Rust 错误处理(下)
目录
1、用 Result 处理可恢复的错误
1.1?传播错误的简写:? 运算符
先看下如下示例:
fn main() {
fn read_file() -> Result<String, io::Error> {
let file_result = File::open("hello.txt");
let mut v = String::new();
file_result.unwrap().read_to_string(&mut v)?;
Ok(v)
}
let res = read_file();
print!("{:?}", res)
}Result?值之后的???被定义为之前的处理?Result?值的?match?表达式有着完全相同的工作方式。如果?Result?的值是?Ok,这个表达式将会返回?Ok?中的值而程序将继续执行。如果值是?Err,Err?将作为整个函数的返回值,就好像使用了?return?关键字一样,这样错误值就被传播给了调用者。
之前示例的?match?表达式与???运算符所做的有一点不同:??运算符所使用的错误值被传递给了?from?函数,它定义于标准库的?From?trait 中,其用来将错误从一种类型转换为另一种类型。当???运算符调用?from?函数时,收到的错误类型被转换为由当前函数返回类型所指定的错误类型。这在当函数返回单个错误类型来代表所有可能失败的方式时很有用,即使其可能会因很多种原因失败。
??运算符消除了大量样板代码并使得函数的实现更简单。我们甚至可以在???之后直接使用链式方法调用来进一步缩短代码,如下所示:
fn main() {
fn read_file() -> Result<String, io::Error> {
let mut v = String::new();
let _ = File::open("hello.txt")?.read_to_string(&mut v)?;
Ok(v)
}
let res = read_file();
print!("{:?}", res)
}以下代码展示了一个使用?fs::read_to_string?的更为简短的写法:
fn main() {
fn read_file() -> Result<String, io::Error> {
fs::read_to_string("hello1.txt")
}
let res = read_file();
print!("{:?}", res)
}将文件读取到一个字符串是相当常见的操作,所以 Rust 提供了名为?fs::read_to_string?的函数,它会打开文件、新建一个?String、读取文件的内容,并将内容放入?String,接着返回它。当然,这样做就没有展示所有这些错误处理的机会了.
1.2 哪里可以使用 ? 运算符
??运算符只能被用于返回值与???作用的值相兼容的函数。因为???运算符被定义为从函数中提早返回一个值,这与之前示例的?match?表达式有着完全相同的工作方式。示例中?match?作用于一个?Result?值,提早返回的分支返回了一个?Err(e)?值。函数的返回值必须是?Result?才能与这个?return?相兼容。
让我们看看在返回值不兼容的?main?函数中使用???运算符会得到什么错误:
fn main() {
fs::read_to_string("hello1.txt")?;
}这段代码打开一个文件,这可能会失败。??运算符作用于?File::open?返回的?Result?值,不过?main?函数的返回类型是?()?而不是?Result。当编译这些代码,会得到如下错误信息:?
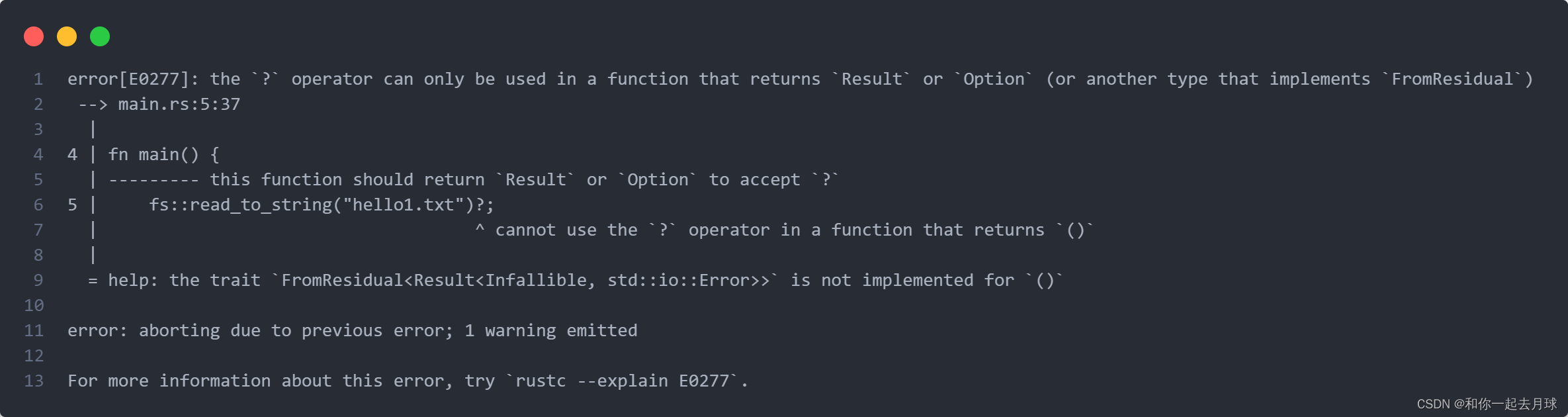
这个错误指出只能在返回?Result?或者其它实现了?FromResidual?的类型的函数中使用???运算符。
为了修复这个错误,有两个选择。一个是,如果没有限制的话将函数的返回值改为?Result<T, E>。另一个是使用?match?或?Result<T, E>?的方法中合适的一个来处理?Result<T, E>。
