04-了解所有权
上一篇:?03-常用编程概念
????????所有权是 Rust 最独特的特性,对语言的其他部分有着深刻的影响。它使 Rust 可以在不需要垃圾回收器的情况下保证内存安全,因此了解所有权的工作原理非常重要。在本章中,我们将讨论所有权以及几个相关特性:借用、分片以及 Rust 如何在内存中布局数据。
1. 什么是所有权
????????所有权是一套管理 Rust 程序如何管理内存的规则。所有程序在运行时都必须管理它们使用计算机内存的方式。有些语言有垃圾回收功能,可以在程序运行时定期查找不再使用的内存(Java的垃圾回收机制);在其他语言中,程序员必须明确分配和释放内存(C/C++)。Rust 使用的是第三种方法:通过所有权系统管理内存,并由编译器检查一系列规则。如果违反任何规则,程序将无法编译。在程序运行过程中,所有权的所有特性都不会降低程序的运行速度。
????????由于所有权对许多程序员来说是一个新概念,因此需要一些时间来适应。好在你对 Rust 和所有权系统的规则越有经验,就越容易自然而然地开发出安全高效的代码。
????????当你理解了所有权,就为理解 Rust 独特的功能打下了坚实的基础。在本章中,你将通过一些示例来学习所有权,这些示例的重点是一种非常常见的数据结构:字符串。
栈和堆
????????许多编程语言并不要求你经常考虑栈和堆。但在 Rust 这样的系统编程语言中,一个值是在栈上还是在堆上会影响语言的行为方式,以及你必须做出某些决定的原因。本章稍后将介绍与堆栈和堆相关的所有权部分,因此在此先做简要说明。
????????栈和堆都是内存的一部分,供代码在运行时使用,但它们的结构不同。栈按照获取值的顺序存储值,并按照相反的顺序删除值。这就是所谓的后进先出。想想一摞盘子:当你添加更多盘子时,就把它们放到堆的顶端;当你需要一个盘子时,就从顶端取下一个。从中间或底部添加或移除盘子的效果并不好!添加数据被称为 "入栈",删除数据被称为 "弹栈"。栈中存储的所有数据必须有已知的固定大小。编译时大小未知或大小可能改变的数据必须存储在堆上。
????????堆的组织性较差:在堆上放置数据时,需要一定的空间。内存分配器会在堆中找到足够大的空位,将其标记为正在使用,并返回一个指针,即该位置的地址。这个过程称为在堆上分配,有时也简称为分配(入栈不属于分配)。由于堆的指针是已知的固定大小,因此可以将指针存储在堆栈中,但当需要实际数据时,必须按照指针进行操作。想象一下在餐厅就餐的情景。当你进入餐厅时,你要说明你所在小组的人数,然后主人会找到一张适合每个人的空桌,并把你领到那里。如果你的团队中有人来晚了,他们可以询问你的座位在哪里,然后找到你。
????????向栈推送比在堆上分配更快,因为分配器无需寻找存储新数据的位置,该位置始终位于栈的顶部。相比之下,在堆上分配空间需要更多的工作,因为分配器必须首先找到一个足够大的空间来存放数据,然后进行簿记,为下一次分配做好准备。
????????访问堆中的数据比访问栈上的数据要慢,因为你必须跟随指针才能到达那里。如果减少在内存中的跳转,现代处理器的速度就会更快。继续类比,考虑一下餐厅的服务员从很多桌点菜的情况。最有效的方法是先处理一张桌子上的所有订单,然后再处理下一张桌子上的订单。从 A 桌点菜,然后从 B 桌点菜,然后再从 A 桌点菜,然后再从 B 桌点菜,这个过程会慢得多。同样,如果处理器处理的数据与其他数据距离较近(如栈中的数据),而不是较远(如堆中的数据),那么处理器就能更好地完成工作。
????????当你的代码调用一个函数时,传入函数的值(可能包括指向堆上数据的指针)和函数的局部变量会被推入栈中。函数结束后,这些值会从栈中弹出。
????????跟踪代码的哪些部分在使用堆上的哪些数据,尽量减少堆上重复数据的数量,清理堆上未使用的数据以避免空间耗尽,这些都是所有权要解决的问题。一旦理解了所有权,你就不需要经常考虑栈和堆了,但知道所有权的主要目的是管理堆数据,有助于解释为什么它以这种方式工作。
1.1?所有权规则
????????首先,让我们来看看所有权规则。在我们举例说明时,请牢记这些规则:
? ? ? ? ①.?Rust 中的每个值都有一个所有者。
????????②.?一次只能有一个所有者。
????????③.?当所有者超出范围时,该值将被删除。
1.2?变量作用域
????????既然我们已经掌握了基本的 Rust 语法,我们就不会在示例中包含所有的 fn main() { 代码,所以如果你正在学习,请务必手动将下面的示例放在 main 函数中。因此,我们的示例将更加简洁,让我们专注于实际细节而不是模板代码。
????????作为所有权的第一个例子,我们来看看一些变量的作用域。作用域是指一个item在程序中有效的范围。以下面的变量为例:
let s = "hello";
????????变量 s 指的是一个字符串字面量,字符串的值被硬编码到我们程序的文本中。该变量的有效期从声明时开始,直到当前作用域结束。正面显示了一个带有注释的程序,注释中说明了变量 s 的有效位置。
{ // s is not valid here, it’s not yet declared
let s = "hello"; // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no longer valid
????????换句话说,这里有两个重要的时间点:
? ? ? ? ? ? ? ? ①. s 开始生效。
