Linux内核架构和工作原理详解(三)
Linux体系结构和内核结构区别
1.当被问到Linux体系结构(就是Linux系统是怎么构成的)时,我们可以参照下图这么回答:从大的方面讲,Linux体系结构可以分为两块:
(1)用户空间:用户空间中又包含了,用户的应用程序,C库
(2)内核空间:内核空间包括,系统调用,内核,以及与平台架构相关的代码
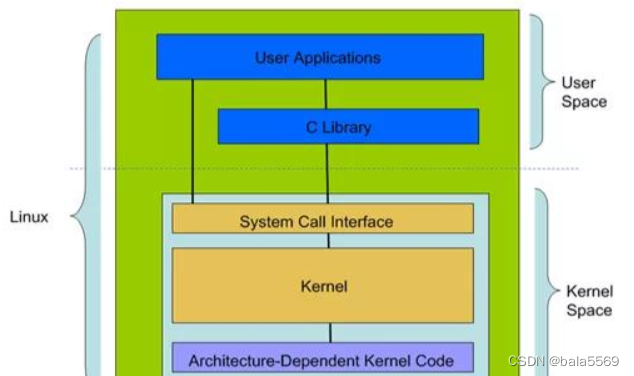
2.Linux体系结构要分成用户空间和内核空间的原因:
1)现代CPU通常都实现了不同的工作模式,
以ARM为例:ARM实现了7种工作模式,不同模式下CPU可以执行的指令或者访问的寄存器不同:
(1)用户模式 usr
(2)系统模式 sys
(3)管理模式 svc
(4)快速中断 fiq
(5)外部中断 irq
(6)数据访问终止 abt
(7)未定义指令异常
以(2)X86为例:X86实现了4个不同级别的权限,Ring0—Ring3 ;Ring0下可以执行特权指令,可以访问IO设备;Ring3则有很多的限制
2)所以,Linux从CPU的角度出发,为了保护内核的安全,把系统分成了2部分;
3.用户空间和内核空间是程序执行的两种不同状态,我们可以通过“系统调用”和“硬件中断“来完成用户空间到内核空间的转移
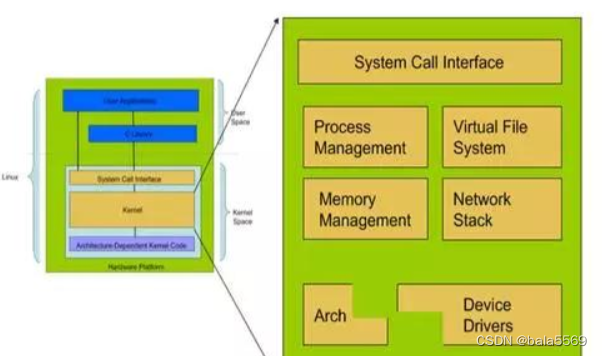
4.Linux的内核结构(注意区分LInux体系结构和Linux内核结构)
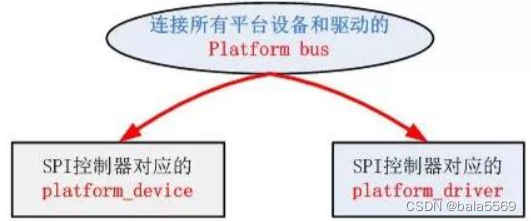
Linux驱动的platform机制
Linux的这种platform driver机制和传统的device_driver机制相比,一个十分明显的优势在于platform机制将本身的资源注册进内核,由内核统一管理,在驱动程序中使用这些资源时通过platform_device提供的标准接口进行申请并使用。这样提高了驱动和资源管理的独立性,并且拥有较好的可移植性和安全性。下面是SPI驱动层次示意图,Linux中的SPI总线可理解为SPI控制器引出的总线:
和传统的驱动一样,platform机制也分为三个步骤:
1、总线注册阶段:
内核启动初始化时的main.c文件中的kernel_init()→do_basic_setup()→driver_init()→platform_bus_init()→bus_register(&platform_bus_type),注册了一条platform总线(虚拟总线,platform_bus)。
2、添加设备阶段:
设备注册的时候Platform_device_register()→platform_device_add()→(pdev→dev.bus = &platform_bus_type)→device_add(),就这样把设备给挂到虚拟的总线上。
3、驱动注册阶段:
Platform_driver_register()→driver_register()→bus_add_driver()→driver_attach()→bus_for_each_dev(), 对在每个挂在虚拟的platform bus的设备作__driver_attach()→driver_probe_device(),判断drv→bus→match()是否执行成功,此时通过指针执行platform_match→strncmp(pdev→name , drv→name , BUS_ID_SIZE),如果相符就调用really_probe(实际就是执行相应设备的platform_driver→probe(platform_device)。)开始真正的探测,如果probe成功,则绑定设备到该驱动。
