开发属于你的数据采集器,DataScale Collector详解
本文以一个最简单的用于演示的 collector 为例,介绍如何开发 DataScale collector。在此之前,读者可以先浏览以下视频,增进对 DataScale collector(自定义采集器)功能的了解。(若关注视频号【炎凰数据】观看更多视频介绍)
?
DataScale 自定义采集器功能介绍
Collector安装包
-
目录结构
一个最简单的 collector 安装包中只需要包含下列内容:
% unzip ./example_collector-1.0.0-x86_64-linux.zip
% tree ./
./
├── exec
│ └── dummy_log_printer.sh
└── meta.json
1 directory, 2 files- 配置文件?./meta.json?
配置文件中设置了 collector 安装包的基本信息、以及 collector 的运行配置
? - ./exec/?目录下的可执行文件(executable)
Executable 是会在 dataflow 中被运行的程序,可以是编译生成的 binary 文件,也可以是由解释器执行的脚本程序。
?
?信息
DataScale 不会限制安装包中包含其他文件或者目录结构,所以可以将运行 collector 所需要的任何依赖放入安装包,如可执行文件所依赖的 lib 文件、配置文件等。
?
-
命名规范
由于 DataScale 支持在多种 CPU 架构和操作系统中运行,同一个 collector 也可能存在多个版本的安装包。因此,collector 安装包文件名中需要体现版本信息,安装包的命名规范为:
<COLLECTOR_NAME>-<VERSION>-<ARCH>-<OS>.zip
例如:
-
example_collector-1.0.0-x86_64-darwin.zip
-
snmp-1.0.1-arm64-linux.zip
-
windows_event_log-1.0.0-x86_64-windows.zip
? -
Collector 配置文件
Collector 配置文件的为安装包根目录下的?./meta.json?文件,其格式为:
{
"info": {
"version": "1.0.0",
"name": "Example Collector",
"description": "Example collector is a DataScale collector for demo or learning purpose."
},
"executables": [
{
"type": "sh",
"exec": "dummy_log_printer.sh",
"args": "",
"env": {},
"transforms": []
}
],
"env": {},
"transforms": []
}- ?info
-
Collector 的基本信息
- executables
Collector 中 executable 的配置。如果 collector 中存在多个 executable 时,可以在创建 collector source 组件时,选择使用其中的一个 executable。
o?type
Executable 的运行方式。如果该 executable 可以在目标主机上直接运行,type?值可以为空,否则需要提供 executable 的运行方式,如?sh?或者?python?等。
o exec
Executable?的名字,对应安装包?./exec/?目录下的的可执行文件名。
o args
运行该 executable 时默认使用的命令行参数,可以在 collector source 组件的配置中被修改。
o env
运行该 executable 时需要设置的环境变量的键值对,可以在 collector source 组件的配置中被修改。
o transforms
应用在该 executable 采集到的 event 的 transform 逻辑。
? - env
运行 collector 中的任何 executable 时,都需要设置的环境变量,会在运行 executable 时与 executable 中配置的?env?合并(优先级低于 executable 中的配置)。
? - transforms
? -
应用在 collector 中的任何 executable 采集到的 event 的 transform 逻辑,会与 executable 中配置的?transform?合并(执行顺序排在 executable 中的配置之后)。
? -
开发 Collector Executable 程序
Collector 的 executable 是一个可以独立运行的可执行文件或脚本,执行数据采集的逻辑,并输出采集到的 event。
例如,这样一个最简单的输出一行日志文本的 Shell 脚本就可以作为 collector 的 executable:
#!/bin/sh
echo `date +%Y-%m-%dT%H:%M:%S%z` This is dummy log from dummy_log_printer.sh as a DataScale collector????
