混合精度训练(MAP)
一、介绍
使用精度低于32位浮点数的数字格式有很多好处。首先,它们需要更少的内存,可以训练和部署更大的神经网络。其次,它们需要更少的内存带宽,这加快了数据传输操作。第三,数学运算在降低精度的情况下运行得更快,特别是在支持Tensor Core的gpu上。混合精确训练实现了所有这些好处,同时确保与完全精确训练相比,没有任务特定的准确性损失。它通过识别需要完全精度的步骤,并仅对这些步骤使用32位浮点数,而在其他地方使用16位浮点数来实现这一点。
在大模型训练场景中,最占用显存的是中间激活值,而混合精度训练方法是采用半精度保存,显存空间直接减半而且还能加速计算; 中间激活值占用显存的直观感觉如下:

二、混合精度训练
混合精度训练以半精度格式执行操作,同时以单精度存储最小的信息,以尽可能多地保留网络关键部分的信息,从而显著提高了计算速度。自从在Volta和Turing架构中引入Tensor Cores以来,通过切换到混合精度,可以体验到显著的训练速度提升——在大多数算术密集的模型架构上,总体速度提升了3倍。使用混合精度训练需要两个步骤:
1. 移植模型以在适当的地方使用FP16数据类型。
2. 添加损失缩放以保持小的梯度值。
在Pascal架构中引入了以较低精度训练深度学习网络的能力,并在CUDA 8的NVIDIA深度学习SDK中首次得到支持。
混合精度是指在计算方法中组合使用不同的数值精度。
与更高精度的 FP32 相比,半精度(也称为 FP16)数据与 FP64 相比减少了神经网络的内存使用,允许训练和部署更大的网络,并且 FP16 数据传输比 FP32 或 FP64 传输花费的时间更少。
