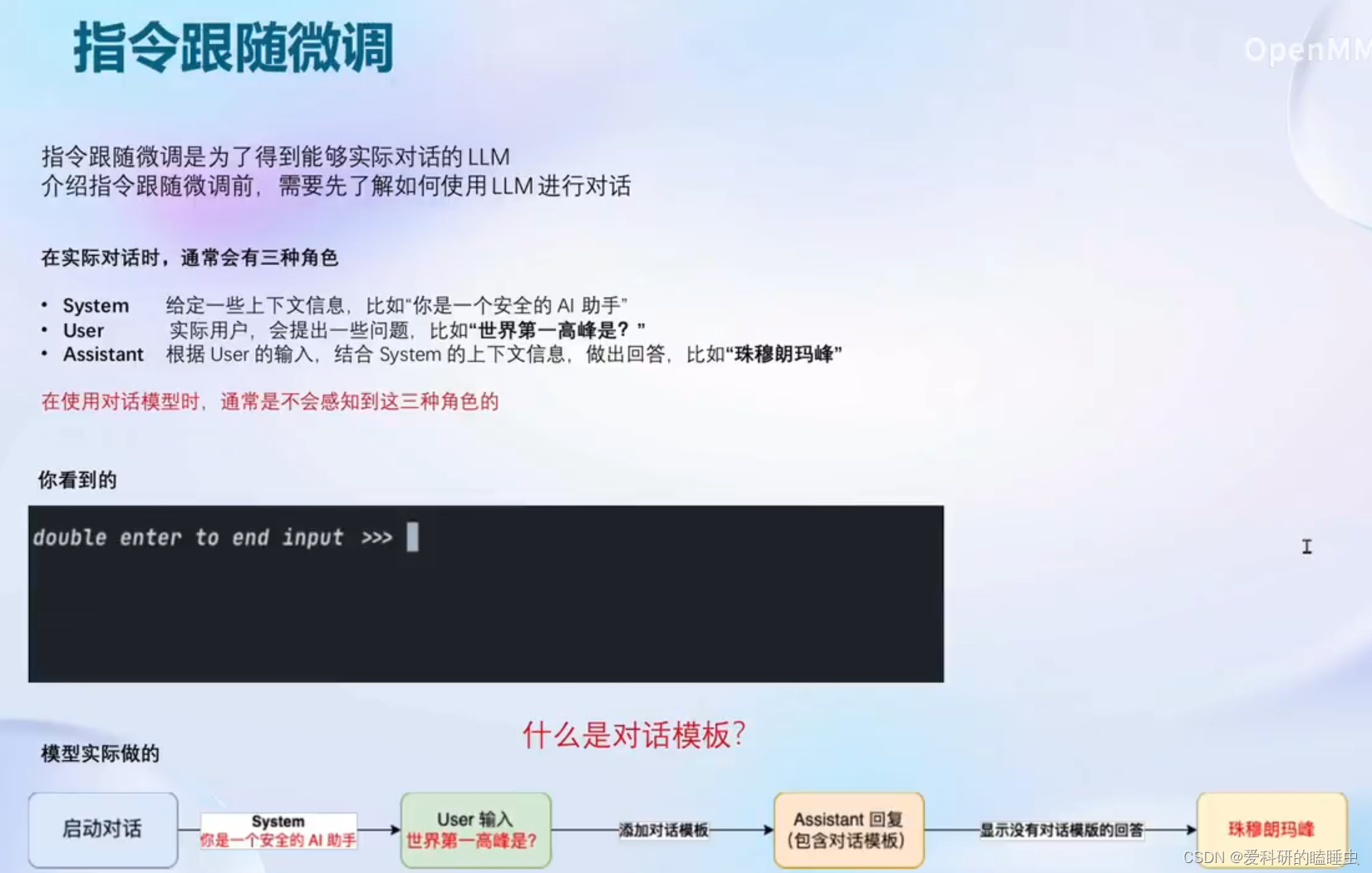
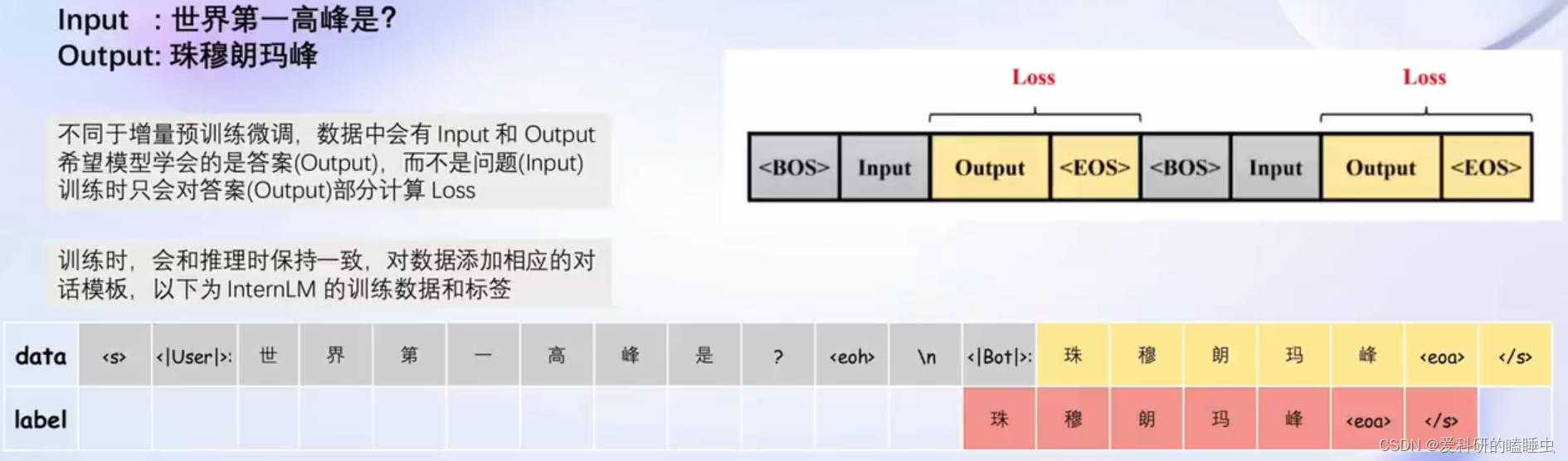
微调原理
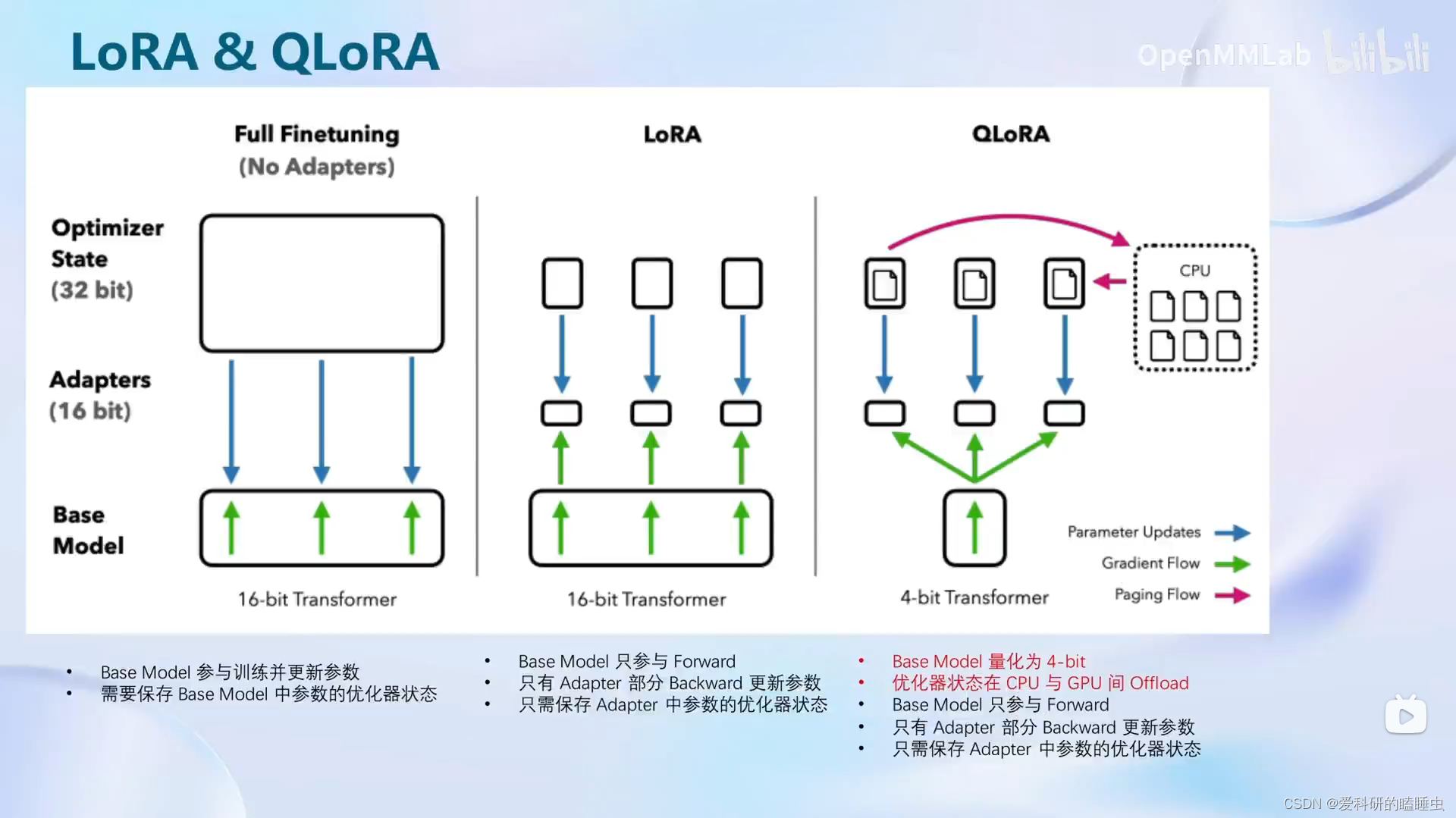
微调策略采用LoRA或QLoRA
- LoRA是在原本的Linear旁,新增一个支路,包含两个连续的小Linear, 新增的这个支路叫Adapter
- Adapter参数量远小于原本的Linear,大幅降低训练的显存消耗
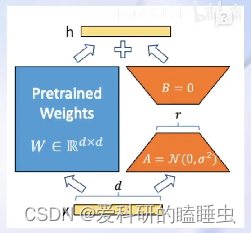
对大模型进行全面改动显存消耗非常大,因此,有一种叫LoRA的方法,只对模型的某些参数进行改动,而不是对整个大模型的参数进行修改,而QLoRA是LoRA的一种改进,可以改动更小的模型参数,就能达到想要的结果