-
STDOUT/STDERR 输出
Executable 程序输出到 STDOUT 的内容会作为采集到的 event 输出到 dataflow 中后续的 pipeline 和 sink 组件,每一行内容做为一条 event。输出到 STDERR 的内容则作为错误日志,用于表现 executable 的执行处于非健康状态(该状态会体现在 dataflow 的运行状态中)。
?信息
不论 executable 程序的 exit code 是何值,都不会体现在 dataflow 的运行状态中。
-
运行参数和环境变量
如果需要能够从外部控制 executable 程序的运行逻辑,可以使 executable 程序支持一些命令行参数或者环境变量的配置。Collector 的配置文件和 collector source 组件的配置表单中都可以为 executable 设置运行时的命令行参数和环境变量。
-
运行模式
Collector source 组件可以被配置为周期性执行的模式(scheduled 模式),或者持续运行的模式(streaming 模式)。
选择何种运行模式取决于 executable 程序的运行方式:
-
在 scheduled 模式下运行的 executable 程序每次启动后都应该能够在预期的时间内完成 event 的采集和输出。
-
在 streaming 模式下运行的 executable 程序一但启动后,应该能够持续运行,持续产生 event,直至被要求停止运行。
?信息
如果 collector source 组件配置的运行模式和 executable 程序的运行方式不相匹配,DataScale 在执行 collector executable 时会认为出现了程序运行超时,或者程序异常退出等不符合预期的行为。
-
在 Dataflow 中使用 Collector
安装 collector 后,可以在 dataflow 中使用该 collector 作为 source 组件:
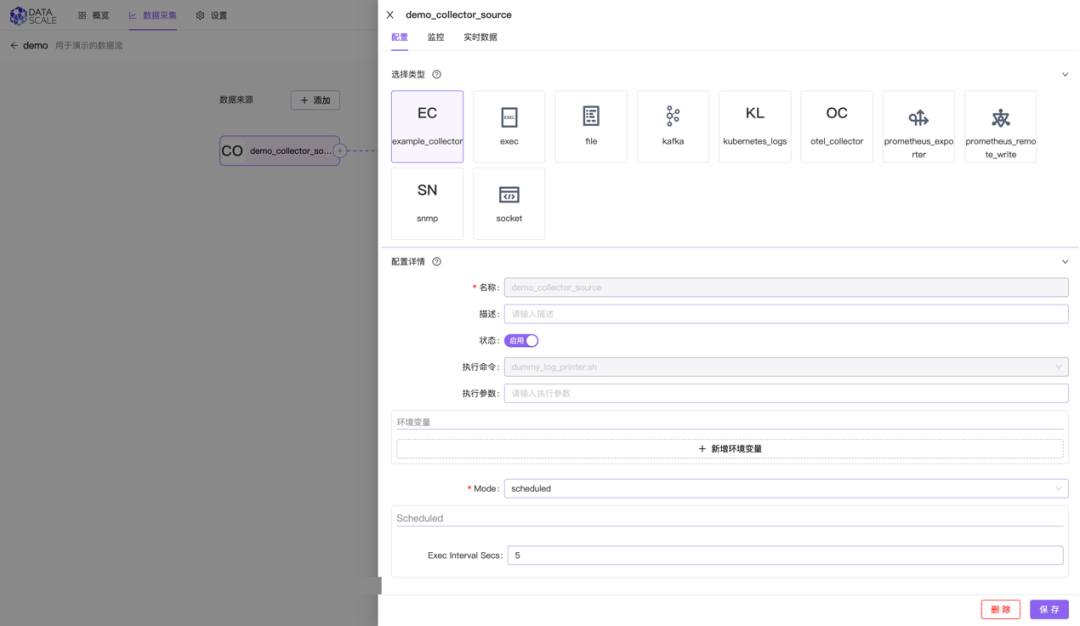
Collector source?组件可以和其他内置?source?组件一样,连接后续的?pipeline?和?source?组件:
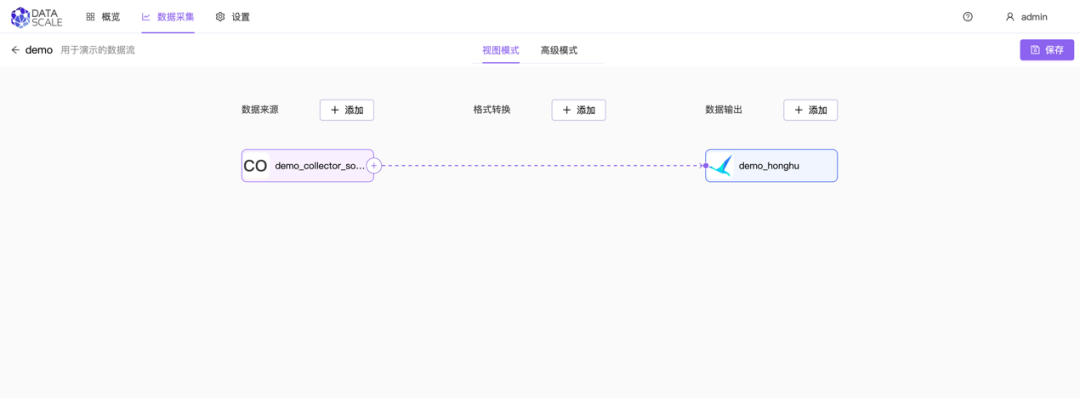
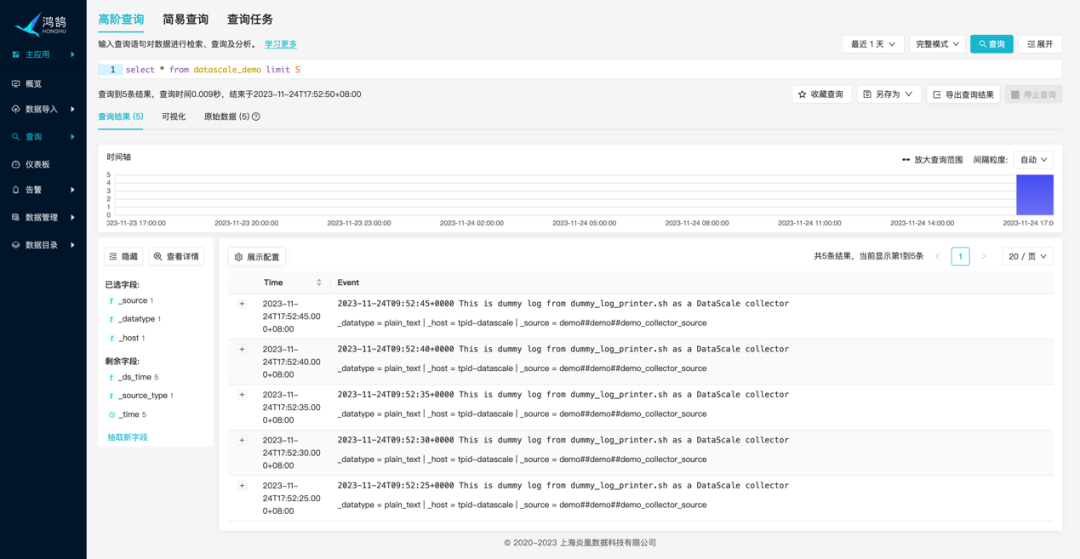