单精度(也称为 32 位)是一种常见的浮点格式( float 在 C 派生的编程语言中),而 64 位则称为双精度 ( double )。深度神经网络 (DNN) 在许多领域取得了突破,包括:
- 图像处理和理解
- 语言建模
- 语言翻译
- 语音处理
- 玩游戏等等
为了实现这些结果,DNN 的复杂性一直在增加,这反过来又增加了训练这些网络所需的计算资源。降低所需资源的一种方法是使用精度较低的算术,它具有以下优点:
减少所需的内存量
精度浮点格式 (FP16) 使用 16 位,而单精度 (FP32) 使用 32 位。降低所需的内存可以训练更大的模型或使用更大的小批量进行训练。
缩短训练或推理时间
执行时间可能对内存或算术带宽敏感。半精度将访问的字节数减半,从而减少了在内存受限层中花费的时间。与单精度相比,NVIDIA GPU 的半精度算术吞吐量提高了 8 倍,从而加快了数学受限层的速度。
图 1.bigLSTM 英语语言模型的训练曲线显示了混合精度训练技术的好处。Y 轴是训练损失。不带损耗缩放的混合精度(灰色)在一段时间后会发散,而带损耗缩放的混合精度(绿色)与单精度模型(黑色)匹配。
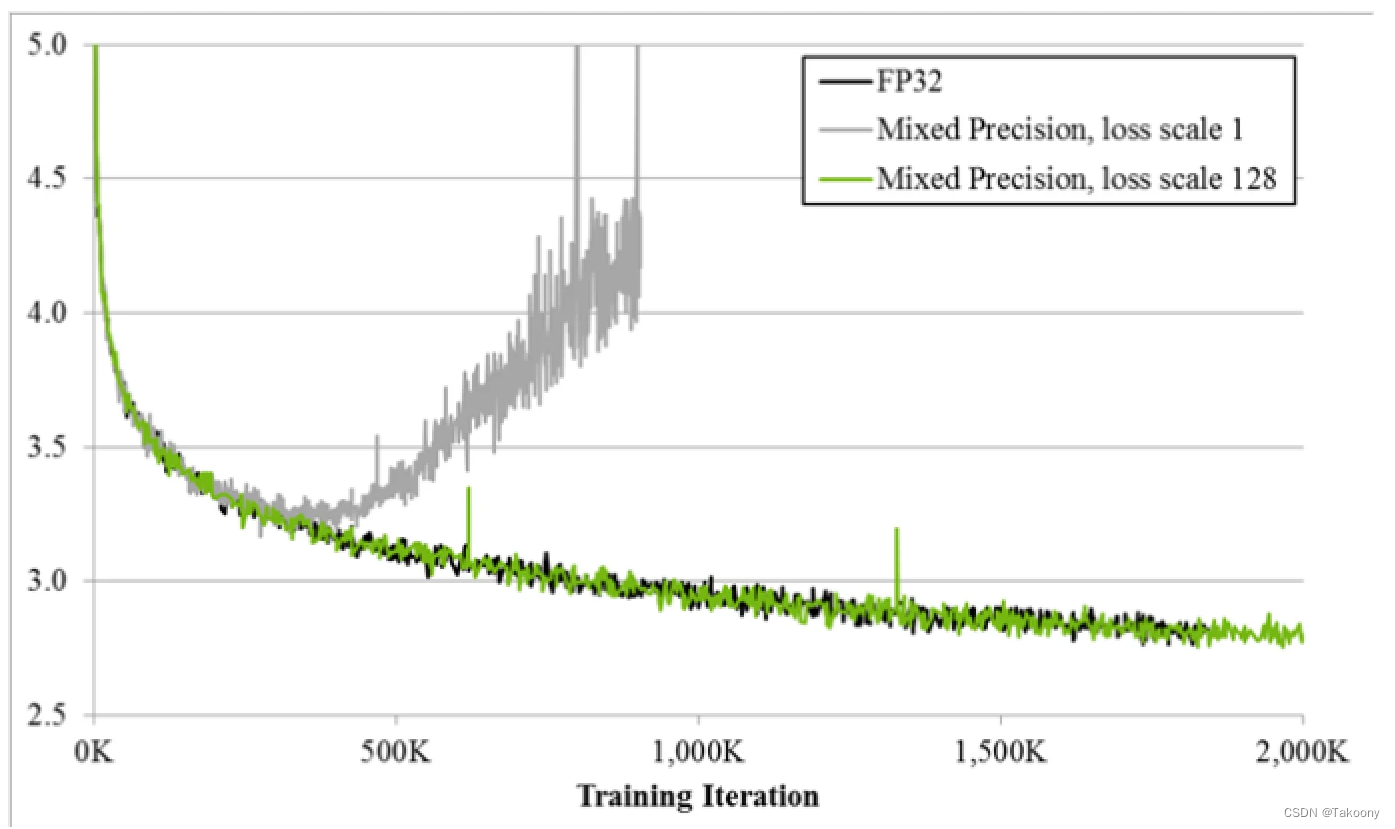
由于 DNN 训练传统上依赖于 IEEE 单精度格式,因此本指南将重点介绍如何以半精度进行训练,同时保持以单精度实现的网络精度(如图 1 所示)。这种技术称为混合精度训练,因为它同时使用单精度和半精度表示。
