【面试突击】数据库面试实战(上)
🌈🌈🌈🌈🌈🌈🌈🌈
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到AI 前沿项目工具及新技术的推送
发送资料可领取深入理解 Redis 系列文章结合电商场景讲解 Redis 使用场景、中间件系列笔记和编程高频电子书!文章导读地址:点击查看文章导读!
感谢你的关注!
🍁🍁🍁🍁🍁🍁🍁🍁 
数据库面试实战
数据库方面也是面试中的基础知识,基本上都是必问的,其中索引、事务更是 重中之重!
存储引擎
先来说一下 MySQL 的存储引擎,有很多个,但是常见的其实就有两个:InnoDB 和 MyISAM
而 MyISAM 现在用的也非常少了,基本上都是用的 InnoDB 存储引擎,并且 InnoDB 也是 MySQL5.5 之后默认的存储引擎了
说一下两种存储引擎的区别:
主要了解一下两种存储引擎各自的优点以及适合的场景:
MyISAM 不支持事务,不支持外键约束,支持表级锁定,写操作时会导致整张表被锁住,并发性能较差,索引文件和数据文件是分开的,这样就可以在内存中缓存更多的索引,适合读操作远多于写操作的场景
InnoDB 支持事务,支持行级锁定,提供 MVCC 来处理并发事务,适用于对并发性能要求高的应用
索引
索引这块东西,只要问数据库了是必问的,InnoDB 的两种索引一定要掌握:B-tree 索引、自适应哈希索引
MySQL 中 B-tree 索引是如何实现的?
其实就是问的 B-tree 索引的数据结构,底层是 B+ 树,结构如下图(粉色区域存放索引数据,白色区域存放下一级磁盘文件地址):
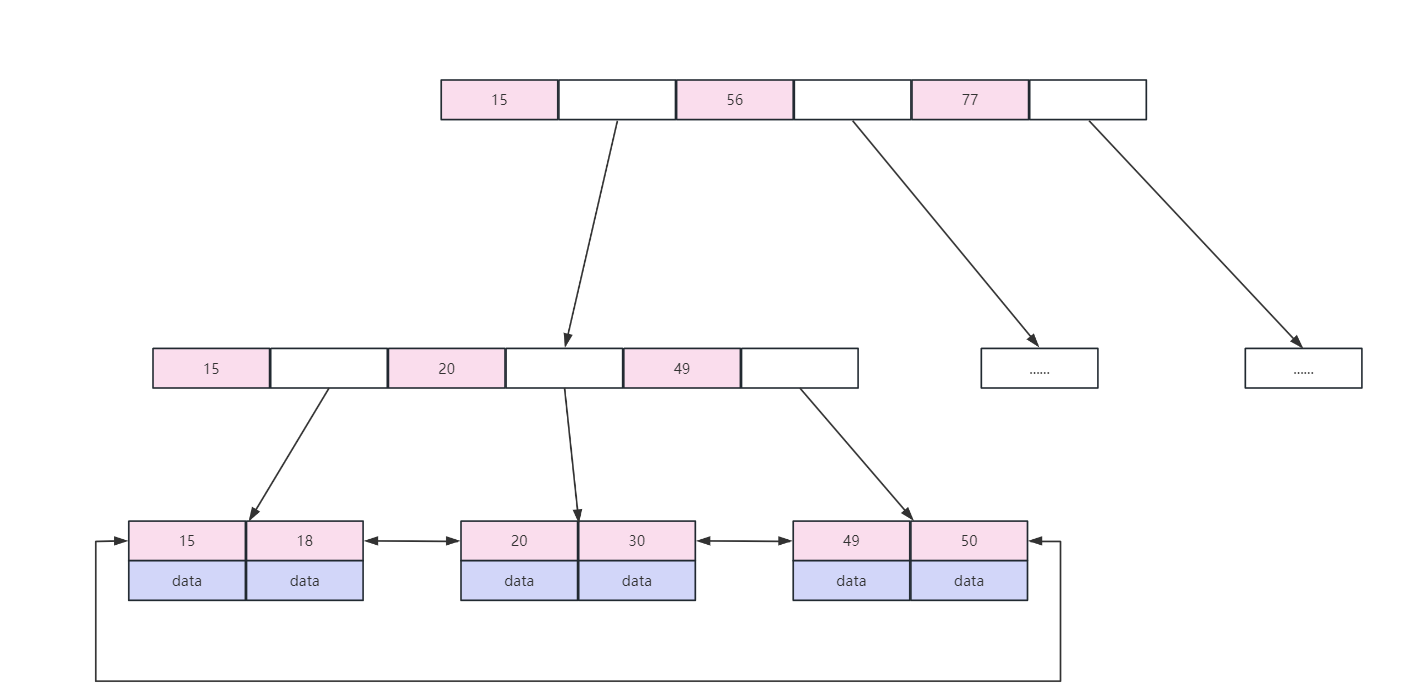
既然使用 B+ 树了,一定要知道 B+ 树的一些特点,不要面试的时候,只能说出来索引用了 B+ 树,但是也说不出来 B+ 树是什么,这是对你的面试是比较伤的
B-tree 索引(B+ 树实现)的一些特点:
- B+ 树叶子节点之间按索引数据的大小顺序建立了双向链表指针,适合按照范围查找
- 使用 B+ 树非叶子节点