????????????????②.?它在超出范围之前一直有效。
????????至此,作用域与变量有效时间之间的关系与其他编程语言类似。现在,我们将在此基础上介绍 String 类型。
1.3 String类型
???????前面介绍的类型大小已知,可以存储在栈中,并在其作用域结束时从栈中弹出,如果代码的另一部分需要在不同的作用域中使用相同的值,则可以快速、简便地复制以创建一个新的、独立的实例。但我们想看看堆上存储的数据,并探索 Rust 如何知道何时清理这些数据, String 类型就是一个很好的例子。
????????我们将集中讨论 String 中与所有权相关的部分。这些内容也适用于其他复杂数据类型,无论它们是由标准库提供的还是由您创建的。我们将在后面章节更深入地讨论 String 。
????????我们已经见过字符串字面量,即在程序中硬编码一个字符串值。字符串字面量很方便,但并不适合我们想要使用文本的所有情况。其中一个原因是它们是不可变的。另一个原因是,在我们编写代码时,并不是每个字符串值都是已知的:例如,如果我们想获取用户输入并将其存储起来,该怎么办?针对这些情况,Rust 提供了第二种字符串类型 String 。该类型管理堆上分配的数据,因此可以存储编译时未知的文本。您可以使用 from 函数从字符串字面量创建一个 String ,如下所示:
let s = String::from("hello");
????????双冒号 :: 操作符允许我们在 String 类型下使用命名为from 函数,而不是使用某种名称,如 string_from 。
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() appends a literal to a String
println!("{}", s); // This will print `hello, world!`
????????那么,这里有什么区别呢?为什么 String 可以更改内容,而字面量不能更改内容?区别在于这两种类型如何处理内存。
1.4?内存和分配
????????对于字符串字面量,我们在编译时就知道其内容,因此文本会直接硬编码到最终的可执行文件中。这就是字符串字面量快速高效的原因。但这些特性仅仅来自于字符串字面量的不变性。遗憾的是,我们无法在二进制文件中为每一段文本添加一块内存,因为这些文本在编译时大小未知,而且在程序运行时大小可能会发生变化。
????????对于 String 类型,为了支持一个可变、可增长的文本片段,我们需要在堆上分配一定量的内存来存放内容,这在编译时是未知的。这意味着:
????????①.?必须在运行时向内存分配器申请内存。
????????②.?当我们完成 String 时,我们需要一种将内存返回分配器的方法。
????????第一部分是由我们完成的:当我们调用 String::from 时,其实现会请求所需的内存。这在编程语言中几乎是通用的。
????????不过,第二部分有所不同。在有垃圾回收器(GC)的语言中,GC 会跟踪并清理不再使用的内存,我们不需要考虑这个问题。在大多数没有 GC 的语言中,我们有责任识别内存何时不再被使用,并调用代码显式释放内存,就像我们请求内存一样。正确做到这一点历来是编程中的难题。如果我们忘记了,就会浪费内存。如果过早释放,就会产生无效变量。如果我们做了两次,那也是一个错误。我们需要将一个 allocate 与一个 free 配对。
????????Rust 采用了不同的方法:一旦拥有内存的变量退出作用域,内存就会自动返回。下面示例使用的是 String 而不是字符串字面量:
{
let s = String::from("hello"); // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no
// longer valid
????????有一个自然的时间点,我们可以将 String 所需的内存归还给分配器:当 s 变量退出作用域时。当变量退出作用域时,Rust 会为我们调用一个特殊函数。这个函数被称为 drop , String 的作者可以在这个函数中写入返回内存的代码。Rust 会在结尾大括号处自动调用 drop 。
????????注:在 C++ 中,这种在项目生命周期结束时去分配资源的模式有时被称为资源获取即初始化(Resource Acquisition Is Initialization,RAII)。如果您使用过 RAII 模式,就会对 Rust 中的 drop 函数感到熟悉。
????????这种模式对 Rust 代码的编写方式影响深远。现在看来可能很简单,但在更复杂的情况下,当我们想让多个变量使用堆上分配的数据时,代码的行为可能会出乎意料。现在就让我们来探讨其中的一些情况。
1.4.1?与 "Move?"互动的变量和数据
????????在 Rust 中,多个变量可以以不同的方式与相同的数据交互。
let x = 5;
let y = x;
????????我们大概可以猜到这是在做什么:"将 5 的值绑定到 x ;然后复制 x 中的值,并将其绑定到 y "。现在我们有了两个变量 x 和 y ,它们都等于 5 。这确实是正在发生的事情,因为整数是具有已知固定大小的简单值,而这两个 5 值被推入栈中。
????????现在让我们看看 String 版本:
let s1 = String::from("hello");
let s2 = s1;
