Redis原理篇(Dict的收缩扩容机制和渐进式rehash)
Dict(即字典)
Redis是一种键值型数据库,其中键与值的映射关系就是Dict实现的。
Dict通过三部分组成:哈希表(DictHashTable),哈希节点(DictEntry),字典(Dict)
其中哈希表的底层是数组(发生冲突时扩展成链表),用来存放哈希节点。
下面是哈希表和哈希节点的源码


首先看到dictht,即DictHashTable的缩写,下面是对其中属性的解释:
?dictEntry **table是哈希表的数组,每个元素都是一个指向 dictEntry 结构体的指针。这里使用双指针 ** 的原因是为了实现动态数组。
size是哈希表的大小
sizemask是用来对键值进行与运算(与取余结果一致,但是用与运算更快)。
used是节点个数
然后看到dictEntry,是节点,下面是对其中属性的解释:
key是键很好理解;
union是一个联合函数,意思是v可以是{}里面的任意一个值。
注意:发生hash冲突时,新元素添加在链表首位,再让新元素的next指向原来的链表的头,这样比较方便,如果把新元素添加到链表尾部的话要对链表进行变量,很麻烦。
Dict的扩容
Dict是通过数组和单向链表实现的,当存放数据越来越多,导致大量的哈希冲突,使得链表长度过长,这样的话查询效率就大打折扣。出现这种情况的根本原因是数组小了,所有解决方案就是对数组进行扩容。
负载因子 =节点个数/数组大小