从上面可以看出,platform机制最后还是调用了bus_register() , device_add() , driver_register()这三个关键的函数。
下面看几个结构体:
struct platform_device
(/include/linux/Platform_device.h)
{
const char * name;
int id;
struct device dev;
u32 num_resources;
struct resource * resource;
};
Platform_device结构体描述了一个platform结构的设备,在其中包含了一般设备的结构体struct device dev;设备的资源结构体struct resource * resource;还有设备的名字const char * name。(注意,这个名字一定要和后面platform_driver.driver àname相同,原因会在后面说明。)
该结构体中最重要的就是resource结构,这也是之所以引入platform机制的原因。
struct resource
( /include/linux/ioport.h)
{
resource_size_t start;
resource_size_t end;
const char *name;
unsigned long flags;
struct resource *parent, *sibling, *child;
};
其中 flags位表示该资源的类型,start和end分别表示该资源的起始地址和结束地址(/include/linux/Platform_device.h):
struct platform_driver
{
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*suspend_late)(struct platform_device *, pm_message_t state);
int (*resume_early)(struct platform_device *);
int (*resume)(struct platform_device *);
struct device_driver driver;
};
Platform_driver结构体描述了一个platform结构的驱动。其中除了一些函数指针外,还有一个一般驱动的device_driver结构。
名字要一致的原因:
上面说的驱动在注册的时候会调用函数bus_for_each_dev(), 对在每个挂在虚拟的platform bus的设备作__driver_attach()→driver_probe_device(),在此函数中会对dev和drv做初步的匹配,调用的是drv->bus->match所指向的函数。platform_driver_register函数中drv->driver.bus = &platform_bus_type,所以drv->bus->match就为platform_bus_type→match,为platform_match函数,该函数如下:
static int platform_match(struct device * dev, struct device_driver * drv)
{
struct platform_device *pdev = container_of(dev, struct platform_device, dev);
return (strncmp(pdev->name, drv->name, BUS_ID_SIZE) == 0);
}