????????这看起来非常相似,因此我们可能会认为其工作方式是相同的:即第二行将复制 s1 中的值并将其绑定到 s2 。但事实并非如此。
????????请看下图,了解 String 的内部结构。

????????String 由三部分组成,如左上图所示:指向存放字符串内容的内存的指针、长度和容量。这组数据存储在栈中。右上图是堆上存放内容的内存。
????????长度是指 String 的内容当前使用了多少内存(以字节为单位)。容量是 String 从分配器获得的内存总量(以字节为单位)。长度和容量之间的差值很重要,但在此情况下并不重要,所以目前忽略容量即可。
????????当我们将 s1 赋值给 s2 时,会复制 String 的数据,这意味着我们复制了堆栈中的指针、长度和容量。我们不会复制指针指向的堆上的数据。换句话说,内存中的数据表示如下图所示。
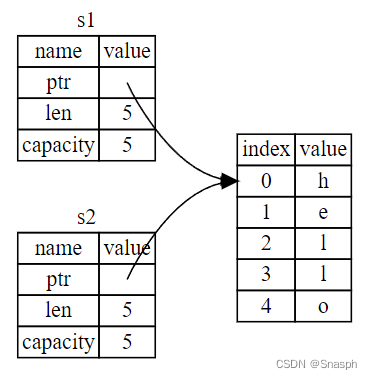
????????如果 Rust 将堆数据也复制到内存中,那么内存的表示形式就会如下图所示。如果 Rust 这样做,如果堆上的数据很大, s2 = s1 ,运行时的性能可能会非常昂贵。

????????前面我们说过,当变量退出作用域时,Rust 会自动调用 drop 函数并清理该变量的堆内存。但两个数据指针都指向同一个位置。这是一个问题:当 s2 和 s1 变量退出作用域时,它们都会尝试释放相同的内存。这就是所谓的双重释放错误,也是我们之前提到的内存安全漏洞之一。释放两次内存会导致内存损坏,从而可能导致安全漏洞。
????????为了确保内存安全,在s2 = s1之后,Rust 认为 s1 不再有效。因此,当 s1 退出作用域时,Rust 不需要释放任何东西。看看在 s2 创建后尝试使用 s1 会发生什么:它不会工作;
fn main() {
let s1 = String::from("rust!");
let s2 = s1;
println!("Hello, {}", s1);
}????????你会得到这样如下所示的一个错误,因为 Rust 阻止你使用已失效的引用:
cargo.exe build
Compiling ownership v0.1.0 (E:\rustProj\ownership)
warning: unused variable: `s2`
--> src\main.rs:3:9
|
3 | let s2 = s1;
| ^^ help: if this is intentional, prefix it with an underscore: `_s2`
|
= note: `#[warn(unused_variables)]` on by default
error[E0382]: borrow of moved value: `s1`
--> src\main.rs:5:27
|
2 | let s1 = String::from("rust!");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("Hello, {}", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
warning: `ownership` (bin "ownership") generated 1 warning
error: could not compile `ownership` (bin "ownership") due to previous error; 1 warning emitted????????如果你在使用其他语言时听说过 "浅复制 "和 "深复制 "这两个术语,那么复制指针、长度和容量而不复制数据的概念听起来可能就像是在进行 "浅复制"。但是,由于 Rust 也会使第一个变量失效,所以它不叫浅层拷贝,而叫移动(Move)。在这个例子中,我们会说 s1 被移动到了 s2 中。因此,实际发生的情况如下图所示:
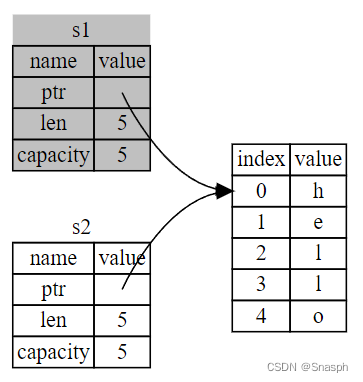
????????这就解决了我们的问题!只需 s2 有效,当它超出范围时,它就会释放内存,我们就大功告成了。
????????此外,这还隐含着一个设计选择:Rust 不会自动创建数据的 "深度 "副本。因此,可以认为任何自动复制在运行时性能方面都是低成本的。
1.4.2?与"Clone"互动的变量和数据
????????如果我们确实想深度复制 String 的堆数据,而不仅仅是栈数据,我们可以使用一个名为 clone 的常用方法。我们将在后面章节讨论其语法。
????????下面是 clone 方法的运行示例:
fn main() {
let s1 = String::from("rust!");
let s2 = s1.clone();
println!("Hello, {}", s1);
println!("Hello, {}", s2);
}????????该方法运行正常,说明堆数据确实被复制了。
cargo.exe run
Compiling ownership v0.1.0 (E:\rustProj\ownership)
Finished dev [unoptimized + debuginfo] target(s) in 0.32s
Running `target\debug\ownership.exe`
Hello, rust!