错误信息也提到???也可用于?Option<T>?值。如同对?Result?使用???一样,只能在返回?Option?的函数中对?Option?使用??。在?Option<T>?上调用???运算符的行为与?Result<T, E>?类似:如果值是?None,此时?None?会从函数中提前返回。如果值是?Some,Some?中的值作为表达式的返回值同时函数继续。
文本中返回第一行最后一个字符的函数的例子:
fn last_char_of_first_line(text: &str) -> Option<char> {
text.lines().next()?.chars().last()
}这个函数返回?Option<char>?因为它可能会在这个位置找到一个字符,也可能没有字符。这段代码获取?text?字符串 slice 作为参数并调用其?lines?方法,这会返回一个字符串中每一行的迭代器。因为函数希望检查第一行,所以调用了迭代器?next?来获取迭代器中第一个值。如果?text?是空字符串,next?调用会返回?None,此时我们可以使用???来停止并从?last_char_of_first_line?返回?None。如果?text?不是空字符串,next?会返回一个包含?text?中第一行的字符串 slice 的?Some?值。
??会提取这个字符串 slice,然后可以在字符串 slice 上调用?chars?来获取字符的迭代器。我们感兴趣的是第一行的最后一个字符,所以可以调用?last?来返回迭代器的最后一项。这是一个?Option,因为有可能第一行是一个空字符串,例如?text?以一个空行开头而后面的行有文本,像是?"\nhi"。不过,如果第一行有最后一个字符,它会返回在一个?Some?成员中。??运算符作用于其中给了我们一个简洁的表达这种逻辑的方式。如果我们不能在?Option?上使用???运算符,则不得不使用更多的方法调用或者?match?表达式来实现这些逻辑。
注意你可以在返回?Result?的函数中对?Result?使用???运算符,可以在返回?Option?的函数中对?Option?使用???运算符,但是不可以混合搭配。??运算符不会自动将?Result?转化为?Option,反之亦然;在这些情况下,可以使用类似?Result?的?ok?方法或者?Option?的?ok_or?方法来显式转换。
目前为止,我们所使用的所有?main?函数都返回?()。main?函数是特殊的因为它是可执行程序的入口点和退出点,为了使程序能正常工作,其可以返回的类型是有限制的。
幸运的是?main?函数也可以返回?Result<(), E>,以下示例?main?的返回值为?Result<(), Box<dyn Error>>?并在结尾增加了一个?Ok(())?作为返回值。这段代码可以编译:
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello1.txt")?;
Ok(())
}Box<dyn Error>?类型是一个?trait 对象(trait object)
目前可以将?Box<dyn Error>?理解为 “任何类型的错误”。在返回?Box<dyn Error>?错误类型?main?函数中对?Result?使用???是允许的,因为它允许任何?Err?值提前返回。即便?main?函数体从来只会返回?std::io::Error?错误类型,通过指定?Box<dyn Error>,这个签名也仍是正确的,甚至当?main?函数体中增加更多返回其他错误类型的代码时也是如此。
当?main?函数返回?Result<(), E>,如果?main?返回?Ok(())?可执行程序会以?0?值退出,而如果?main?返回?Err?值则会以非零值退出;成功退出的程序会返回整数?0,运行错误的程序会返回非?0?的整数。Rust 也会从二进制程序中返回与这个惯例相兼容的整数。
main?函数也可以返回任何实现了?std::process::Termination?trait?的类型,它包含了一个返回?ExitCode?的?report?函数。
2、要不要 panic!
