ML Design Pattern——Keyed Predictions

In today's world of massive datasets and real-time decision-making, machine learning (ML) systems face unique challenges in terms of scalability and efficiency. To address these challenges, a set of design patterns have emerged, each offering specific strategies to enhance ML performance and robustness. One such pattern, Keyed Predictions, stands out as a powerful approach for optimizing prediction pipelines, particularly in scenarios involving large-scale batch predictions and model updates.
Keyed Predictions: A Blueprint for Efficient Batch Processing
Core Principle: This pattern introduces the concept of associating each prediction request with a unique key. This key serves as a critical link between the input data, model computations, and output predictions, enabling several optimization techniques:
- Grouping and Caching:?By grouping requests based on their keys, systems can leverage caching mechanisms to avoid redundant computations for frequently seen input patterns. This significantly reduces the load on models and improves overall throughput.
- Parallelization and Distribution:?Keyed Predictions naturally facilitate parallel processing of prediction requests. By partitioning data based on keys, tasks can be distributed across multiple compute nodes or GPUs, enabling efficient scaling of model serving infrastructure.
- Incremental Updates:?In scenarios where models are continuously updated with new data, Keyed Predictions enable efficient model updates by focusing only on the relevant portions of the model affected by specific keys. This minimizes downtime and resource consumption during model updates.
Key Use Cases:
- Recommendation Systems:?Generating personalized recommendations for millions of users often involves large-scale batch predictions. Keyed Predictions streamline this process by grouping requests based on user IDs, enabling efficient caching and parallelization.
- E-commerce Search:?Handling large volumes of search queries in real-time requires a scalable prediction infrastructure. Keyed Predictions, using query keywords as keys, optimize query processing and result ranking.
- Fraud Detection:?Identifying fraudulent transactions in large financial datasets benefits from Keyed Predictions using transaction IDs for efficient model updates and risk scoring.
Implementation Considerations:
- Key Selection:?Careful selection of the key attribute is crucial, considering data distribution, prediction frequency, and caching requirements.
- Data Storage and Retrieval:?Efficient data structures and storage mechanisms are essential to support key-based grouping and access.
- Caching Strategies:?Implementing appropriate caching policies, such as least recently used (LRU) or time-based expiration, is vital for maximizing performance benefits.
- Parallelization Frameworks:?Leveraging frameworks like MapReduce or Apache Spark can simplify the implementation of parallel prediction pipelines.
Conclusion:
Keyed Predictions offer a valuable approach to enhance the scalability and efficiency of ML prediction pipelines. By understanding its core principles, use cases, and implementation considerations, ML engineers can effectively apply this design pattern to build robust and performant ML systems that can handle the demands of real-world applications. Embrace Keyed Predictions to unlock the potential of your ML models and deliver predictions at scale with optimal resource utilization.
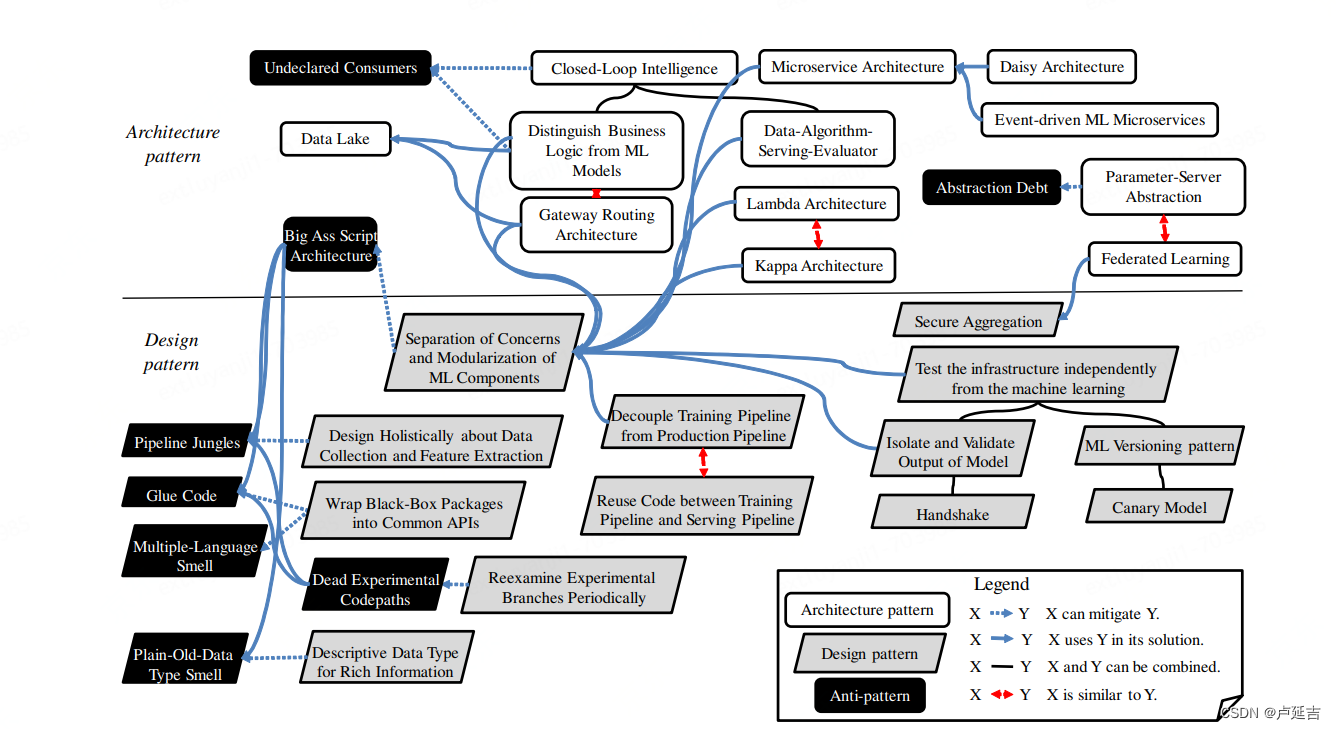
Machine Learning Architecture and Design Patterns
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 药品生产企业数据库-医药系统软件
- 部署nginx虚拟主机及SSL虚拟主机
- MES智能制造系统,定制智造工厂的“大脑”,提升生产力智慧之选
- 读取txt中文件到一个std::string类型中
- git commit使用husky校验代码格式报错 因为没有将钩子 ‘.husky/pre-commit‘ 设置为可执行
- 【C++】哈希表
- [Java][网络编程]服务端向客户端发送信息
- Vue3使用高德地图,自定义InfoWindow窗口
- 力扣移掉k位数字402
- FFmpeg转码分辨率会变化的视频