Hello, rust!????????当你看到对 clone 的调用时,你就知道一些任意代码正在被执行,而且这些代码可能很昂贵。这是一个直观的指示器,表明正在发生一些不同的事情。
1.4.3?栈专用数据:复制
????????还有一个问题我们还没有谈到。使用下面所示的代码,变量是有效的:
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
????????但这段代码似乎与我们刚刚学到的内容相矛盾:我们没有调用 clone ,但 x 仍然有效,并没有被移入 y 。
????????原因是,在编译时已知大小的整数等类型完全存储在栈中,因此实际值的拷贝很快就能完成。这就意味着,在创建变量 y 之后,我们没有理由阻止 x 有效。换句话说,这里的深拷贝和浅拷贝没有区别,所以调用 clone 与通常的浅拷贝没有任何区别,我们可以不调用它。
????????Rust 有一个特殊的注解叫做 :Copy特质,我们可以把它放在像整数一样存储在堆栈中的类型上。如果一个类型实现了 Copy特质,那么使用它的变量就不会移动,而是被微不足道地复制,使得它们在赋值给另一个变量后仍然有效。
????????如果一个类型或其任何部分实现了 Drop 特质,Rust 不会让我们用 Copy 对该类型进行注解。如果该类型需要在值离开作用域时发生一些特殊情况,而我们在该类型中添加了 Copy 注释,那么就会出现编译时错误。
????????那么,哪些类型实现了 Copy 特质呢?您可以查看给定类型的文档来确定,以下是一些实现了 Copy 的类型:
????????①. 所有整数类型,如 u32;
????????②. 布尔类型 bool ,其值为 true 和 false ;
????????③. 所有浮点类型,如 f64;
????????④. 字符类型 char;
????????⑤.?元组,如果它们只包含也实现 Copy 的类型。例如, (i32, i32) 实现了 Copy ,但 (i32, String) 没有;
1.5 所有权和函数
????????将数值传递给函数的机制与为变量赋值的机制类似。将变量传递给函数会像赋值一样移动或复制变量。如下示例,一些注释显示了变量进入和退出作用域的位置。
fn main() {
let s = String::from("hello"); // s comes into scope
takes_ownership(s); // s's value moves into the function...
// ... and so is no longer valid here
let x = 5; // x comes into scope
makes_copy(x); // x would move into the function,
// but i32 is Copy, so it's okay to still
// use x afterward
} // Here, x goes out of scope, then s. But because s's value was moved, nothing
// special happens.
fn takes_ownership(some_string: String) { // some_string comes into scope
println!("{}", some_string);
} // Here, some_string goes out of scope and `drop` is called. The backing
// memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{}", some_integer);
} // Here, some_integer goes out of scope. Nothing special happens.????????如果我们试图在调用 takes_ownership 之后使用 s ,Rust 会在编译时抛出错误。这些静态检查可以防止我们犯错。试着在 main 中添加使用 s 和 x 的代码,看看在哪些地方可以使用它们,在哪些地方所有权规则会阻止你这样做。
cargo.exe build
Compiling ownership v0.1.0 (E:\rustProj\ownership)
error[E0382]: borrow of moved value: `s`
--> src\main.rs:8:31
|
2 | let s = String::from("hello");
| - move occurs because `s` has type `String`, which does not implement the `Copy` trait
3 | take_ownership(s);
| - value moved here
...