Dataflow 开始运行后,就可以在炎凰数据平台中查询到 collector 采集到的 events:
调试 Collector Executable 程序
-
本地调试
Collector 的 executable 可以独立运行,因此就可以在本地开发环境下使用必要的命令行参数和环境变量直接运行、调试可执行程序,并观察 STDOUT 和 STDERR 的输出是否符合预期。
-
在 Dataflow 中调试
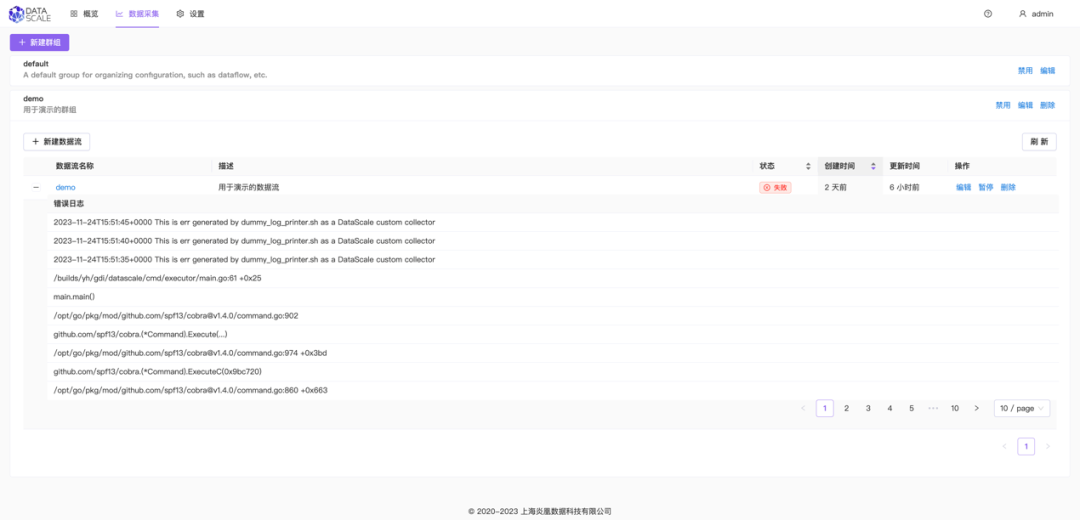
在 dataflow 中使用 collector source 组件时,executable 程序输出到 STDERR 的错误日志会被保存在日志文件中, 日志文件位于 DataScale 安装路径下的?./run/collector/<COLLECTOR_NAME>/<EXECUTABLE_NAME>/logs/?目录中。
或者也可以通过 Web UI 上查看 collector source 组件的错误日志:
为了帮助更多用户轻松开发出属于自己的数据采集利器,更好地服务于数据分析处理需求,炎凰数据特为广大开发者举办了第一届黑客马拉松比赛,主题为“大数至简,采集为先——开发自己的数据采集利器”,参赛者报名成功之后,可以基于DataScale的自定义功能开发自己的数据采集功能。
为了奖励好的参赛项目,前三名优胜者将获得惊喜大奖:
一等奖(1名):奖品iphone15 pro Max 512GB
二等奖(1名):奖品 ipad Air5 WLAN版 256G
三等奖(1名):奖品apple watch Series 8 蜂窝款
欢迎有兴趣的开发者伙伴至官网联系社区小助手报名:官网
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 嵌入式自学好书推荐
- 演员-评论家算法:多智能体强化学习核心框架
- 搜索引擎如何(以及为什么)呈现页面
- 独立站如何借助内容营销实现品牌提升与用户增长?
- Wav2Lip视频人脸口型同步(Win10)
- 深耕细作,持续发展|企业级快速开发平台助力实现流程化办公!
- 如何开发员工管理软件app系统?
- 【Python学习】Python学习10-列表
- 2.机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解
- dp_day1