【无标题】
引言
随着大型语言模型(LLM)在自然语言处理领域的日益重要,新型多语言多任务模型——TigerBot-70B的问世,标志着全球范围内一个新的技术里程碑的达成。TigerBot-70B不仅在性能上匹敌行业巨头如OpenAI的模型,而且其创新算法和数据处理方式在行业内引起广泛关注。
-
Huggingface模型下载:https://huggingface.co/TigerResearch
-
AI快站模型免费加速下载:https://aifasthub.com/models/TigerResearch
型概览
TigerBot-70B是一款集成700亿参数的多语言多任务LLM,其基于OpenAI InstructGPT论文框架,并在多个公开NLP数据集上进行自动评测。最显著的成就是,即使只是最小可行产品(MVP),TigerBot-70B的综合表现已达到OpenAI相同大小模型的96%。

核心特点
-
模型和数据: TigerBot-70B提供了多个版本。该模型是在Llama-2-70b的基础上,通过300B tokens多语言数据继续预训练而来,着重于数据的质量和多样性。
-
算法创新: 模型采用了诸如GQA (group-query-attention), flash-attention, RoPE (rotary-position-embedding), holistic-training等前沿算法,确保了高计算效率与卓越的模型性能。
-
训练优化: 在训练过程中,TigerBot-70B使用了tensor/pipeline-partition技术,有效突破了内存和通信限制,实现了在大规模分布式环境下的高效训练。
-
微调策略: TigerBot-70B-base在20M指令完成数据上进行SFT微调,同时采用人类标注的10K gold-set数据进行rejection-sampling的对齐微调,进一步提升了模型的实用性和准确性。
训练和数据处理
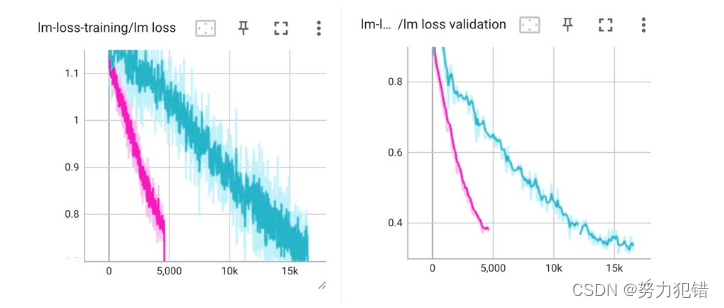