8 | println!("x:{}, s:{}", x, s);
| ^ value borrowed here after move
|
note: consider changing this parameter type in function `take_ownership` to borrow instead if owning the value isn't necessary
--> src\main.rs:11:32
|
11 | fn take_ownership(some_string: String) {
| -------------- ^^^^^^ this parameter takes ownership of the value
| |
| in this function
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | take_ownership(s.clone());
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to previous error1.6 返回值及作用域
????????返回值也可以转移所有权。
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns one
fn takes_and_gives_back(a_string: String) -> String { // a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}????????变量的所有权每次都遵循相同的模式:将一个值赋值给另一个变量会移动它。当包含堆中数据的变量退出作用域时,除非数据的所有权已转移到另一个变量,否则该值将由 drop 清理。
????????虽然这种方法可行,但在每个函数中获取所有权并返回所有权有点繁琐。如果我们想让函数使用某个值,但又不想获取所有权,该怎么办呢?如果我们想再次使用传递进来的任何值,都需要将其传递回去,此外,我们可能还想返回函数主体产生的任何数据,这就相当烦人了。
????????Rust 确实允许我们使用元组返回多个值:
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() returns the length of a String
(s, length)
}????????但是,对于一个本应很常见的概念来说,这样做的仪式和工作量都太大了。幸运的是,Rust 有一种使用值而不转移所有权的功能,叫做引用。
2. 引用与借用
? ? ? ?上述的元组代码的问题在于,我们必须将 String 返回给调用函数,以便在调用 calculate_length 后仍能使用 String ,因为 String 已被移入 calculate_length 。相反,我们可以提供一个指向 String 值的引用。引用与指针类似,它是一个地址,我们可以根据它访问存储在该地址的数据;该数据为其他变量所有。与指针不同的是,引用可以保证在其生命周期内指向特定类型的有效值。
????????以下是如何定义和使用 calculate_length 函数,该函数的参数是对象的引用,而不是值的所有权:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("length:{}, s1:{}", len, s1);
}
fn calculate_length(s: &String) -> usize {
s.len()
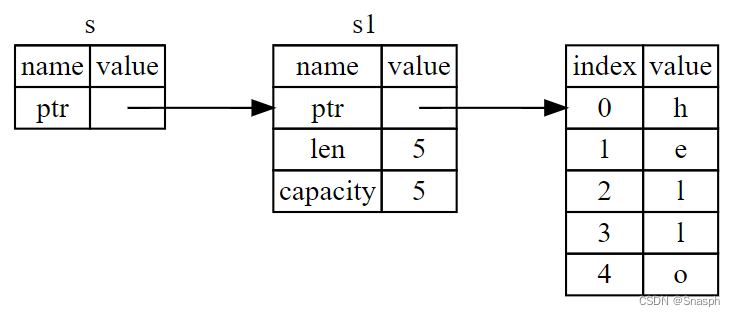
}????????首先,请注意变量声明和函数返回值中的所有元组代码都消失了。其次,请注意我们将 &s1 传递到了 calculate_length 中,而且在其定义中,我们使用的是 &String 而不是 String 。&符号代表引用,它们允许你引用某个值而不占有它的所有权。下图描述了这一概念:
????????注:与 & 引用相反的是取消引用,取消引用是通过取消引用操作符 * 来实现的。
也就是C/C++中的”解引符“;
????????让我们仔细看看这里的函数调用:
let s1 = String::from("hello");
let len = calculate_length(&s1);????????通过 &s1 语法,我们可以创建一个指向 s1 的值但不拥有它的引用。由于它不拥有该值,因此当引用停止使用时,它所指向的值不会被删除。
????????同样,函数的签名使用 & 表示参数 s 的类型是引用。让我们添加一些解释性注释:
fn calculate_length(s: &String) -> usize { // s is a reference to a String
s.len()
} // Here, s goes out of scope. But because it does not have ownership of what
// it refers to, it is not dropped.????????变量 s 的作用域与任何函数参数的作用域相同,但当 s 停止使用时,引用所指向的值不会丢弃,因为 s 并不拥有所有权。当函数将引用作为参数而不是实际值时,我们不需要返回值来归还所有权,因为我们从未拥有过所有权。
????????我们将创建引用的行为称为:借用。在现实生活中,如果某人拥有某样东西,你可以向他借用。借完后,你必须还回去。你并不拥有它。
????????那么,如果我们试图修改借用的东西,会发生什么呢?试试下面的代码。剧透警告:它不工作!
fn main() {
let s1 = String::from("hello");
change(&s1);
println!("s1:{}", s1);
}
fn change(some_string: &String) {
some_string.push_str(", rust!");
}?????????错误就在这里:
cargo.exe build
Compiling ownership v0.1.0 (E:\rustProj\ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src\main.rs:9:5
|
9 | some_string.push_str(", rust!");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
8 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to previous error????????正如变量默认是不可变的一样,引用也是不可变的。我们不能修改我们拥有引用的东西。
2.1 可变引用
????????我们可以修改上述的代码,只需稍作调整,使用可变引用即可修改借用值:
fn main() {
let mut s1 = String::from("hello");
change(&mut s1);
println!("s1:{}", s1);
}
fn change(some_string: &mut String) {
some_string.push_str(", rust!");
}
????????首先,我们将 s1 改为 mut 。然后,我们用 &mut s1 创建一个可变引用,在此调用 change 函数,并用 some_string: &mut String 更新函数签名以接受可变引用。这就清楚地表明, change 函数将改变它所借用的值。
????????可变引用有一个很大的限制:如果对某个值有可变引用,就不能对该值有其他引用。试图创建两个对 s1?的可变引用的代码将失败:
fn main() {
let mut s1 = String::from("hello");
let r1 = &mut s1;
let r2 = &mut s2;
println!("{}, {}", r1, r2);
}
????????错误就在这里:
cargo.exe run
Compiling ownership v0.1.0 (D:\rustProj\ownership)
error[E0499]: cannot borrow `s1` as mutable more than once at a time
--> src\main.rs:5:14
|
4 | let r1 = &mut s1;
| ------- first mutable borrow occurs here
5 | let r2 = &mut s1;
| ^^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to previous error????????这个错误说明这段代码无效,因为我们不能将 s1 作为可变引用同时借用多次。第一个可变引用在 r1 中,必须持续到在 println! 中使用为止,但在创建该可变引用和使用该引用之间,我们试图在 r2 中创建另一个可变引用,该引用借用了与 r1 相同的数据。
????????在任何时候,你都可以拥有一个可变引用或任意数量的不可变引用。
????????防止同时对同一数据进行多个可变引用的限制允许变异,但变异是在非常受控的情况下进行的。这也是 Rustace 新手比较头疼的问题,因为大多数语言都允许随时变异。这种限制的好处是,Rust 可以在编译时防止数据竞争。数据竞争,会在这三种行为发生时出现:
????????①. 两个或多个指针同时访问相同的数据。
????????②.?至少有一个指针被用来写入数据。
????????③.?没有同步访问数据的机制。
????????数据竞争会导致未定义的行为,当你试图在运行时跟踪它们时,会很难诊断和修复;Rust 拒绝编译带有数据竞争的代码,从而避免了这个问题!
