nodejs前端项目部署到k8s,导致线上故障的排查与解决方法
文章目录
前言
因我们的前后端项目都部署在k8s集群中,前端项目采用npm和node管理
事故背景: 某天前端同事在测试环境更新完一个前端服务后,访问正常,然后按照正常流程上线到生产环境,但是,在生产环境更新完成后,测试同事反馈访问报502错误,我就去服务器排查刚才发布的服务,检查pod状态是RUNNING状态,更新时间也是几分钟前,从表面看没有问题,由此,赶紧回滚镜像,停止上线,拉开问题排查与解决之路~
一、从测试环境开始排查
与前端同事沟通,该前端服务启动后会有一个3001端口
使用命令进入到刚才更新的pod中
kubectl exec -it k8s-xxx-xxx-1960-0 -- /bin/bash
netstat -lntp |grep 3001
ps -ef
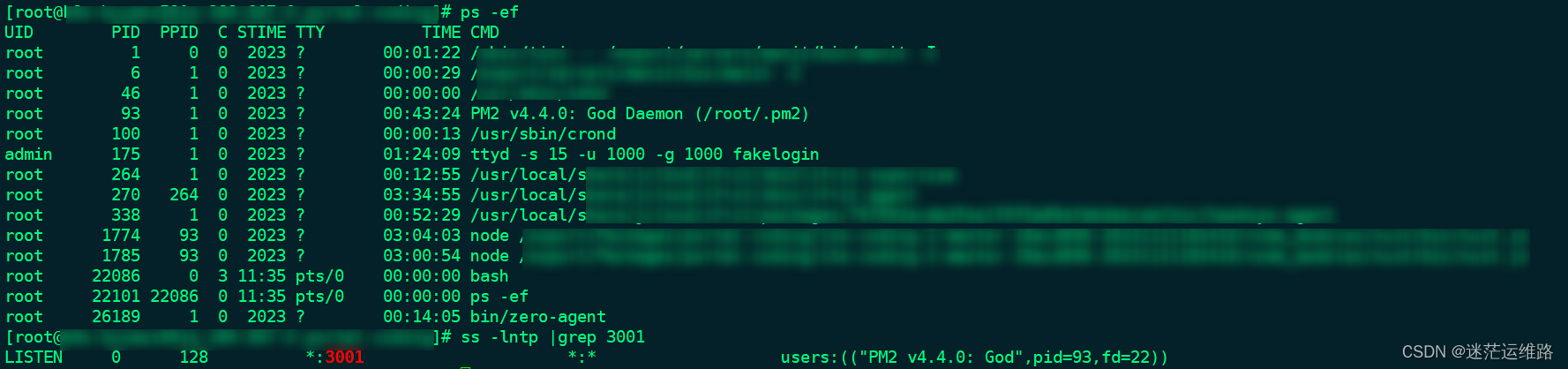
由上图所示,测试环境的服务启动后,有对应的端口及进程服务,因此我猜测生产环境该服务并未完全启动导致更新后报502问题
二、生产环境排查
1.复制对应服务的deployment、svc、ingress的 yaml文件,修改服务名、镜像,然后手动进行发布
2. 发布之后访问还是502,然后采用测试环境的排查方法,最终确认该服务pod启动后,对应的端口、进程都没启动,怀疑是假启动,但是pod是RUNNING的,给人造成了迷惑
3.进入到该容器中
kubectl exec -it k8s-xxx-xxx-2360-0 -- /bin/bash
netstat -lntp |grep 3001
ps -ef
发现服务并未启动,也没有相关进程
4.在容器中手动执行启动命令
FROM node:12.19.0
WORKDIR /output
COPY ./output /output
EXPOSE 3001
ENV NODE_ENV=production
CMD nohup npm run start >out.log 2>&1 && tail -f out.log
根据dockerfile找到对应的启动命令,手动启动
npm run start
再次检查,发现服务能正常启动,且访问正常
至此,已确认问题: 生产环境502问题是因为服务启动造成的,那么具体未启动的原因是什么?请看下面描述
经过在网上查找相关问题、以及问其他前端同事,最终确认是因为pm2导致环境变量过多引起的。K8S启动时会给容器注入环境变量,K8S集群中的项目数越多,环境变量也就越多。使用PM2进行node进程的管理会在启动时会导入系统中的环境变量,当环境变量数量过多时,就会导致服务启动失败。

5.检查测试环境与生产环境该服务中的环境变量个数
5.1、进入测试环境该服务的容器中,执行 env |grep wc -l命令,如下图所示,总共396个环境变量,比较少
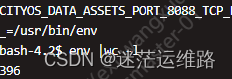
5.2、进入生产环境该服务的容器中,执行 env |grep wc -l命令,如下图所示,共有2594个环境变量

6.解决方法
方法一、
和研发确认不相干的环境变量,然后修改启动脚本,添加要取消掉的相关变量 A_BJ01|B_BJ01|EXPO_|10,如下所示 在pm2启动前清除系统中的环境变量
#!/bin/sh
cd "$(dirname $0)"/.. || exit 1
echo "$(dirname $0)"
PROC_NAME='xxx'
help(){
echo "${0} <start|stop|restart|status>"
exit 1
}
status(){
wcx=`ps -eo "command" | grep PM2 | wc -l`
if [ $wcx == 1 ]; then
status="offline"
else
status="online"
fi
echo $status
if [ X"$status" == X"online" ]; then
return 0
else
return 1
fi
}
start(){
#修改A_BJ01|B_BJ01|EXPO_|10此处变量即可
for i in `env | grep -E -i 'A_BJ01|B_BJ01|EXPO_|10' | sed 's/=.*//'` ; do
unset $i
done
NODE_ENV=production
pm2 start
sleep 3
status
}
请根据自己环境中的变量进行修改,不可直接粘贴使用
让研发同事将该脚本上传到对应的代码仓库,重新进行CICD操作,然后检查对应的服务端口和进程以及环境变量,发现启动成功,完美解决问题。
方法二、
在报错服务的deployment.spec.template.spec模块下添加如下内容,其中enableServiceLinks 表示是否将 Service 的相关信息注入到 Pod 的环境变量中,默认是 true:
enableServiceLinks: false
总结
以上就是今天要分享的内容,也是第一次遇到这个问题,主要是不熟悉前端node和pm2,解决方法也是网上找方案及问同事,不过最终还是有用。在解决完上线问题后,前端同事本地调试pm2,打印打console.log,也发现是环境变量参数的长度异常,最终定位是process.env会获取操作系统的所有变量,造成process.env多达70000以上字节长度。占了99%的process.env长度,并且皆为无用变量。因此,为了避免生产和测试环境再次出现该问题,对每个服务都进行了环境变量的筛选,通过脚本的方式在pm2启动前进行没用的环境变量清理,确保后续服务发版顺利!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Keil新建工程
- Elasticsearch之常用DSL语句
- 文件句柄数设置-linux
- Cesium 点击实体显示可随地图移动的弹框
- 我发现了一个还行的生成图片的网站(新人登录可领30金币)
- 亚信安慧AntDB数据库开启分布式数据库的新篇章
- RabbitMQ集群的简单说明
- CyberLink的颜色修正软件ColorDirector Ultra 2024 12.0版本在windows系统下载与安装配置
- 04进程原语-学习笔记
- 定时任务-理论基础