下面是包含扩容 的代码

Dict的收缩
除了扩容外,当出现频繁的删除造成entry个数较少,而数组大小过大的资源浪费的情况时,就需要对Dict进行收缩,收缩的条件是:

下面是Dict收缩的代码
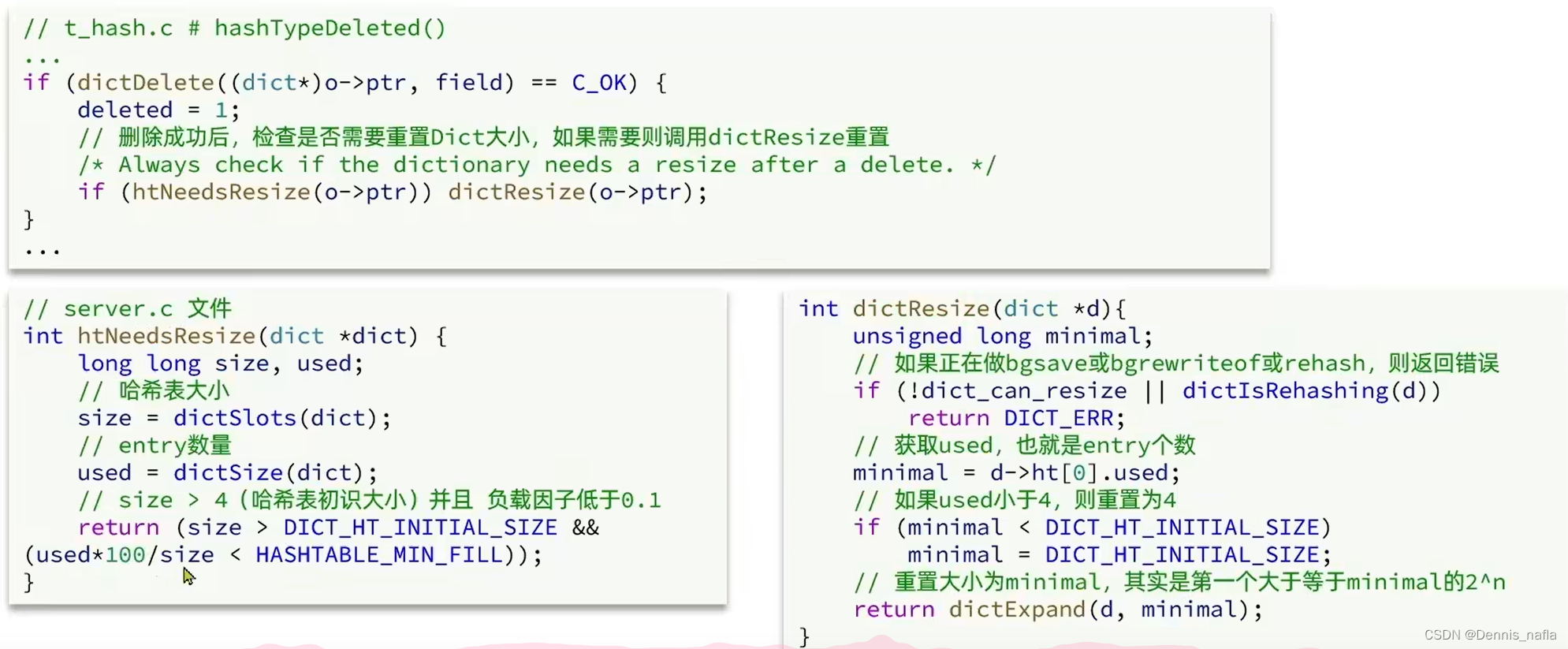
?可以看到收缩和扩容以及Dict初始化时都用到了dictExpand这个函数,主要的逻辑还是在这个函数里面的,所有我们来看看这个函数源码:
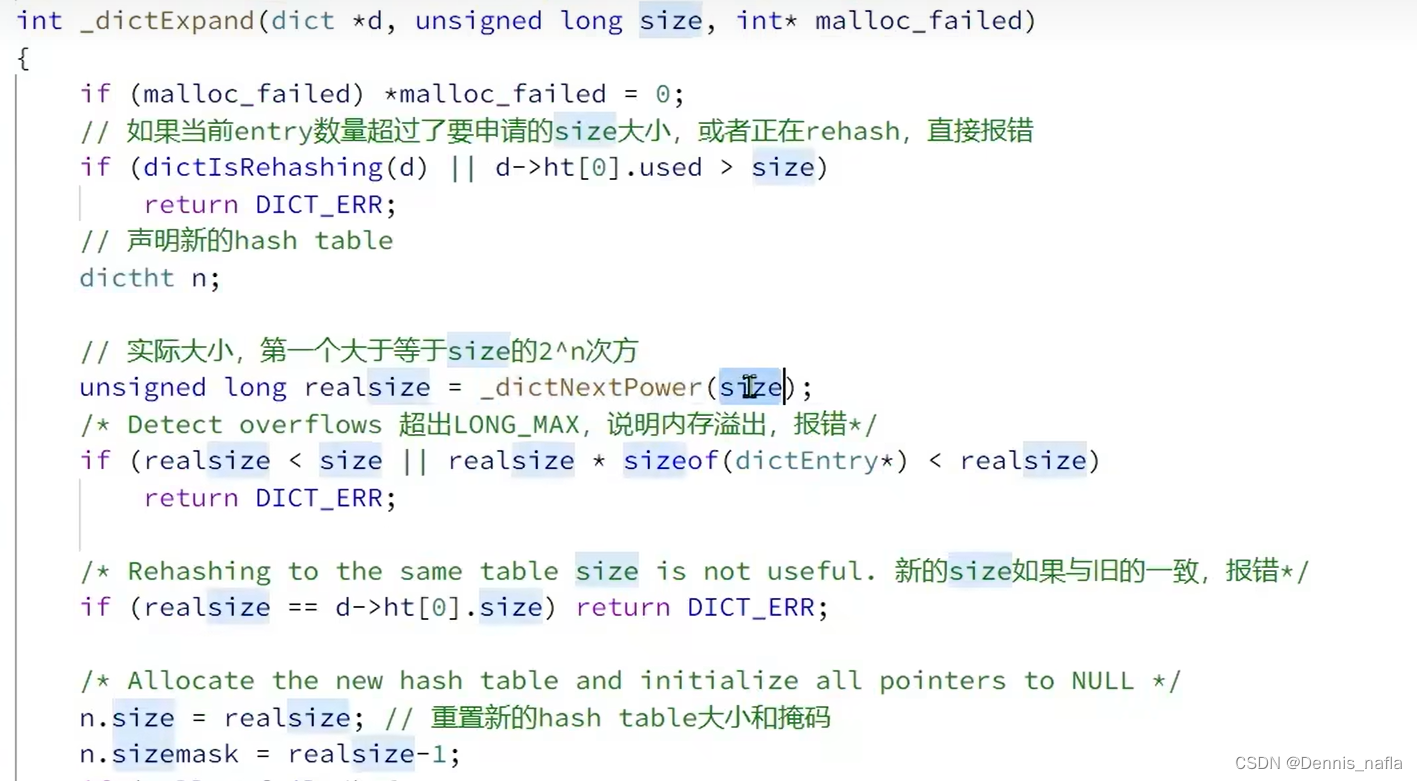
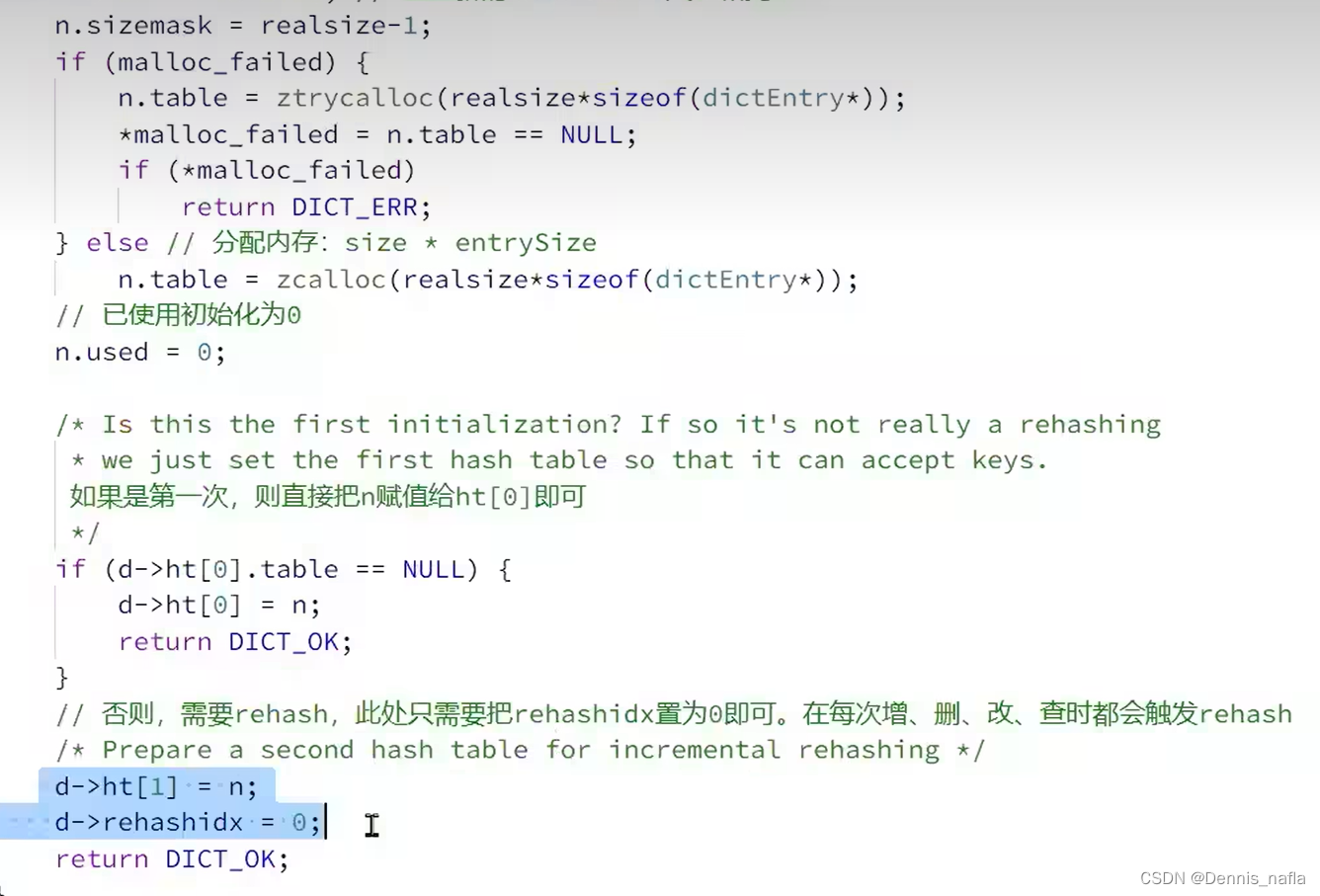
?注意到这里有个rehash的操作,为什么要进行这个操作呢?