????????一如既往,我们可以使用大括号创建一个新的作用域,允许多个可变引用,但不能同时引用:
fn main() {
let mut s1 = String::from("hello");
{
let r1 = &mut s1;
} // r1 goes out of scope here, so we can make a new reference with no problems.
let r2 = &mut s1;
println!("{}", r2);
}
????????Rust 对组合可变引用和不可变引用执行类似的规则。这段代码会导致错误:
fn main() {
let mut s1 = String::from("hello");
let r1 = &s1; // no problem
let r2 = &s1; // no problem
let r3 = &mut s1; // BIG PROBLEM
println!("{}, {}, and {}", r1, r2, r3);
}
????????错误就在这里:
cargo.exe run
Compiling ownership v0.1.0 (D:\rustProj\ownership)
error[E0502]: cannot borrow `s1` as mutable because it is also borrowed as immutable
--> src\main.rs:6:14
|
4 | let r1 = &s1; // no problem
| --- immutable borrow occurs here
5 | let r2 = &s1; // no problem
6 | let r3 = &mut s1; // BIG PROBLEM
| ^^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to previous error? ? ? ? 也就是说,我们也不能在对同一值拥有不可变引用的同时拥有一个可变引用。
上述的表达其实不太准确,主要是要看:变量作用域;
????????不可变引用的用户不会指望值会突然从他们脚下消失!然而,多个不可变引用是允许的,因为正在读取数据的人没有能力影响其他人对数据的读取。
????????请注意,引用的作用域从引入引用的地方开始,直到最后一次使用引用为止。例如,这段代码可以编译,因为不可变引用的最后一次使用( println! )发生在引入可变引用之前:
fn main() {
let mut s1 = String::from("hello");
let r1 = &s1; // no problem
let r2 = &s1; // no problem
println!("{}, {}", r1, r2);
// // variables r1 and r2 will not be used after this point
let r3 = &mut s1; // no problem
println!("{}", r3);
}
????????不可变引用 r1 和 r2 的作用域在最后一次使用它们的 println! 之后结束,也就是在创建可变引用 r3 之前结束。这些作用域并不重叠,因此允许使用此代码:编译器可以判断出引用在作用域结束前的某一点不再被使用。
????????尽管借用错误有时会令人沮丧,但请记住,这是 Rust 编译器在早期(编译时而不是运行时)就指出了潜在的错误,并准确地告诉你问题所在。这样,你就不必去追查为什么你的数据和你想象的不一样了。
2.2?悬而未决的引用
????????在使用指针的语言中,很容易错误地创建一个悬空指针(dangling pointer),即通过释放一些内存,同时保留指向该内存的指针,来引用内存中可能已经给了其他人的位置。相比之下,在 Rust 中,编译器会保证引用永远不会成为悬空引用:如果你有一个指向某些数据的引用,编译器会确保数据不会在指向该数据的引用退出作用域之前退出。????????
????????让我们尝试创建一个悬挂引用,看看 Rust 是如何通过编译时错误来防止它们的:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}
????????错误信息如下:
cargo.exe build
Compiling ownership v0.1.0 (D:\rustProj\ownership)
error[E0106]: missing lifetime specifier
--> src\main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
5 | fn dangle() -> &'static String {
| +++++++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to previous error????????这条错误信息涉及到我们尚未涉及的一项功能:生命周期。我们将在后面章节详细讨论生命周期。但是,如果不考虑有关生命周期的部分,这条信息确实包含了为什么这段代码会出现问题的关键所在:
this function's return type contains a borrowed value, but there is no value for it to be borrowed from????????让我们仔细看看 dangle 代码的每个阶段到底发生了什么:
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope, and is dropped. Its memory goes away.