只存储索引,在 B 树中,每个节点的索引和数据都在一起,因此使用 B+ 树时,通过一次磁盘 IO 拿到相同大小的存储页,B+ 树可以比 B 树拿到的索引更多,因此减少了磁盘 IO 的次数。 - B+ 树查询性能更稳定,因为数据
只保存在叶子节点,每次查询数据,磁盘 IO 的次数是稳定的
索引的数据结构了解之后,还要了解一些索引的基本知识,比如聚簇索引、非聚簇索引是什么?覆盖索引了解吗?最左前缀匹配原则了解吗?索引下推了解吗?
这些都是索引相关的 基础知识,那么初次之外,还要知道哪些情况下 索引会失效 呢?
像是索引失效这块的内容还是比较重要的,下边我也将是否使用索引的内容给整理了出来
如何判断是否使用索引?
建表 SQL
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
‐‐ 插入一些示例数据
drop procedure if exists insert_emp;
delimiter ;;
create procedure insert_emp()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into employees(name,age,position) values(CONCAT('zqy',i),i,'dev');
set i=i+1;
end while;
end;;
delimiter ;
call insert_emp()
1、联合索引第一个字段用范围不走索引
EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';
结论:type 为 ALL 表示进行了全表扫描,mysql 内部可能认为第一个字段使用范围,结果集可能会很大,如果走索引的话需要回表导致效率不高,因此直接使用全表扫描
2、强制走索引
EXPLAIN SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' AND age = 22 AND position ='manager';