扩容和收缩不就是改变数组的大小吗?直接改不就行了?
显然,这样是不行的,因为Dict的删除,查询,更改都是要通过键值来找到对应entry的,当我数组的大小改变,那么我使用原来的hash函数运算得到的就不是原来的那个key了。
因为key的查询与sizemask有关,这个sizemask变化了,那么就当然得不到原本的那个key。
再注意到,这个dictExpand函数内部并没有进行具体的rehash的操作,
只是将rehashidx赋值为了0,
这个rehashidx还有印象吗?我帮忙回忆一下:
没错,就是这个rehash的进度。
那为什么不在dictExpand函数里面一次性将ht[0]全部赋值给ht[1]呢?
答案如下:?
Rehash

?但是渐进式rehash也有个问题,就是每次增删改查都只迁移一个entry链表(包含key对应的entry以及由hash冲突导致生成的链表),这个进度是比较缓慢的,那在增删改查的时候会遇到问题,因为此时数据在2张表里面,ht[0]和ht[1],怎么办?
其实也很简单,首先在新增的时候肯定是将新的entry给ht[1],因为要是写进了ht[0],到时候还是要给ht[1];
然后是删除,更改,查询,这两张表都访问一遍就行了。数据反正不在ht[0]就在ht[1]。
因为是使用指针这种数据结构,从ht[0]迁移到ht[1]就是改个指针指向的操作就行,很方便,并