是比较dev和drv的name,相同则会进入really_probe()函数,从而进入自己写的probe函数做进一步的匹配。所以dev→name和driver→drv→name在初始化时一定要填一样的。
不同类型的驱动,其match函数是不一样的,这个platform的驱动,比较的是dev和drv的名字,还记得usb类驱动里的match吗?它比较的是Product ID和Vendor ID。
个人总结Platform机制的好处:
1、提供platform_bus_type类型的总线,把那些不是总线型的soc设备都添加到这条虚拟总线上。使得,总线——设备——驱动的模式可以得到普及。
2、提供platform_device和platform_driver类型的数据结构,将传统的device和driver数据结构嵌入其中,并且加入resource成员,以便于和Open Firmware这种动态传递设备资源的新型bootloader和kernel 接轨。
Linux内核体系结构
因为Linux内核是单片的,所以它比其他类型的内核占用空间最大,复杂度也最高。这是一个设计特性,在Linux早期引起了相当多的争论,并且仍然带有一些与单内核固有的相同的设计缺陷。
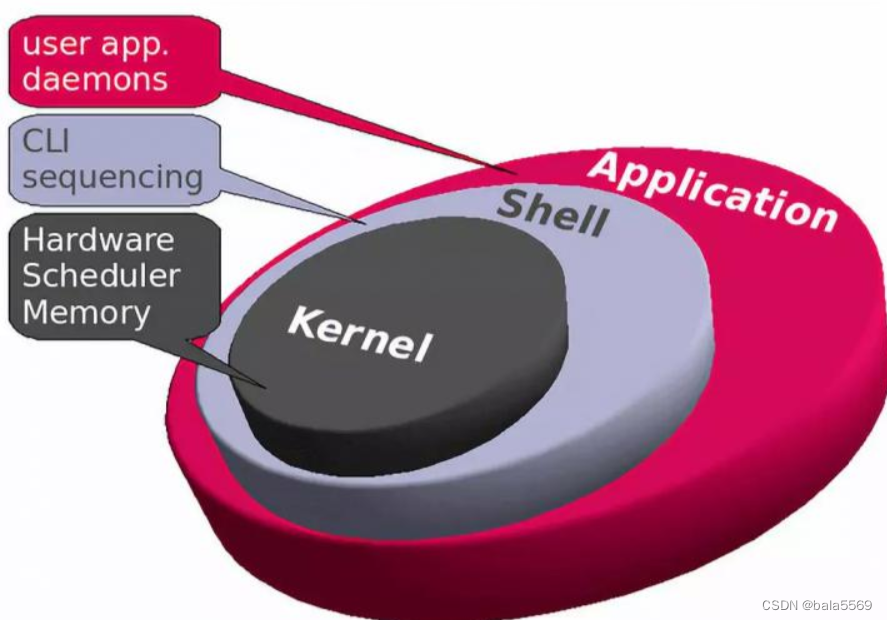
为了解决这些缺陷,Linux内核开发人员所做的一件事就是使内核模块可以在运行时加载和卸载,这意味着您可以动态地添加或删除内核的特性。这不仅可以向内核添加硬件功能,还可以包括运行服务器进程的模块,比如低级别虚拟化,但也可以替换整个内核,而不需要在某些情况下重启计算机。
想象一下,如果您可以升级到Windows服务包,而不需要重新启动……
内核模块
如果Windows已经安装了所有可用的驱动程序,而您只需要打开所需的驱动程序怎么办?这本质上就是内核模块为Linux所做的。内核模块,也称为可加载内核模块(LKM),对于保持内核在不消耗所有可用内存的情况下与所有硬件一起工作是必不可少的。
模块通常向基本内核添加设备、文件系统和系统调用等功能。lkm的文件扩展名是.ko,通常存储在/lib/modules目录中。由于模块的特性,您可以通过在启动时使用menuconfig命令将模块设置为load或not load,或者通过编辑/boot/config文件,或者使用modprobe命令动态地加载和卸载模块,轻松定制内核。
第三方和封闭源码模块在一些发行版中是可用的,比如Ubuntu,默认情况下可能无法安装,因为这些模块的源代码是不可用的。该软件的开发人员(即nVidia、ATI等)不提供源代码,而是构建自己的模块并编译所需的.ko文件以便分发。虽然这些模块像beer一样是免费的,但它们不像speech那样是免费的,因此不包括在一些发行版中,因为维护人员认为它通过提供非免费软件“污染”了内核。
内核并不神奇,但对于任何正常运行的计算机来说,它都是必不可少的。Linux内核不同于OS X和Windows,因为它包含内核级别的驱动程序,并使许多东西“开箱即用”。希望您能对软件和硬件如何协同工作以及启动计算机所需的文件有更多的了解。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【JaveWeb教程】(7)Web前端基础:Vue组件库Element介绍与快速入门程序编写并运行 示例
- Go语言增量式学习3
- 根据配置动态加载三方多数据源,支持热加载
- SQL_DQL_执行顺序
- 用友畅捷通T+安装操作手册
- 基于SpringBoot的流浪宠物求助管理系统的设计与实现-计算机毕业设计源码55366
- C语言 用三种方法求一个整数二进制位中1的个数
- 配网故障定位装置:让电力故障无所遁形
- 经典算法-遗传算法的解走迷宫例子
- 4.3 C++对象模型和this指针