那么,该如何决定何时应该?panic!?以及何时应该返回?Result?呢?如果代码 panic,就没有恢复的可能。你可以选择对任何错误场景都调用?panic!,不管是否有可能恢复,不过这样就是你代替调用者决定了这是不可恢复的。选择返回?Result?值的话,就将选择权交给了调用者,而不是代替他们做出决定。调用者可能会选择以符合他们场景的方式尝试恢复,或者也可能干脆就认为?Err?是不可恢复的,所以他们也可能会调用?panic!?并将可恢复的错误变成了不可恢复的错误。因此返回?Result?是定义可能会失败的函数的一个好的默认选择。
在一些类似示例、原型代码(prototype code)和测试中,panic 比返回?Result?更为合适,不过它们并不常见。让我们讨论一下为何在示例、代码原型和测试中,以及那些人们认为不会失败而编译器不这么看的情况下,panic 是合适的。
2.1?示例、代码原型和测试都非常适合 panic
当你编写一个示例来展示一些概念时,在拥有健壮的错误处理代码的同时也会使得例子不那么明确。例如,调用一个类似?unwrap?这样可能?panic!?的方法可以被理解为一个你实际希望程序处理错误方式的占位符,它根据其余代码运行方式可能会各不相同。
类似地,在我们准备好决定如何处理错误之前,unwrap和expect方法在原型设计时非常方便。当我们准备好让程序更加健壮时,它们会在代码中留下清晰的标记。
如果方法调用在测试中失败了,我们希望这个测试都失败,即便这个方法并不是需要测试的功能。因为?panic!?会将测试标记为失败,此时调用?unwrap?或?expect?是恰当的。
2.2?当我们比编译器知道更多的情况
当你有一些其他的逻辑来确保?Result?会是?Ok?值时,调用?unwrap?或者?expect?也是合适的,虽然编译器无法理解这种逻辑。你仍然需要处理一个?Result?值:即使在你的特定情况下逻辑上是不可能的,你所调用的任何操作仍然有可能失败。如果通过人工检查代码来确保永远也不会出现?Err?值,那么调用?unwrap?也是完全可以接受的,这里是一个例子:
fn main() {
let home: IpAddr = "127.0.0.1111".parse().expect("IP address error......");
panic!("{:?}", home)
}我们通过解析一个硬编码的字符来创建一个?IpAddr?实例。可以看出?127.0.0.1?是一个有效的 IP 地址,所以这里使用?expect?是可以接受的。然而,拥有一个硬编码的有效的字符串也不能改变?parse?方法的返回值类型:它仍然是一个?Result?值,而编译器仍然会要求我们处理这个?Result,好像还是有可能出现?Err?成员那样。这是因为编译器还没有智能到可以识别出这个字符串总是一个有效的 IP 地址。如果 IP 地址字符串来源于用户而不是硬编码进程序中的话,那么就?确实?有失败的可能性,这时就绝对需要我们以一种更健壮的方式处理?Result?了。提及这个 IP 地址是硬编码的假设会促使我们将来把?expect?替换为更好的错误处理,我们应该从其它代码获取 IP 地址。
2.3?错误处理指导原则
在当有可能会导致有害状态的情况下建议使用?panic!?—— 在这里,有害状态是指当一些假设、保证、协议或不可变性被打破的状态,例如无效的值、自相矛盾的值或者被传递了不存在的值 —— 外加如下几种情况:
- 有害状态是非预期的行为,与偶尔会发生的行为相对,比如用户输入了错误格式的数据。
- 在此之后代码的运行依赖于不处于这种有害状态,而不是在每一步都检查是否有问题。
- 没有可行的手段来将有害状态信息编码进所使用的类型中的情况。
如果别人调用你的代码并传递了一个没有意义的值,尽最大可能返回一个错误,如此库的用户就可以决定在这种情况下该如何处理。然而在继续执行代码是不安全或有害的情况下,最好的选择可能是调用?panic!?并警告库的用户他们的代码中有 bug,这样他们就会在开发时进行修复。类似的,如果你正在调用不受你控制的外部代码,并且它返回了一个你无法修复的无效状态,那么?panic!?往往是合适的。
