Linux(20):软件安装:原始码与 Tarball
开放源码的软件安装与升级
在Windows系统上面的软件都是一模一样的,【无法修改该软件的源代码】,因此,万一想要增加或者减少该软件的某些功能时,无能为力。。。
Linux 上面的软件几乎都是经过 GPL 的授权,所以每个软件几乎均提供源代码,并且可以自行修改该程序代码,以符合个人的需求。
开放性源码、编译程序与可执行文件
可执行文件:在 Linux 系统上面,一个文件能不能被执行看的是有没有可执行的那个权限(具有 x permission),不过,Linux系统上真正认识的可执行文件其实是二进制文件( binary program)。
shell scripts 不是也可以执行吗?其实 shell scripts 只是利用shell(例如 bash)这支程序的功能进行一些判断式,而最终执行的除了bash提供的功能外,仍是呼叫一些已经编译好的二进制程序来执行的。
 如果是 binary 而且是可以执行的时候,他就会显示执行文件类别(ELF 64-bit LSB executable),同时会说明是否使用动态函式库(shared libs),而如果是一般的 script ,那他就会显示出 text executables 之类的字样。
如果是 binary 而且是可以执行的时候,他就会显示执行文件类别(ELF 64-bit LSB executable),同时会说明是否使用动态函式库(shared libs),而如果是一般的 script ,那他就会显示出 text executables 之类的字样。
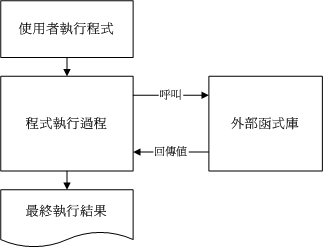
做出一支 binary 的程序:首先,必须要写程序,使用vim来进行程序的撰写,写完的程序就是所谓的源代码,这个程序代码文件其实就是一般的纯文本档。在完成这个原始码文件的编写之后,再来就是要将这个文件【编译】成为操作系统看的懂得binary program。而要编译自然就需要【编译程序】来动作,经过编译程序的编译与连结之后,就会产生一支可以执行的 binary program 了。
利用 gcc 编译程序进行程序的编译流程示意图:
 事实上,在编译的过程当中还会产生所谓的目标文件(Object file),这些文件是以
事实上,在编译的过程当中还会产生所谓的目标文件(Object file),这些文件是以*.o的扩展名样式存在的。至于C语言的原始码文件通常以*.c作为扩展名。此外,有的时候,在程序当中【引用、呼叫】其他的外部子程序,或者是利用其他软件提供的【函数功能】,这个时候,就必须要在编译的过程当中,将该函式库给他加进去,如此一来,编译程序就可以将所有的程序代码与函式库作一个连结(Link)以产生正确的执行档。
总之,
开放源码:就是程序代码,写给人类看的程序语言,但机器并不认识,所以无法执行;
编译程序:将程序代码转译成为机器看的懂得语言,就类似翻译者的角色;
可执行文件:经过编译程序变成二进制程序后,机器看的懂所以可以执行的文件。
函式库
函式库分为动态与静态函式库。
程序执行时引用外部动态函式库:
如果要在程序里面加入引用的函式库,就需要在编译的过程当中,就需要加入函式库的相关设定。事实上,Linux 的核心提供很多的核心相关函式库与外部参数,这些核心功能在设计硬件的驱动程序的时候是相当有用的信息,这些核心相关信息大多放置在 /usr/include, /usr/lib, /usr/lib64 里面。
函式库:就类似子程序的角色,可以被呼叫来执行的一段功能函数。
由于不同的 Linux distribution 的函式库文件所放置的路径,或者是函式库的档名订定,或者是预设安装的编译程序,以及核心的版本都不相同,所以同一套软件要在不同的平台上面执行时,必须要重复编译。
Tarball 的软件
Tarball 文件:能够将原始码透过文件的打包与压缩技术来将文件的数量与容量减小,不但让用户容易下载,软件开发商的网站带宽也能够节省很多很多。
所谓的 Tarball 文件,其实就是将软件的所有原始码文件先以 tar 打包,然后再以压缩技术来压缩,通常最常见的就是以 gzip 来压缩了。因为利用了 tar 与 gzip 的功能,所以 tarball 文件一般的扩展名就会写成*.tar.gz或者是简写为*.tgz。不过,近来由于 bzip2 与 xz 的压缩率较佳,所以,Tarball 渐渐的以 bzip2 及 xz 的压缩技术来取代 gzip 。因此档名也会变成 *.tar.bz2,*.tar.xz之类的哩。
所以,Tarball是一个软件包,将他解压缩之后,里面的文件通常就会有:
源代码文件;
侦测程序文件(可能是configure或config 等槽名);
本软件的简易说明与安装说明(INSTALL或README)。
安装与升级软件
将原始码作了一个简单的介绍,也知道了系统其实认识的可执行文件是 binary program之后,好了,得要聊一聊,那么怎么安装与升级一个Tarball 的软件?为什么要安装一个新的软件呢?当然是因为我们的主机上面没有该软件啰!那么,为
需要升级的原因:
1.需要新的功能,但旧有主机的旧版软件并没有,所以需要升级到新版的软件;
2.旧版本的软件上面可能有资安上的顾虑,所以需要更新到新版的软件;
3.旧版的软件执行效能不彰,或者执行的能力不能让管理者满足。
基本上更新的方法可以分为两大类,分别是:
1.直接以原始码透过编译来安装与升级;
2.直接以编译好的 binary program 来安装与升级。
上面第一点很简单,就是直接以 Tarball 在自己的机器上面进行侦测、编译、安装与设定等等动作来升级就是了。不过,这样的动作虽然让使用者在安装过程当中具有很高的弹性,但毕竟是比较麻烦一点,如果Linux distribution 厂商能够针对自己的作业平台先进行编译等过程,再将编译好的 binary program 释出的话,那由于系统与该 Linux distribution 的环境是相同的,所以他所释出的 binary program就可以在机器上面直接安装。
一个软件的 Tarball 安装的基本流程:
1.将 Tarball 由厂商的网页下载下来;
2.将 Tarball 解开,产生很多的原始码文件;
3.开始以 gcc 进行原始码的编译(会产生目标文件 object files);
4.然后以 gcc 进行函式库、主、子程序的链接,以形成主要的 binary file;
5.将上述的 binary file 以及相关的配置文件安装至自己的主机上面。
使用传统程序语言进行遍编译
单一程序:输出 Hello World
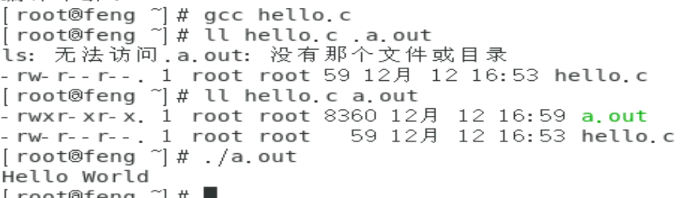 在预设的状态下,如果直接以 gcc 编译原始码,并且没有加上任何参数,则执行档的档名会被自动设定为 a.out 这个文件名。所以就能够直接执行./a.out 这个执行档。
在预设的状态下,如果直接以 gcc 编译原始码,并且没有加上任何参数,则执行档的档名会被自动设定为 a.out 这个文件名。所以就能够直接执行./a.out 这个执行档。
那个 hello.c 就是原始码,而 gcc 就是编译程序,至于 a.out 就是编译成功的可执行 binary program。
如果想要产生目标文件(object file)来进行其他的动作,而且执行档的档名也不要用预设的 a.out ,可以将上面的第②个步骤改成这样:
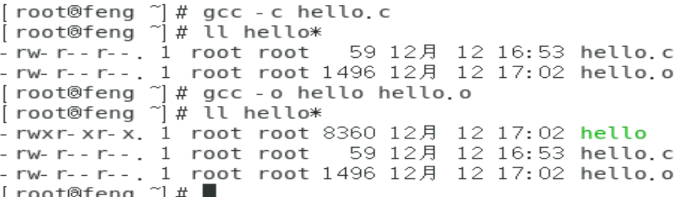
主、子程序链接:子程序的编译
1.编写所需要的主、子程序