结论:虽然走了索引,扫描了 50103 行,相比于上边不走索引扫描的行数少了一半,但是查找效率不一定比全表扫描高,因为回表导致效率不高。
可以使用以下代码测试:
set global query_cache_size=0;
set global query_cache_type=0;
SELECT * FROM employees WHERE name > 'LiLei' limit 1000;
> OK
> 时间: 0.408s
SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' limit 1000;
> OK
> 时间: 0.479s
SELECT * FROM employees WHERE name > 'LiLei' limit 5000;
> OK
> 时间: 0.969s
SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' limit 5000;
> OK
> 时间: 0.827s
结论:在查询 1000 条数据的话,全表扫描还是比走索引消耗时间短的,但是当查询 5000 条数据时,还是走索引效率高
3、覆盖索引优化
EXPLAIN SELECT name,age,position FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';

结论:将 select * 改为 select name, age, position,优化为使用覆盖索引,因此不需要回表,效率更高
4、in、or
in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描
EXPLAIN SELECT * FROM employees WHERE name in ('LiLei','HanMeimei','Lucy') AND age = 22 AND position='manager'; # 结果1
EXPLAIN SELECT * FROM employees WHERE (name = 'LiLei' or name = 'HanMeimei') AND age = 22 AND position='manager'; # 结果2

结论:in、or 的查询的 type 都是 range,表示使用一个索引来检索给定范围的行
给原来的 employee 表复制为一张新表 employee_copy ,里边只保留 3 条记录
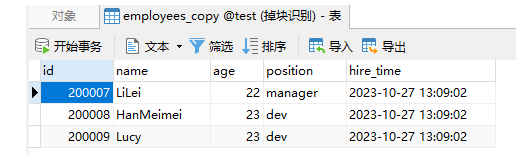
EXPLAIN SELECT * FROM employees_copy WHERE name in ('LiLei','HanMeimei','Lucy') AND age = 22 AND position ='manager';
EXPLAIN SELECT * FROM employees_copy WHERE (name = 'LiLei' or name = 'HanMeimei') AND age = 22 AND position ='manager';

结论:in、or 的查询的 type 都是 ALL,表示进行了全表扫描,没有走索引
5、like KK% 一般情况都会走索引
EXPLAIN SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager';

EXPLAIN SELECT * FROM employees_copy WHERE name like 'LiLei%' AND age = 22 AND position ='manager';

事务基础
事务中的 ACID 特性 是必须要知道:
- Atomic:原子性,一组 SQL 要么同时成功,要么同时失败
- Consistency:一致性,保证执行完 SQL 之后数据是准确的
- Isolation:隔离性,多个事务之间不会互相干扰
- Durability:持久性,事务提交之后,可以保证对数据库所作的更改是永久性的
事务的隔离级别
MySQL 的 事务隔离级别 有 4 种:
- 读未提交:事务 A 会读取到事务 B 更新但没有提交的数据。如果事务 B 回滚,事务 A 产生了脏读
- 读已提交:事务 A 会读取到事务 B 更新且提交的数据。事务 A 在事务 B 提交前后两次查询结果不同,产生不可重复读
- 可重复读:保证事务 A 中多次查询数据一致。
可重复读是 MySQL 的默认事务隔离级别。可重复读可能会造成幻读,事务A进行了多次查询,但是事务B在事务A查询过程中新增了数据,事务A虽然查询不到事务B中的数据,但是可以对事务B中的数据进行更新 - 可串行化:并发性能低,不常使用
这一部分需要了解的就是每一种隔离级别可能会带来的问题,如下这个表格所示:
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
那么肯定就要了解 脏读、不可重复读、幻读 到底是个什么东东?
脏写:多个事务更新同一行,每个事务不知道其他事务的存在,最后的更新覆盖了其他事务所做的更新脏读:事务 A 读取到了事务 B 已经修改但是没有提交的数据,此时如果事务 B 回滚,事务 A 读取的则为脏数据不可重复读:事务 A 内部相同的查询语句在不同时刻读出的结果不一致,在事务 A 的两次相同的查询期间,有其他事务修改了数据并且提交了幻读:当事务 A 感知到了事务 B 提交的新增数据
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 101基于matlab的极限学习机ELM算法进行遥感图像分类
- 链动2+1模式:合法合规的商业奇迹,引爆裂变式增长!
- 常用的gpt-4 prompt words收集6
- 高可用接入层技术演化及集群概述
- java获取视频文件的编解码器
- 基于极限学习机的变压器故障分类,基于ELM的变压器故障预测
- ATFX汇市:经过近三个月连续下跌,美元兑瑞郎创出年内新低
- python中,字符串与JSON互相转换
- Git 对项目更新的时候提示错误 repository not owned by current user
- 某电影院购票网站(JSP+java+springmvc+mysql+MyBatis)