然而当错误预期会出现时,返回?Result?仍要比调用?panic!?更为合适。这样的例子包括解析器接收到格式错误的数据,或者 HTTP 请求返回了一个表明触发了限流的状态。在这些例子中,应该通过返回?Result?来表明失败预期是可能的,这样将有害状态向上传播,调用者就可以决定该如何处理这个问题。使用?panic!?来处理这些情况就不是最好的选择。
当你的代码在进行一个使用无效值进行调用时可能将用户置于风险中的操作时,代码应该首先验证值是有效的,并在其无效时?panic!。这主要是出于安全的原因:尝试操作无效数据会暴露代码漏洞,这就是标准库在尝试越界访问数组时会?panic!?的主要原因:尝试访问不属于当前数据结构的内存是一个常见的安全隐患。函数通常都遵循?契约(contracts):它们的行为只有在输入满足特定条件时才能得到保证。当违反契约时 panic 是有道理的,因为这通常代表调用方的 bug,而且这也不是那种你希望所调用的代码必须处理的错误。事实上所调用的代码也没有合理的方式来恢复,而是需要调用方的?程序员?修复其代码。函数的契约,尤其是当违反它会造成 panic 的契约,应该在函数的 API 文档中得到解释。
虽然在所有函数中都拥有许多错误检查是冗长而烦人的。幸运的是,可以利用 Rust 的类型系统(以及编译器的类型检查)为你进行很多检查。如果函数有一个特定类型的参数,可以在知晓编译器已经确保其拥有一个有效值的前提下进行你的代码逻辑。例如,如果你使用了一个并不是?Option?的类型,则程序期望它是?有值?的并且不是?空值。你的代码无需处理?Some?和?None?这两种情况,它只会有一种情况就是绝对会有一个值。尝试向函数传递空值的代码甚至根本不能编译,所以你的函数在运行时没有必要判空。另外一个例子是使用像?u32?这样的无符号整型,也会确保它永远不为负。
2.4?创建自定义类型进行有效性验证
让我们使用 Rust 类型系统的思想来进一步确保值的有效性,并尝试创建一个自定义类型以进行验证。回忆一下第二章的猜猜看游戏,我们的代码要求用户猜测一个 1 到 100 之间的数字,在将其与秘密数字做比较之前我们从未验证用户的猜测是位于这两个数字之间的,我们只验证它是否为正。在这种情况下,其影响并不是很严重:“Too high” 或 “Too low” 的输出仍然是正确的。但是这是一个很好的引导用户得出有效猜测的辅助,例如当用户猜测一个超出范围的数字或者输入字母时采取不同的行为。
一种实现方式是将猜测解析成?i32?而不仅仅是?u32,来默许输入负数,接着检查数字是否在范围内:
loop {
// --snip--
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
}2.5 总结
Rust 的错误处理功能被设计为帮助你编写更加健壮的代码。panic!?宏代表一个程序无法处理的状态,并停止执行而不是使用无效或不正确的值继续处理。Rust 类型系统的?Result?枚举代表操作可能会在一种可以恢复的情况下失败。可以使用?Result?来告诉代码调用者他需要处理潜在的成功或失败。在适当的场景使用?panic!?和?Result?将会使你的代码在面对不可避免的错误时显得更加可靠。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SQL Server 备份和还原
- openssl3.2 - 官方demo学习 - digest - EVP_MD_demo.c
- 第十一章 Cookie
- 16、Citrix云桌面通过SQL Server查询用户登录记录
- (3)linux:man手册,复制,移动重命名
- 机器人行业数据闭环实践:从对象存储到 JuiceFS
- vue3+ts报错:无法找到模块“xxx.vue“的声明文件,xxx隐式拥有“any“类型
- 3D模型gltf下载网站(threejs开发)
- 媒体跟踪软件Ryot
- JVM基础(3)——JVM垃圾回收机制