【C++】内存对齐
本篇文章介绍C++中的内存对齐,后续介绍C的union和C++的variant的时候,需要用到这部分的知识。
占用内存
先回忆下C++各个数据类型占用的内存大小:
- int:所占内存大小:4byte = 32bit;
- char:所占内存大小:1byte = 8bit;
还有其他的数据类型,但是今天就只用这两个。
我们写个结构体:
struct s{
int x;
char y;
};
它占用多少byte的内存呢?并不是4+1=5,而是4+4=8.
int main()
{
printf("%d\n",sizeof(s)); // 输出8
return 0;
}
分析内存
处理器并不是按字节块来存取内存的。它一般会以2字节,4字节,8字节,16字节甚至32字节为单位来存取内存.我们将上述这些存取单位称为内存存取粒度.写代码的人一般会觉得所有数据结构都会像数组一样有随机存取的特性,变量之间是紧挨着的,但是对于不同类型的变量来说,从内存向寄存器转移数据的过程并不总是顺利的。
以下图片来自https://blog.csdn.net/dxpqxb/article/details/90485917,我懒得画图了,就直接用现成的了。
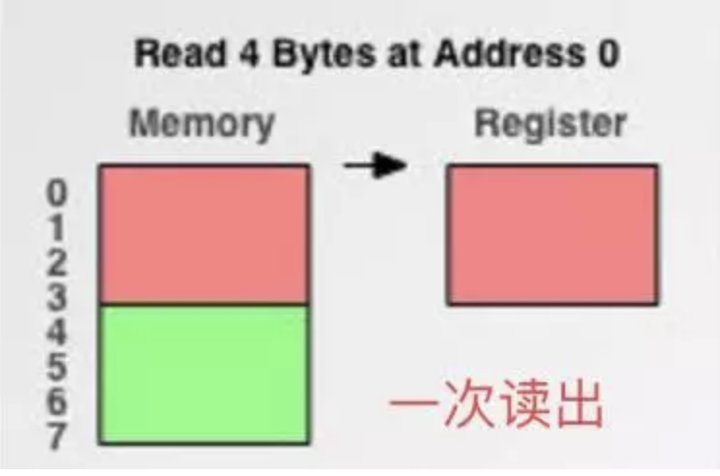
现在有4byte的数据存放在内存中,他们的地址如下:
| 数据 | 首地址 | 末地址 |
|---|---|---|
| A | 0 | 3 |
| B | 1 | 4 |
假设内存存取粒度是1byte,取A和B都只需要取4次即可

当内存存取粒度是2byte时,A只需要取两次,分别为0和1、2和3;但是B从1开始,取2次取到了1、2和3,第4byte的数据还没取到,因此还需要取一次,总共取了3次。同时,还要把无用的第0byte和第5byte数据丢掉。

当内存存取粒度是4byte时,同样的道理,A只需要取1次4byte,B则需要取2次,并丢弃第0,第5-7byte的数据。

现在有了内存对齐的,int类型数据只能存放在按照对齐规则的内存中,比如说0地址开始的内存。那么现在该处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,提高了效率。
内存对齐
内存对齐的一个原则就是,不要让变量跨内存存取粒度存储。
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。gcc中默认#pragma pack(4),可以通过预编译命令#pragma pack(n),n = 1,2,4,8,16来改变这一系数。
有效对齐值:是给定值#pragma pack(n)和结构体中最长数据类型长度中较小的那个。有效对齐值也叫对齐单位。
了解了上面的概念后,我们现在可以来看看内存对齐需要遵循的规则:
-
结构体第一个成员的偏移量(offset)为0,以后每个成员相对于结构体首地址的 offset 都是该成员大小与有效对齐值中较小那个的整数倍,如有需要编译器会在成员之间加上填充字节。
-
结构体的总大小为 有效对齐值 的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。
我们看下面三个结构体:
#include <stdio.h>
struct x1
{
int i;
char c1;
char c2;
};
struct x2
{
char c1;
int i;
char c2;
};
struct x3
{
char c1;
char c2;
int i;
};
int main()
{
printf("%d\n", sizeof(x1));
printf("%d\n", sizeof(x2));
printf("%d\n", sizeof(x3));
return 0;
}

不考虑结构体本身对外的偏移量,我们以x1为例,i的大小是4,有效对齐值也是4,只要保证偏移量为4的整数倍就行,因此i占用0,1,2,3;c1和c2的大小都是1,有效对齐值为4,只要保证偏移量为1的整数倍即可,因此占用4和5;结构体本身需要对外对齐,必须是4的整数倍,因此将6和7填充上。其他两个结构体也是一样的分析方式。
现在我们改变有效对齐值为2,输出结果如下:

依然以x1为例,i的大小为4,有效对齐值是2,只要保证偏移量为2的整数倍就行,因此i占用0,1,2,3;c1和c2的大小都是1,有效对齐值为2,只要保证偏移量为1的整数倍即可,因此占用4和5;结构体本身需要对外对齐,必须是2的整数倍,无需填充。
其他
C++11
对齐的英文是alighment,C++11引入了一个函数alignof,可以直接获取类型T的内存对齐要求,也就是最大的成员大小与有效对齐值中较小那个。比如当有效对齐值为4时,上面3个结构体的alignof结果都是4.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据分析概述
- 大学生创业计划书,大学生创业计划书大赛,范文案列word文档PPT【免费领取】
- 笨蛋学设计模式结构型模式-装饰者模式【10】
- 【JavaWeb学习笔记】15 - jQuery
- React16源码: React中Fiber对象的源码实现
- 阿里发布通义千问!1行代码,免费对话GPT大模型
- Vue基础–列表渲染-key的原理
- Day2 多益单字纪录
- 【EI征稿】第二届移动互联网、云计算与信息安全国际会议
- 试卷上的答案怎么清除?分享3款好用的工具!