2.编译与链接

由于原始码文件有时并非仅只有一个文件,所以无法直接进行编译。这个时候就需要先产生目标文件,然后再以连结制作成为 binary 可执行文件。另外,如果更新了 thank_2.c 这个文件的内容,则只要重新编译 thank_2.c 来产生新的 thank_2.o ,然后再以连结制作出新的 binary可执行文件即可。而不必重新编译其他没有更动过的原始码文件。
-Wall 可以产生更详细的编译过程信息。

呼叫外部函式库:加入连结的函式库
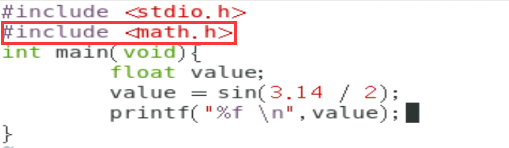
 新版的GCC会主动帮将所需要的函式库抓进来编译,只要使用
新版的GCC会主动帮将所需要的函式库抓进来编译,只要使用 #include 加进来就可以。。。
编译时加入额外函式库连结的方式:
数学函式库使用的是 libm.so 这个函式库,最好在编译的时候将这个函式库纳进去比较好。要注意的是,这个函式库放置的地方是系统默认会去找的 /lib,/lib64 ,所以无须使用底下的- L 去加入搜寻的目录。 而 libm.so 在编译的写法上,使用的是 -lm (lib简写为l)因此就变成:
gcc sin.c -lm -L/lib -L/lib64
./.out
使用 gcc 编译时所加入的 -lm 是有意义的,可以拆开成两部份来看:
-l:是【加入某个函式库(library)】的意思;
m:则是 libm.so 这个函式库,其中,lib 与扩展名( .a或.so)不需要写
所以-Im表示使用 libm.so (或libm.a)这个函式库的意思,-L后面接的路径表示:【要的函式库 libm.so 到/lib或/lib64里面搜寻】
gcc 的简易用法
gcc 为 Linux 上面最标准的编译程序,gcc 是由 GNU 计划所维护的。
gcc -c hello.c
# 自动产生 hello.o 这个文件,但是不会产生 binary 执行档
gcc -O hello.c -c
# 会自动产生 hello.c 这个文件,并且进行优化
gcc sin.c -lm -L/lib -I/usr/include
# 这个命令通常下达在最终连结成 binary file 的时候
# -lm 指的是 libm.so 或 libm.a 这个函式库文件;
# -L 后面接的路径是刚刚上面那个函式库的搜寻目录;
# -I 后面接的是原始码内的 include 文件之所在的目录;
gcc -o hello hello.c
# -o 后面接的是要输出的 binary file 档名
gcc -o hello hello.c -Wall
# 加入 -Wall 之后,编译会更严谨,警告也会显示
通常称-Wall或者-О这些非必要的参数为旗标(FLAGS),因为使用的是C程序语言,所以有时候也会简称这些旗标为 CFLAGS ,这些变量偶尔会被使用。
使用 make 进行宏编译
多个文件相互关联时,编译的过程需要很多动作。make 可以使用一个步骤对其进行编译。
mak的好处:
1.简化编译时所需要下达的指令;
2.若在编译完成之后,修改了某个原始码文件,则 make 仅会针对被修改了的文件进行编译,其他的 object file 不会被更动;
3.最后可以依照相依性来更新(update)执行档。
先编辑 makefile 这个规则文件,内容只要读出 main 执行档:
vim makefile
main:..
gcc -o main ..
然后使用 makefile 制定的规则进行编译的行为:
make
# make 会读取 makefile 的内容,并根据内容直接去给他编译相关文件
最后在不删除任何文件的情况下,重新执行一次编译的动作:
make
# 只会进行更新动作
makefile 的基本语法与变量
基本的 makefile 规则:

那个目标(target) 就是我们想要建立的信息,而目标文件就是具有相关性的 object files,建立执行文件的语法就是以 <tab> 按键开头的那一行,【命令行必须要以 tab 按键作为开头】。
规则基本上是这样的:
在 makefile 当中的 # 代表批注;
<tab> 需要在命令行(例如gcc这个编译程序指令)的第一个字符;
目标(target)与相依文件(就是目标文件)之间需以【:】隔开。
如果有两个以上的执行动作时:

makefile 里面具有至少两个目标,分别是 main 与 clean ,如果想要建立 main 的话,输入【make main】,如果想要清除有的没的,输入【make clean】。而如果想要先清除目标文件再编译 main 这个程序的话,可以输入:【make clean main】。
可以使用变量来写 makefile ,更加简洁方便:
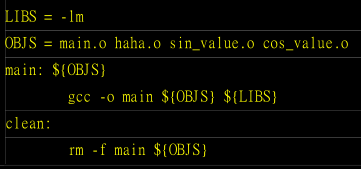
与 bash shell script 的语法有点不太相同,变量的基本语法为:
1.变量与变量内容以【=】隔开,同时两边可以具有空格;
2.变量左边不可以有<tab>;
3.变量与变量内容在【=】两边不能具有【:】;
4.在习惯上,变量最好是以【大写字母】为主;
5.运用变量时,以 ${变量} 或 $(变量) 使用;
6.在该shell 的环境变量是可以被套用的;
7.在指令列模式也可以给予变量。
由于 gcc 在进行编译的行为时,会主动的去读取 CFLAGS 这个环境变量,所以,可以直接在 shell 定义出这个环境变量,也可以在 makefile文件里面去定义,更可以在指令列当中给予。

可以利用指令列进行环境变量的输入,也可以在文件内直接指定环境变量,那万一这个
CFLAGS 的内容在指令列与makefile里面并不相同时,
环境变量取用的规则:
1.make 指令列后面加上的环境变量为优先;
2.makefile 里面指定的环境变量第二;
3.shell 原本具有的环境变量第三。
此外,特殊的变量:
$@:代表目前的目标(target);