XTuner微调框架
在书生·浦语大模型全链路开源体系有详细的介绍,需要的可以查看
XTuner数据引擎

XTuner微调的优化策略
- Flash Attention
- 将Attention计算并行,避免了计算过程中Attention Score N×N的显存占用(训练过程中N都比较大)
- DeepSpeed ZeRO
- ZeRO优化,通过将训练过程中的参数、梯度和优化器状态切片保存,能够在多个GPU训练时显著节省显存
- 除了训练时切片,DeepSpeed训练时使用FP16的权重,相较于Pytorch的AMP训练,在单个GPU上也能大幅节省显存
动手实战
手把手的实现微调训练一个自己模型见XTuner 大模型单卡低成本微调实战
文章来源:https://blog.csdn.net/m0_49289284/article/details/135532140
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- VC++ 通过 GetAdaptersInfo 函数获取网卡适配器信息列表
- Java线程池使用浅谈
- 科普帖:什么是Docker?解析它的工作原理、用途和优缺点
- ZZULIOJ 1072: 青蛙爬井
- 代码随想录算法训练营day28 || 93.复原IP地址,78.子集,90.子集II
- 思考(九十三):网络加速器简单实现设计
- http基本格式
- 材料的褪色变色室内光照太阳光模拟器
- 新航向,新生态: Michael在出海业务圆桌会议分享HyperBDR全球业务拓展之道
- GZ075 云计算应用赛题第1套