且改变了指针的指向后,ht[0]里面就查不到移走的那个entry链表了,不用考虑是否要在ht[0]里面删除一次再到ht[1]里面删除一次的问题。
这里有个演示可以看一下:
1.size是4,现在又第5个元素要加进来,并且后台没有进行resave等操作,开始进行扩容操作
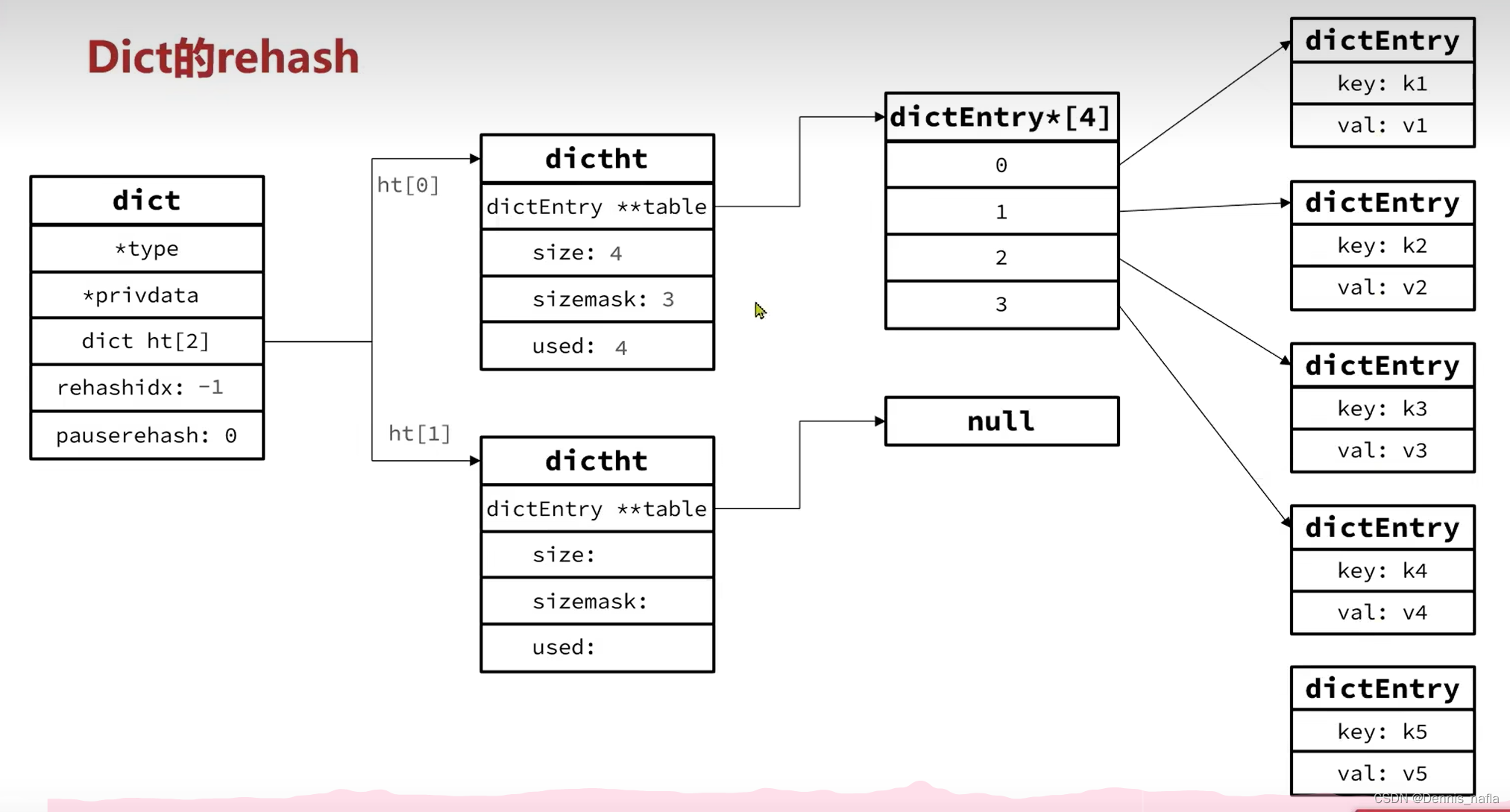
2.现在元素个数是5,比5大一是6,第一个比6大的2的n次方是8,
申请内存空间,大小是8个entry赋值给ht[1]
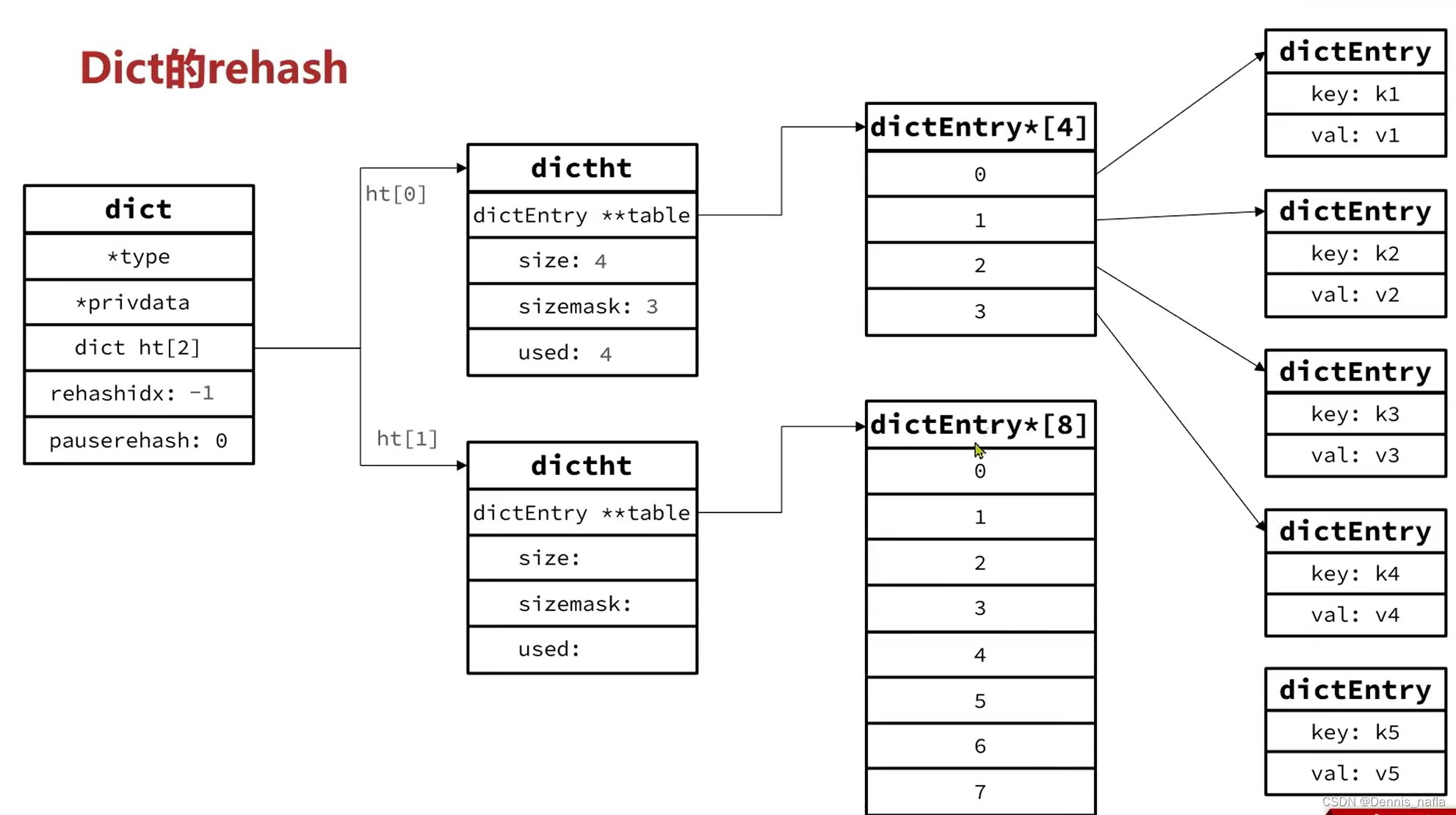
3.把rehashidx赋值为0,表示可以开始rehash