Tarball 的管理与建议
Tarball 的安装是可以跨平台的,因为C语言的程序代码在各个平台上面是可以共通的,只是需要的编译程序可能并不相同而已。
使用原始码管理软件所需要的基础软件
1.gcc 或 cc 等C语言编译程序(compiler):
C compiler是一定要有的。Linux 上面有众多的编译程序,其中当然以GNU的 gcc 是首选的自由软件编译程序。很多在 Linux 平台上面发展的软件的原始码是以gcc为底来设计的。
2.make 及 autoconfig 等软件:
一般来说,以Tarball 方式释出的软件当中,为了简化编译的流程,通常都是配合 make 这个指令来依据目标文件的相依性而进行编译。但是 make 需要 makefile这个文件的规则,那由于不同的系统里面可能具有的基础软件环境并不相同,所以就需要侦测用户的作业环境,好自行建立一个makefile文件。这个自行侦测的小程序也必须要由 autoconfig 这个相关的软件来辅助才行。
3.需要 Kernel 提供的 Library 以及相关的 Include 文件:
很多的软件在发展的时候都是直接取用系统核心提供的函式库与include文件的,这样才可以与这个操作系统兼容啊。
Tarball 安装的基本步骤
以 Tarball 方式释出的软件是需要重新编译可执行的 binary program 的。而 Tarball 是以 tar 这个指令来打包与压缩的文件,所以需要先将 Tarball 解压缩,然后到原始码所在的目录下进行 makefile 的建立,再以 make 来进行编译与安装的动作。
所以整个安装的基础动作大多是这样的:
1.取得原始档:将 tarball 文件在 /usr/local/src 目录下解压缩;
2.取得步骤流程:进入新建立的目录底下,去查阅 INSTALL 与 README等相关文件内容(很重要的步骤!);
3.相依属性软件安装:根据 INSTALL/README 的内容察看并安装好一些相依的软件(非必要);
4.建立 makefile:以自动侦测程序(configure或 config)侦测作业环境,并建立 Makefile 这个文件;
5.编译:以 make 这个程序并使用该目录下的 Makefile 做为他的参数配置文件,来进行 make(编译或其他)的动作;
6.安装:以 make 这个程序,并以 Makefile 这个参数配置文件,依据 install 这个目标(target)的指定来安
装到正确的路径。
tarball 软件之安装的指令下达方式:
./configure
建立 Makefile 文件。通常程序开发者会写一支 scripts来检查 Linux系统、相关的软件属性等等,这个步骤相当的重要,因为未来安装信息都是这一步骤内完成的。另外,这个步骤的相关信息应该要参考一下该目录下的 README或INSTALL相关的文件;
make clean
make 会读取 Makefile 中关于 clean 的工作。这个步骤不一定会有,但是希望执行一下,因为可以去除目标文件。因为谁也不确定原始码里面到底有没有包含上次编译过的目标文件(*.o)存在,所以当然还是清除一下比较妥当的。至少等一下新编译出来的执行档可以确定是使用自己的机器所编译完成的。
make
make 会依据 Makefile 当中的预设工作进行编译的行为。编译的工作主要是进行 gcc 来将原始码编译成为可以被执行的 object files ,但是这些 object files 通常还需要一些函式库之类的 link 后,才能产生一个完整的执行档。使用 make 就是要将原始码编译成为可以被执行的可执行文件,而这个可执行文件会放置在目前所在的目录之下,尚未被安装到预定安装的目录中;
make install
通常这就是最后的安装步骤了,make 会依据 Makefile 这个文件里面关于install 的项目,将上一个步骤所编译完成的数据给他安装到预定的目录中,就完成安装了。
一般 Tarball 软件安装的建议事项
Tarball 要在 /usr/loca/src 里面解压缩。基本上,在预设的情况下,原本的 Linux distribution 释出安装的软件大多是在 /usr 里面的,而用户自行安装的软件则建议放置在 /usr/local 里面。
通常建议:
1.最好将 tarball 的原始数据解压缩到 /usr/local/src 当中;
2.安装时,最好安装到 /usr/local 这个默认路径下;
3.考虑未来的反安装步骤,最好可以将每个软件单独的安装在 /usr/local 底下;
4.为安装到单独目录的软件之 man page 加入man path搜寻:
如果安装的软件放置到 /usr/local/software/,那么 man page 搜寻的设定中,可能就得要在 /etc/man_db.conf 内的 40~50 行左右处,写入如下的一行:
MANPATH_MAP/usr/local/software/bin/usr/local/software/man
利用 patch 更新原始码
事实上,当发现一些软件的漏洞,通常是某一段程序代码写的不好所致。因此,所谓的【更新原始码】常常是只有更改部分文件的小部分内容而已。也就是说,旧版本到新版本间没有更动过的文件就不要理他,仅将有修订过的文件部分来处理即可。
好处:首先,没有更动过的文件的目标文件(object file)根本就不需要重新编译,而且有更动过的文件又可以利用 make 来自动 update(更新),如此一来,原先的设定(makefile文件里面的规则)将不需要重新改写或侦测。
指令 diff:可以将两个文件之间的差异性列出来;
然后使用 patch 指令进行更新。释出所谓的 patch file,也就是直接将原始码 update 而已的一个方式。
patch 的基本语法如下:
patch -p 数字 < patch_file
【-p 数字】:是与 patch_file 里面列出的文件名相关的信息。
当下达【patch -p0 < patch_file】时,则更新的文件是【/home/guest/example/expatch.old】,如果【patch -p1 < patch_file】,则更新的文件为【home/guest/example/expatch.old】,如果【patch -p4 < patch_file则更新【expatch.old】,也就是说,-pxx那个 xx 代表【拿掉几个斜线(\)】的意思。
更新 patch file 后,还得要将软件重新编译后,才会得到最终正确的软件。patch 的功能主要仅只是针对更新原始码文件而已。
函式库管理
Linux操作系统当中,函式库是很重要的一个项目。因为很多的软件之间都会互相取用彼此提供的函式库来进行特殊功能的运作。
动态与静态函式库
静态函式库的特色:
扩展名:(扩展名为.a)
这类的函式库通常扩展名为 libxxx.a 的类型;
编译行为:
这类函式库在编译的时候会直接整合到执行程序当中,所以利用静态函式库编译成的文件会比较大一些;
独立执行的状态:
编译成功的可执行文件可以独立执行,而不需要再向外部要求读取函式库的内容;
升级难易度:
虽然执行档可以独立执行,但因为函式库是直接整合到执行档中,因此若函式库升级时,整个执行档必须要重新编译才能将新版的函式库整合到程序当中。
动态函数库的特色:
扩展名:(扩展名为.so)
这类函式库通常扩展名为libxxx.so的类型;
编译行为:
动态函式库与静态函式库的编译行为差异挺大的。与静态函式库被整个捉到程序中不同的,动态函式库在编译的时候,在程序里面只有一个【指向(Pointer)】的位置而已。也就是说,动态函式库的内容并没有被整合到执行档当中,而是当执行档要使用到函式库的机制时,程序才会去读取函式库来使用。由于执行文件当中仅具有指向动态函式库所在的指标而已,并不包含函式库的内容,所以他的文件会比较小一点;
独立执行的状态:
这类型的函式库所编译出来的程序不能被独立执行,因为使用到函式库的机制时,程序才会去读取函式库,所以函式库文件【必须要存在】才行,而且,函式库的【所在目录也不能改变】,因为我们的可执行文件里面仅有【指标】亦即当要取用该动态函式库时,程序会主动去某个路径下读取。所以动态函式库可不能随意移动或删除;
升级难易度:
虽然这类型的执行档无法独立运作,然而由于是具有指向的功能,所以,当函式库升级后,执行档根本不需要进行重新编译的行为,因为执行档会直接指向新的函式库文件(前提是函式库新旧版本的档名相同)。
绝大多数的函式库都放置在:/lib64, /lib目录下。此外,Linux系统里面很多的函式库其实 kernel 就提供了,那么kernel的函式库放在 /lib/modules 里面。、要注意的是,不同版本的核心提供的函式库差异性是挺大的,很容易由于函式库的不同而导致很多原本可以执行的软件无法顺利运作。
ldconfig
目前的 Linux 大多是将函式库做成动态函式库。
增加函式库的读取效能:将常用到的动态函式库先加载内存当中(快取, cache),如此一来,当软件要取用动态函式库时,就不需要从头由硬盘里面读出,就可以增进动态函式库的读取速度。
这个时候就需要 ldconfig 与 /etc/ld.so.conf 了。
如何将动态函式库加载高速缓存当中呢?
1.首先,必须要在 /etc/ld.so.conf 里面写下【想要读入高速缓存当中的动态函式库所在的目录】(是目录不是文件);
2.接下来则是利用 ldconfig 这个执行档将 /etc/ld.so.conf 的资料读入快取当中;
3.同时也将数据记录一份在 /etc/ld.so.cache 这个文件当中。