在TigerBot-70B的训练过程中,特别重视数据的质量和处理方式。开发团队通过精心设计的数据清洗算法,去除了网络口语化和低知识密度等问题,确保了数据的高质量。
模型评测
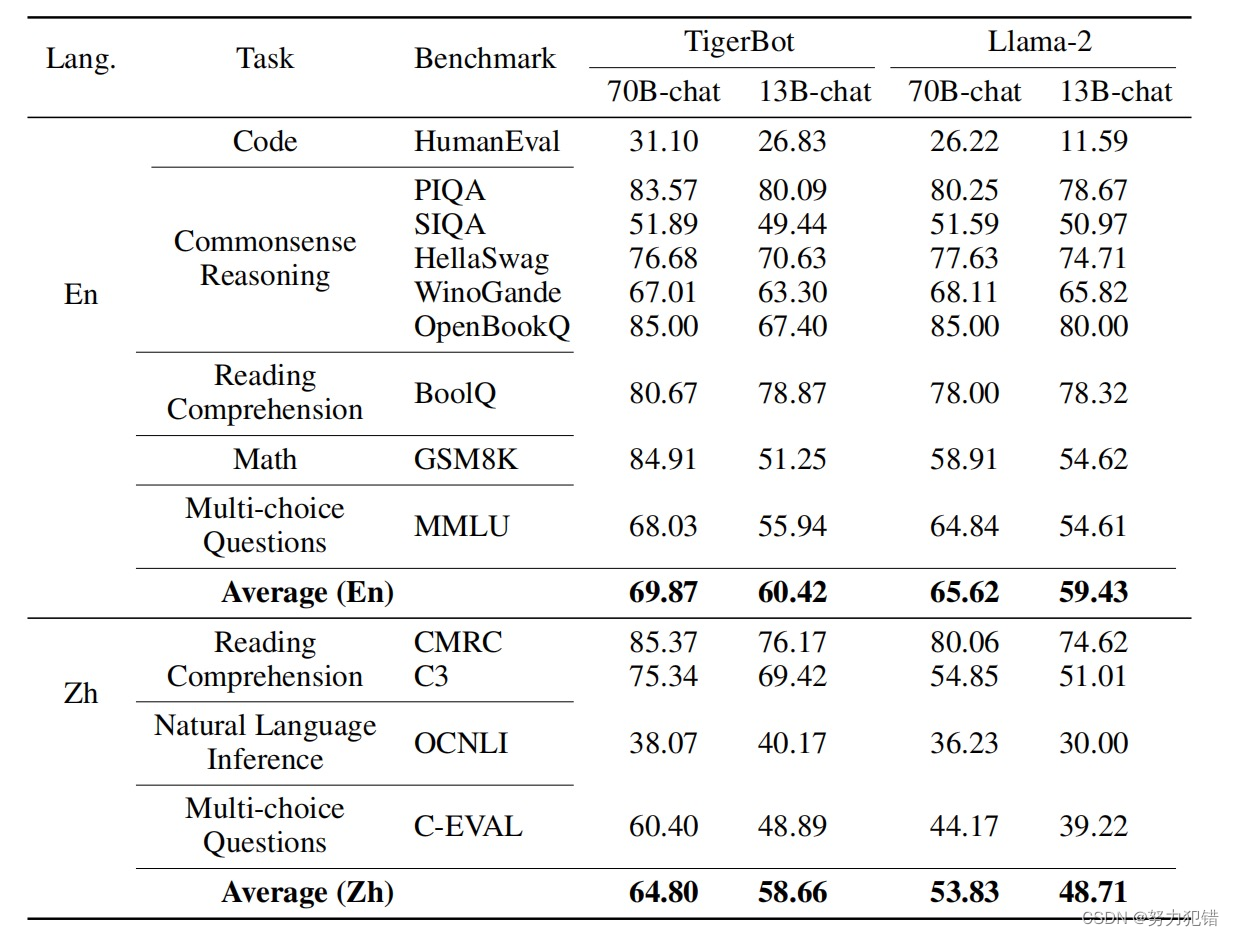
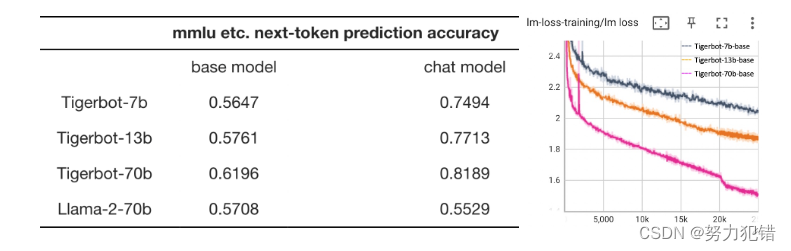
TigerBot-70B在业内主流的10项基准测试集上进行了全面评测,这些测试集包括mmlu, arc, squad_v2等。评测结果显示,TigerBot-70B在阅读理解、推理、世界知识、常识问答、数理和代码等领域的能力均优于Llama-2-70B,标志着它在全球范围内的领先地位。
结语
TigerBot-70B的问世,不仅展示了数据驱动和算法创新在LLM领域的重要性,更为全球的AI研究和应用开发者提供了新的、强大的工具。随着模型的开源和免费商用政策,TigerBot-70B预计将在教育、科研以及更广泛的行业应用中发挥重要作用,推动整个AI领域的进一步发展。
模型下载
Huggingface模型下载
https://huggingface.co/TigerResearch
AI快站模型免费加速下载
https://aifasthub.com/models/TigerResearch
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 广受好评的开源基础大模型最全梳理,你最钟意哪一个?
- Python求特殊a串数列和
- 从 Google Gemini 到 OpenAI Q*(Q-Star):调研重塑生成人工智能(AI)的研究
- log4j日志切割原理
- 【深度学习-图像分类】02 - AlexNet 论文学习与总结
- 一起学Elasticsearch系列-并发控制
- Java中四种引用类型(强、软、弱、虚)
- 【Antlr】Antlr 使用语法分析树监听器编写程序、Antlr 解析 Properties 格式、监听器模式
- 【文档数据库】ES和MongoDB的对比
- ZZULIOJ 1125: 上三角矩阵的判断