// Danger!????????因为 s 是在 dangle 内部创建的,所以当 dangle 的代码编写完成后, s 将被取消分配。但我们试图返回对它的引用。这意味着该引用将指向一个无效的 String 。这可不行!Rust 不允许我们这样做。
????????解决办法是直接返回 String :
fn dangle() -> String {
let s = String::from("hello");
s
}????????这样做没有任何问题。所有权被移出,没有任何东西被去分配。
3. slices切片类型
????????切片允许你引用一个集合中连续的元素序列,而不是整个集合。切片是一种引用,因此不具有所有权。
????????这里有一个编程小问题:编写一个函数,接收一个由空格分隔的单词字符串,并返回在该字符串中找到的第一个单词。如果函数在字符串中找不到空格,那么整个字符串一定是一个单词,所以应该返回整个字符串。
????????让我们来看看在不使用分片的情况下如何编写这个函数的签名,以了解分片将解决的问题:
fn first_word(s: &String) -> ?????????first_word 函数的参数是 &String 。我们不需要所有权,所以这没有问题。但我们应该返回什么呢?我们其实没有办法讨论字符串的一部分。不过,我们可以返回单词末尾用空格表示的索引。让我们试试看,如下所示。
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
????????由于我们需要逐个元素查看 String ,并检查某个值是否是空格,因此我们将使用 as_bytes 方法将 String 转换为字节数组。
let bytes = s.as_bytes();????????接下来,我们使用 iter 方法在字节数组上创建一个迭代器:
for (i, &item) in bytes.iter().enumerate() {????????我们将在后面章节详细讨论迭代器。现在,我们知道 iter 是一个返回集合中每个元素的方法,而 enumerate 封装了 iter 的结果,并将每个元素作为元组的一部分返回。 enumerate 返回的元组的第一个元素是索引,第二个元素是元素的引用。这比我们自己计算索引要方便一些。
????????因为 enumerate 方法返回一个元组,所以我们可以使用模式来重组这个元组。我们将在后面章节详细讨论模式。在 for 循环中,我们指定了一个模式,其中 i 表示元组中的索引, &item 表示元组中的单字节。由于我们从 .iter().enumerate() 获得了元素的引用,因此我们在模式中使用 & 。
????????在 for 循环中,我们使用字节文字语法搜索代表空格的字节。如果找到空格,则返回位置。否则,我们将使用 s.len() 返回字符串的长度。
if item == b' ' {
return i;
}
}
s.len()
????????我们现在有办法找出字符串中第一个单词末尾的索引,但有一个问题。我们单独返回一个 usize ,但它只有在 &String 的上下文中才是一个有意义的数字。换句话说,由于它是一个独立于 String 的值,因此无法保证它在未来仍然有效。请看下面的程序,它使用了上述中的 first_word 函数。
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word will get the value 5
s.clear(); // this empties the String, making it equal to ""
// word still has the value 5 here, but there's no more string that
// we could meaningfully use the value 5 with. word is now totally invalid!
}
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
????????如果我们在调用 s.clear() 之后使用 word ,这个程序编译时也不会出现任何错误。因为 word 与 s 的状态完全无关,所以 word 仍然包含值 5 。我们可以使用该值 5 和变量 s 来尝试提取出第一个单词,但这将是一个错误,因为自从我们将 5 保存到 word 后, s 的内容已经发生了变化。
????????要担心 word 中的索引与 s 中的数据不同步,既繁琐又容易出错!如果我们编写一个 second_word 函数,管理这些索引就会变得更加困难。它的签名应该是这样的:
fn second_word(s: &String) -> (usize, usize) {????????现在,我们要跟踪一个起始索引和一个终止索引,还有更多的值是根据特定状态下的数据计算出来的,但与该状态完全无关。我们有三个不相关的变量需要保持同步。
????????幸运的是,Rust 可以解决这个问题:字符串切片。
3.1?字符串切片
????????字符串切片是对 String 部分内容的引用,它看起来像这样:
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
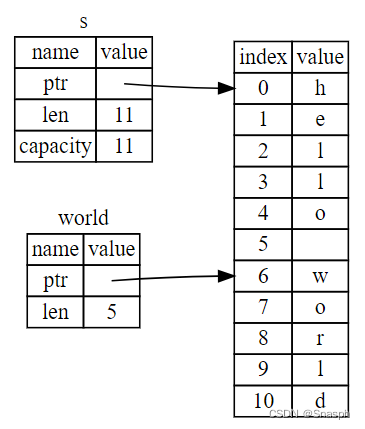
????????hello 不是对整个 String 的引用,而是对 String 的一部分的引用,由额外的 [0..5] 位指定。我们使用括号内的范围创建分片,方法是指定 [starting_index..ending_index] ,其中 starting_index 是分片中的第一个位置, ending_index 是比分片中最后一个位置多一个的位置。在内部,切片数据结构存储切片的起始位置和长度,即 ending_index 减去 starting_index 。因此,在 let world = &s[6..11]; 的情况下, world 将是一个包含指向 s 索引 6 的字节指针的片段,其长度值为 5 。
? ? ? ? 下图展示了这一点:
????????使用 Rust 的 .. range 语法,如果您想从索引 0 开始,可以去掉两个句点之前的值。换句话说,这些值是相等的:
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
????????同样,如果您的片段包括 String 的最后一个字节,则可以去掉尾数。这意味着这两个值相等:
let s = String::from("hello");
let len = s.len();
let slice = &s[3..len];
let slice = &s[3..];
????????也可以去掉两个值,对整个字符串进行切分。所以这两个值是相等的:
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
????????注意:字符串片段范围索引必须位于有效的 UTF-8 字符边界。如果试图在多字节字符中间创建字符串片段,程序将错误退出。
????????有了这些信息,让我们重写 first_word 来返回一个切片。表示 "字符串切片 "的类型写为 &str :
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}????????我们将按照上述方法,通过查找首次出现的空格来获取单词结尾的索引。找到空格后,我们将以字符串的起始位置和空格索引作为起始和结束索引,返回一个字符串切片。
????????现在,当我们调用 first_word 时,会得到一个与底层数据相关联的值。该值由切片起点的引用和切片中元素的数量组成。
????????对于 second_word 函数来说,返回切片也是可行的:
fn second_word(s: &String) -> &str {????????现在,我们有了一个简单明了的 API,而且更难出错,因为编译器会确保对 String 的引用保持有效。当时我们的索引到达了第一个单词的末尾,但随后又清除了字符串,因此我们的索引无效。这段代码在逻辑上是错误的,但并没有立即显示任何错误。如果我们继续尝试在清空字符串的情况下使用第一个单词的索引,问题就会在稍后出现。而切片则不会出现这种错误,并能让我们更早地知道代码出现了问题。使用 first_word 的片段版本会出现编译时错误:
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is:{}", word);
}
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}????????下面是编译器错误:
argo.exe build
Compiling ownership v0.1.0 (D:\rustProj\ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src\main.rs:6:5
|
4 | let word = first_word(&s);
| -- immutable borrow occurs here
5 |
6 | s.clear();
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("the first word is:{}", word);
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to previous error????????从借用规则中可以忆及,如果我们有一个不可变的引用,我们就不能同时获取一个可变的引用。因为 clear 需要截断 String ,所以它需要获取一个可变引用。在调用 clear 之后的 println! 会使用 word 中的引用,因此不可变引用在此时必须仍然有效。Rust 不允许 clear 中的可变引用和 word 中的不可变引用同时存在,因此编译失败。Rust 不仅使我们的应用程序接口更易于使用,而且还消除了编译时的一整类错误!
3.2?作为切片的字符串字面量
????????回想一下,我们说过字符串字面量存储在二进制文件中。现在我们知道了分片,就能正确理解字符串字面量了:
let s = "Hello, world!";
????????s 的类型是 &str :它是指向二进制文件中特定点的片段。这也是字符串文字不可变的原因; &str 是不可变的引用。
3.3?字符串切片作为参数
????????了解到可以对字面量和 String 值进行分片后,我们就可以对 first_word 进行进一步改进,这就是它的签名:
fn first_word(s: &String) -> &str {????????更有经验的 Rustacean 会改写签名,因为它允许我们在 &String 值和 &str 值上使用相同的函数。
fn first_word(s: &str) -> &str {
????????如果我们有一个字符串片段,我们可以直接传递它。如果有 String ,我们可以传递 String 的片段或 String 的引用。我们将在后面章节?"函数和方法的隐式转换 "一节中介绍这一功能。
????????定义一个函数来获取字符串切片,而不是 String 的引用,这使得我们的应用程序接口更通用、更有用,而不会丢失任何功能:
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s
let word = first_word(&my_string);
}
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i]
}
}
&s[..]
}
3.4?其他切片
????????如你所想,字符串切片是专门针对字符串的。但还有一种更通用的切片类型。请看这个数组:
let a = [1, 2, 3, 4, 5];
????????就像我们可能想引用字符串的一部分一样,我们也可能想引用数组的一部分。我们可以这样做:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
????????该分片的类型是 &[i32] 。它的工作方式与字符串切片相同,都是存储第一个元素的引用和长度。
下一篇:使用结构体构建相关数据;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Qt中多线程使用案列
- 电脑数据找回怎么操作?这4个方法记得收藏!
- Vue与React数据流设计比较:响应式与单向数据流
- shell 数组的详细用法
- leetcode:412. Fizz Buzz(python3解法)
- 以STM32F103C8T6为主控实现的RFID感应宿舍门锁开关
- YASKAWA ERCR-NS01-B004-E1机器人控制器
- IEEE论文作者简介部分中的M’10–SM’16含义,一些没用的小知识又增加了^_^
- 我在Vscode学OpenCV 图像处理五(直方图处理)
- ssm办公信息化管理系统app(开题+源码)