ldconfig 还可以用来判断动态函式库的链接信息。
ldconfig [-f conf] [-C cache]
ldconfig [-p]


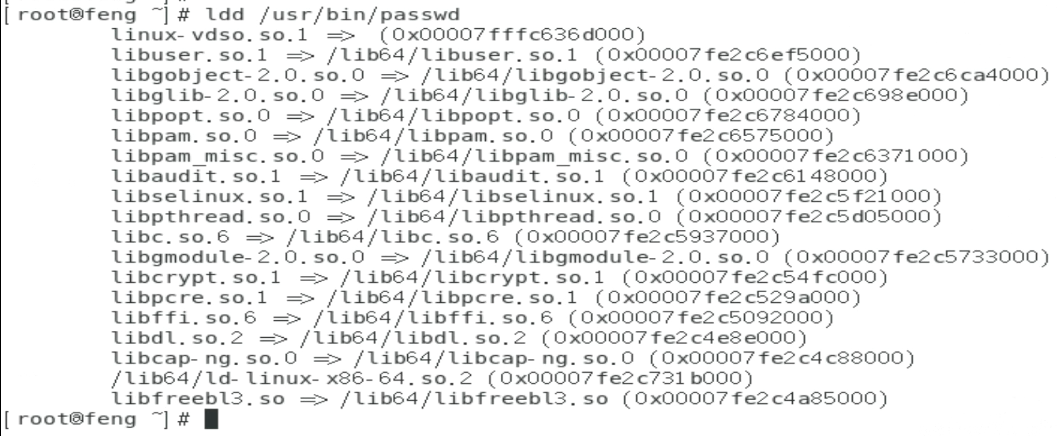
程序的动态函数库解析:ldd
判断某个可执行的 binary 文件含有什么动态函式库:
ldd [-vdr] [filename]

检验软件正确性
可以使用 MD5/sha1或更严密的 sha256 等指纹验证机制来判断该文件有没有被更动过。
举个例子来说,在每个 CentOS7.x 原版光盘的下载点都会有提供几个特别的文件,透过这个编码的比对,就可以晓得下载的文件是否有问题。
md5sum / sha1sum / sha256sum
目前有多种机制可以计算文件的指纹码,可以选择使用较为广泛的 MD5, SHA1 或 SHA256 加密机制来处理。
如何确认下载的文件是正确没问题的呢?这样处理一下:
md5sum/sha1sum/sha256sum [-bct] filename
md5sum/sha1sum/sha256sum [--status--warn] --check filename

。。。用的时候再学吧
《鸟哥的Linux私房菜-基础篇》学习笔记
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!