4.在增删改查时发现rehashidx不是-1,就从ht[rehashidx]开始,一个一个迁移到ht[1]
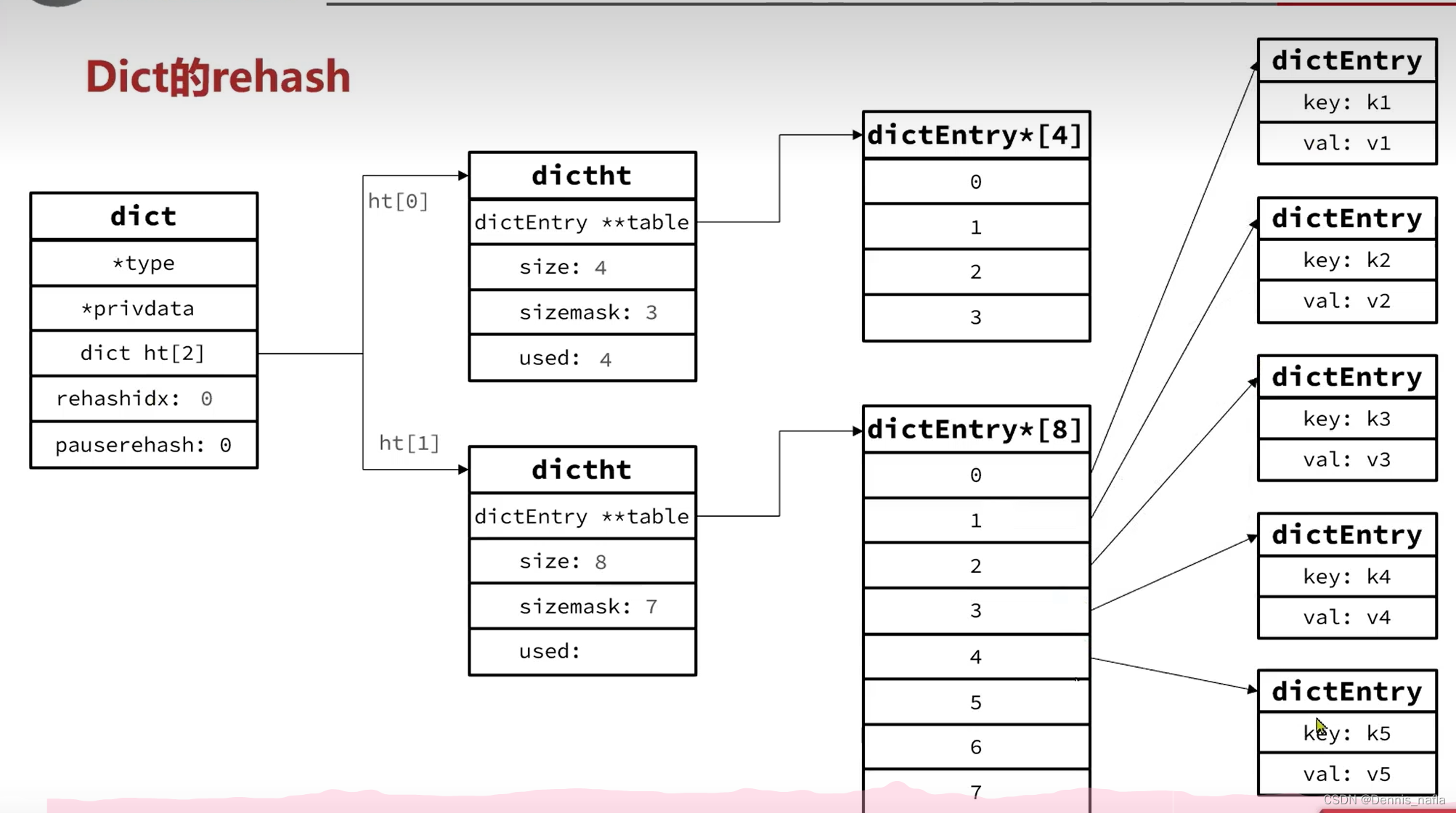
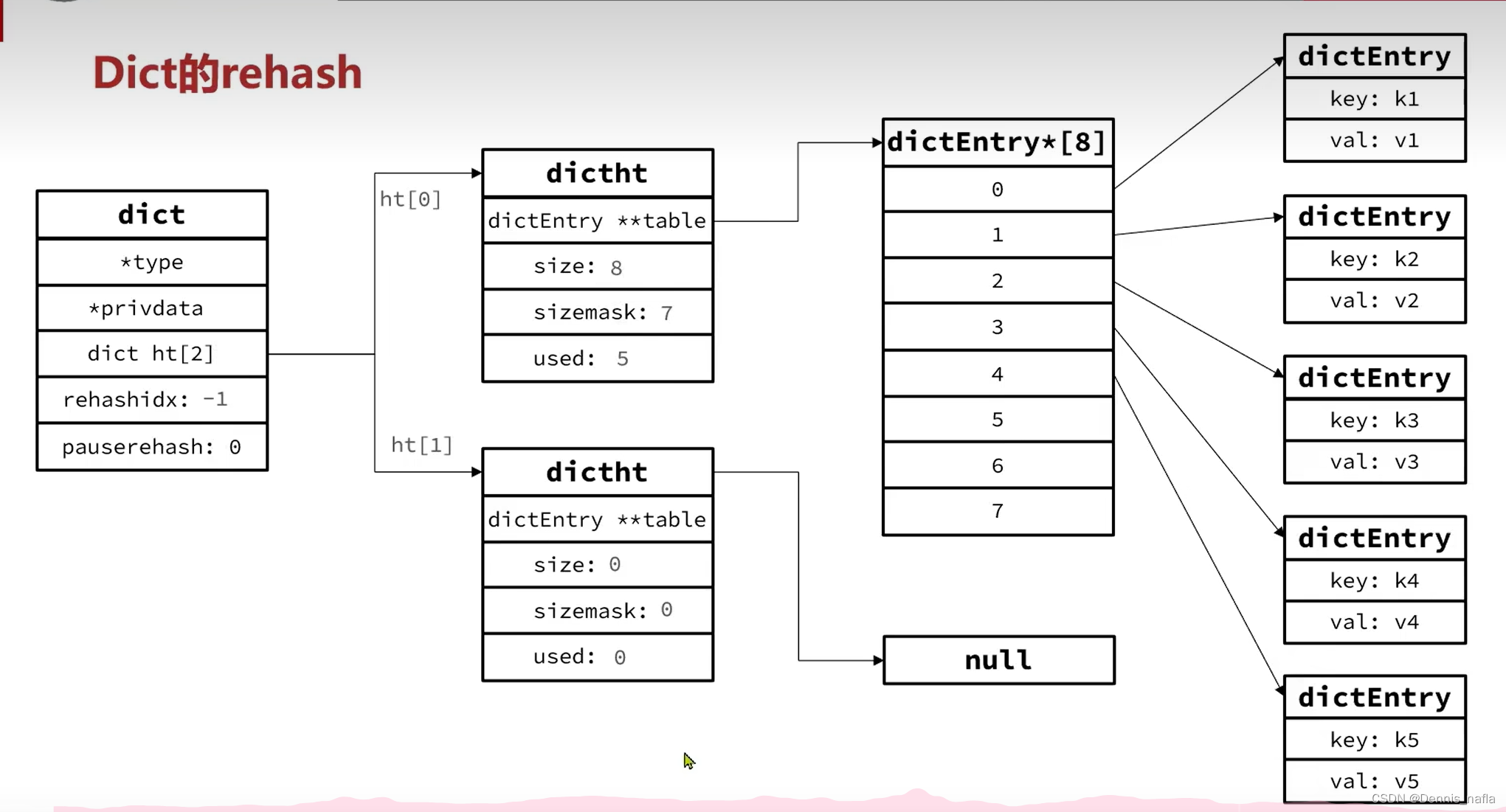
5.迁移完毕后就将ht[1]下的新的hash表转移到ht[0],再将rehashidx赋值-1,还有size等属性也要更改,ht[1]的size,sizemask,used重新置为0,hash表置为null
至此,rehash完成
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Selenium框架添加CONNECT以抓取https网站
- 【网络安全】SQL注入总结
- 【INTEL(ALTERA)】Arria V FPGA GPIO 引脚上的内部箝位二极管是否始终处于活动状态?
- Python文件命名规则:批量重命名与规则匹配的文件
- 基于Java SSM框架实现个人健康信息管理系统项目【项目源码+论文说明】计算机毕业设计
- undefined reference to `pthread_create‘的另外一种解法
- 稍微来一下MySQL进阶复习
- 用CHAT了解生活中的化学
- 机器学习之实验过程01
- Go语言中的Channel