【HuggingFace Transformer库学习笔记】基础组件学习:Evaluate
发布时间:2024年01月13日
基础组件学习——Evaluate


Evaluate使用指南
查看支持的评估函数
# include_community:是否添加社区实现的部分
# with_details:是否展示更多细节
evaluate.list_evaluation_modules(include_community=False, with_details=True)
加载评估函数
accuracy = evaluate.load("accuracy")
查看评估函数说明
print(accuracy.description)
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
查看示例说明
print(accuracy.inputs_description)
Args:
predictions (`list` of `int`): Predicted labels.
references (`list` of `int`): Ground truth labels.
normalize (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.
sample_weight (`list` of `float`): Sample weights Defaults to None.
Returns:
accuracy (`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.
Examples:
Example 1-A simple example
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
>>> print(results)
{'accuracy': 0.5}
Example 2-The same as Example 1, except with `normalize` set to `False`.
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)
>>> print(results)
{'accuracy': 3.0}
Example 3-The same as Example 1, except with `sample_weight` set.
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])
>>> print(results)
{'accuracy': 0.8778625954198473}
accuracy
EvaluationModule(name: "accuracy", module_type: "metric", features: {'predictions': Value(dtype='int32', id=None), 'references': Value(dtype='int32', id=None)}, usage: """
Args:
predictions (`list` of `int`): Predicted labels.
references (`list` of `int`): Ground truth labels.
normalize (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.
sample_weight (`list` of `float`): Sample weights Defaults to None.
Returns:
accuracy (`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.
Examples:
Example 1-A simple example
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
>>> print(results)
{'accuracy': 0.5}
Example 2-The same as Example 1, except with `normalize` set to `False`.
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)
>>> print(results)
{'accuracy': 3.0}
Example 3-The same as Example 1, except with `sample_weight` set.
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])
>>> print(results)
{'accuracy': 0.8778625954198473}
""", stored examples: 0)
评估指标计算——全局计算
accuracy = evaluate.load("accuracy")
results = accuracy.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
results
{'accuracy': 0.5}
评估指标计算——迭代计算
# 一个一个传
accuracy = evaluate.load("accuracy")
for ref, pred in zip([0,1,0,1], [1,0,0,1]):
accuracy.add(references=ref, predictions=pred)
accuracy.compute()
{'accuracy': 0.5}
# 一批一批传
accuracy = evaluate.load("accuracy")
for refs, preds in zip([[0,1],[0,1]], [[1,0],[0,1]]):
accuracy.add_batch(references=refs, predictions=preds)
accuracy.compute()
{'accuracy': 0.5}
多个评估指标计算
clf_metrics = evaluate.combine(["accuracy", "f1", "recall", "precision"])
clf_metrics
<evaluate.module.CombinedEvaluations at 0x1e92e72f880>
clf_metrics.compute(predictions=[0, 1, 0], references=[0, 1, 1])
{'accuracy': 0.6666666666666666,
'f1': 0.6666666666666666,
'recall': 0.5,
'precision': 1.0}
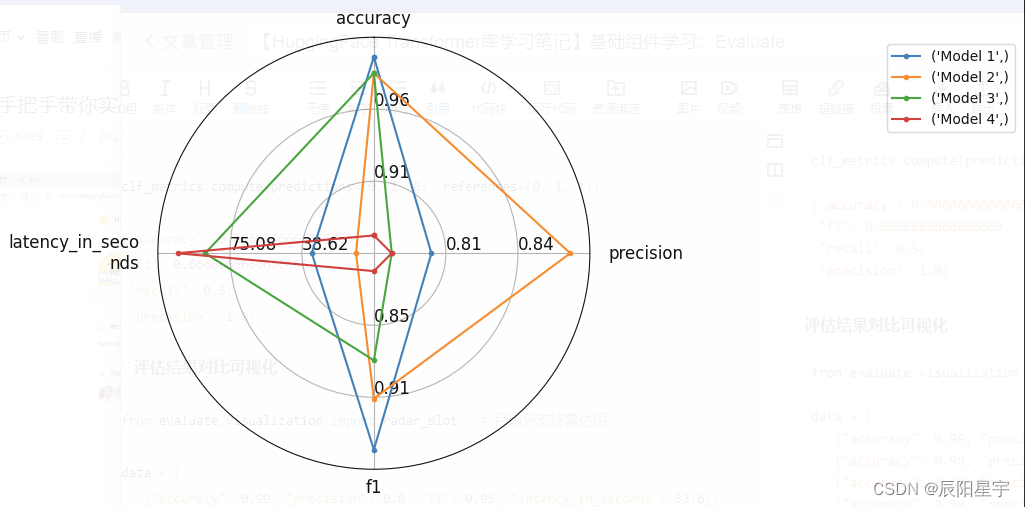
评估结果对比可视化
from evaluate.visualization import radar_plot # 目前只支持雷达图
data = [
{"accuracy": 0.99, "precision": 0.8, "f1": 0.95, "latency_in_seconds": 33.6},
{"accuracy": 0.98, "precision": 0.87, "f1": 0.91, "latency_in_seconds": 11.2},
{"accuracy": 0.98, "precision": 0.78, "f1": 0.88, "latency_in_seconds": 87.6},
{"accuracy": 0.88, "precision": 0.78, "f1": 0.81, "latency_in_seconds": 101.6}
]
model_names = ["Model 1", "Model 2", "Model 3", "Model 4"]
plot = radar_plot(data=data, model_names=model_names)
文章来源:https://blog.csdn.net/qq_41094332/article/details/135573073
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++日期类的实现
- MES管理系统解决方案如何处理汽配企业的难题
- Python 模块的使用
- vue3+Vite+Js项目搭建之:.env、.env.development、.env.production 环境变量配置
- 深度学习网站集锦1
- 【教3妹学编程-算法题】美丽塔 II
- hbuilder能不能开发鸿蒙app
- VMware虚拟机安装Linux教程
- RESTful API
- 如何在 ASP.NET Core 配置请求超时中间件