2.1 半精度格式
IEEE 754 标准定义了以下 16 位半精度浮点格式:1 个符号位、5 个指数位和 10 个小数位。
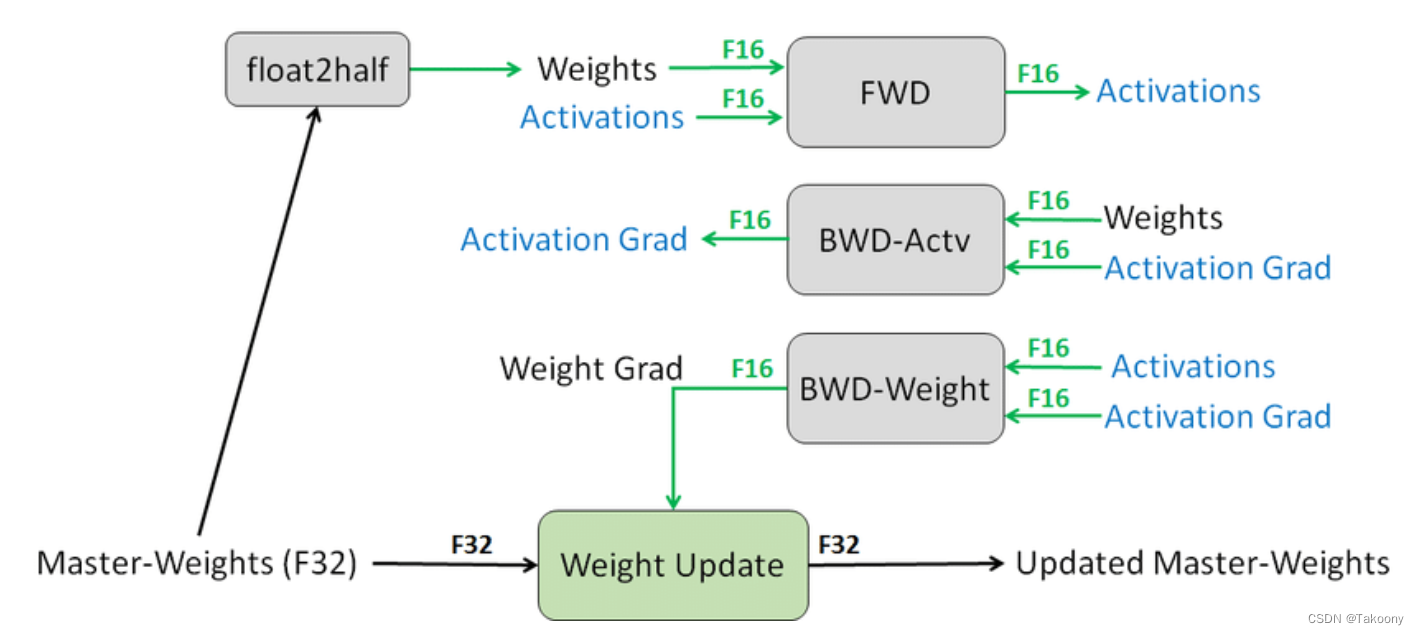
2.2 混合训练的流程
2.2.1 拷贝一份FP32的权重
2.2.2 用较大的值初始化缩放因子S.
2.2.3 进入迭代中:
- a 生成一份FP16的权重
- b. 前向传递(FP16权重与中间值)
- c.计算的loss乘以缩放因子S.
- d. 反向传递 (FP16权重, 中间激活值, 梯度)
- e. 如果权重梯度中存在无穷大(Inf)或不是一个数字(NaN):
- 减小S的值
- 跳过权重更新,并进行下一次迭代。
- f.将权重梯度乘以1/S
- g.完成权重更新(包括梯度裁剪等操作)
- h. 如果在最近的N次迭代中没有出现无穷大或不是一个数字的情况,则增加S的值。
三、混合精度相关问题
- 抓住主要矛盾,目的是减少中间激活的显存占用
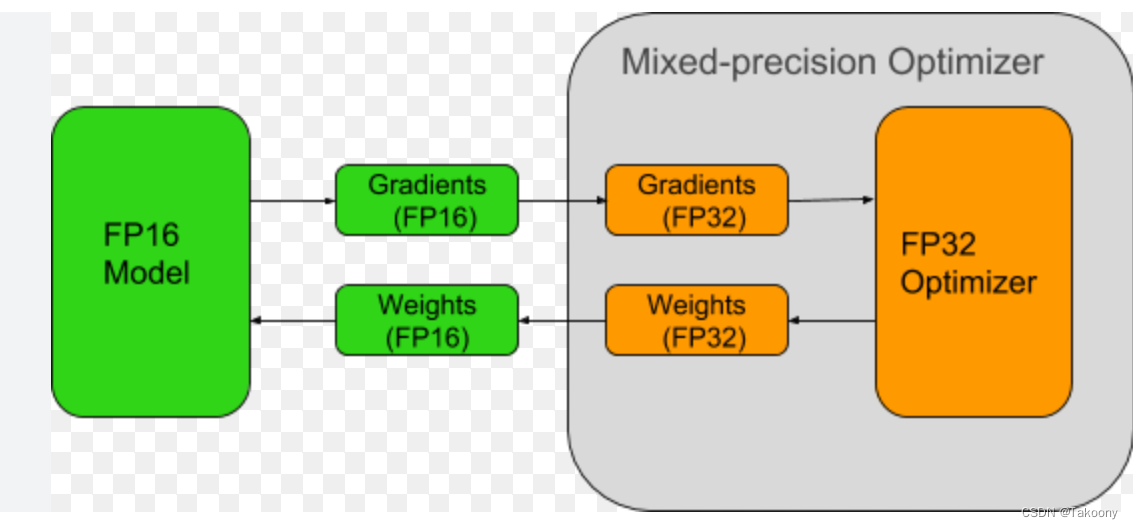
- 在网络训练的后期,梯度值会变得非常小,缩放loss计算得到梯度后,可以用fp32存储,然后进行unscale,避免学习率*unscale *fp16梯度下溢,流程如下(最好是配上scale因子就更完美了,如果不加scale,会存在fp16的gradients存在下溢的可能):
四、PyTorch实现
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!