<JavaEE> TCP 的通信机制(五) -- 延时应答、捎带应答、面向字节流
发布时间:2023年12月28日
目录
TCP的通信机制的核心特性
| TCP的通信机制最核心的特性是可靠传输。 | |
| TCP至少通过以下机制来保证传输的可靠性,在保证可靠性的同时也采取一些机制来提升传输效率: | |
| <1> 确认应答 | <6> 阻塞控制 |
| <2> 超时重传 | <7> 延时应答 |
| <3> 连接管理 | <8> 捎带应答 |
| <4> 滑动窗口 | <9> 面向字节流 |
| <5> 流量控制 | <10> 异常情况处理 |
阅读指针 -> 《 TCP 的通信机制?-- 流量控制 和 拥塞控制 》<JavaEE> TCP 的通信机制(四) -- 流量控制 和 拥塞控制-CSDN博客文章浏览阅读203次,点赞8次,收藏7次。介绍了 TCP 的通信机制 -- 流量控制 和 拥塞控制https://blog.csdn.net/zzy734437202/article/details/135257678
七、延时应答
1)什么是延时应答?
| 当接收端接受了大量数据后,如果立刻返回ACK,此时ACK中“窗口大小”属性的值,就会比较小。 |
| 发送端在收到这条ACK后,就会降低数据的发送速率,以适应这个“窗口大小”。 |
| 延时应答就是,接收端在收到大量数据后,不立刻返回ACK,而是等待读取接收缓冲区的数据之后,再行返回ACK。此时ACK中“窗口大小”属性的值,就会比较大。 |

2)延时应答的作用
| 窗口越大,网络吞吐量就越大,传输效率就越高。 |
| 延时应答就是为了在保证网络不拥塞的情况下,尽量提高传输效率。 |
八、捎带应答
1)什么是捎带应答?
| 捎带应答的意思就是字面意思,服务器端返回响应时,捎带了其他的报文段。将原本的两条数据报合并为一条数据报,进行返回。 |
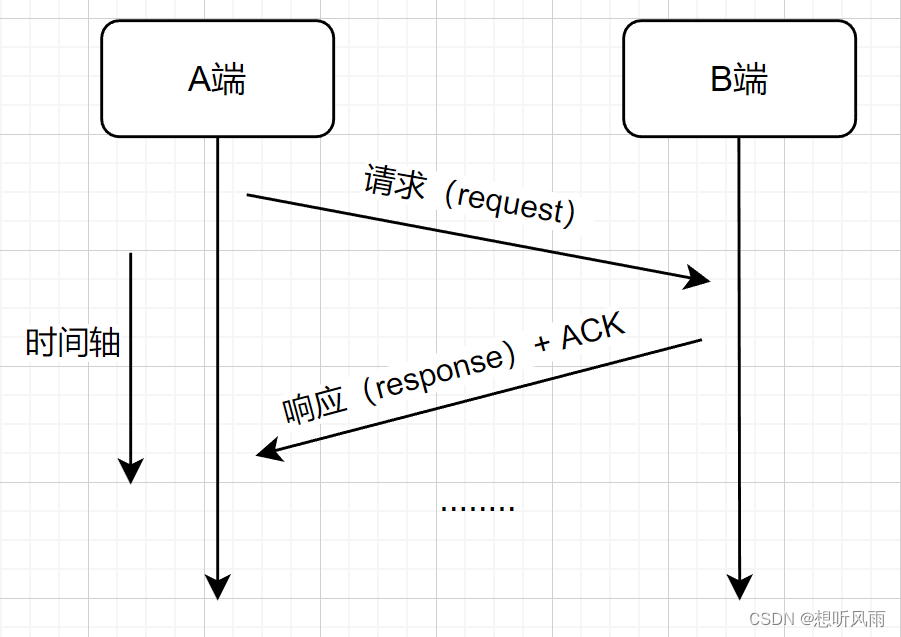
2)捎带应答的作用
| 原本需要传输两条数据报,就封装分用两次。通过捎带应答,将这两条数据报合并为一条,也就只需要封装分用一次了。这在延时应答的基础上,进一步提升了传输效率。 |
九、面向字节流
1)沾包问题
| TCP以字节流传输数据,接收端从接收缓存区中读取字节数据。 |
| 以应用层角度看,收到的数据都是一个个的字节,无法区分应用层数据包从哪个字节开始到哪个字节结束。就类似数据包都粘到一起了,因此称为“沾包问题”。 |
2)“沾包问题”如何处理?
| “沾包问题”的本质是应用层无法知道数据包开始和结束,也就是数据包的边界。 |
| 因此,要处理“沾包问题”,就要明确数据包的边界在哪里。 |
| 大体上可以通过以下两种方式处理沾包问题: |
| <1> 明确分隔符:在两个数据包之间使用分隔符,这个分隔符就属于应用层协议的内容,由程序员自定义。应用程序读取到这个分隔符,则认为得到了一个完成的数据包。 |
| <2> 明确数据包长度:在数据包的包头写入该数据包的长度,应用程序按照这个长度读取数据,就得到一个完整的数据包。 |
3)UDP协议会不会出现“沾包问题”?
| UDP协议不会出现“沾包问题”。因为“沾包问题”的本质是数据包边界不明确。 |
| 而UDP协议是面向数据报的,一个数据报就是一个包。因此数据包边界明确。 |
阅读指针 -> 《 TCP 的通信机制(六) -- 异常情况处理 和 总结 》
文章来源:https://blog.csdn.net/zzy734437202/article/details/135258888
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!