【王爽老师汇编语言】os和计组必备前置知识-学习记录1
发布时间:2023年12月26日
环境配置
- 用vscode搭建汇编环境
ref:https://blog.csdn.net/xiao_yi_xiao/article/details/124199586
跑一个demo
assume cs:zs
zs segment
mov ax,2000H
mov ds,ax
mov bx,1000H
mov ax,[bx]
inc bx
inc ax
mov [bx],ax
mov ax,4c00H
int 21H
zs ends
end
出现右侧表示成功!
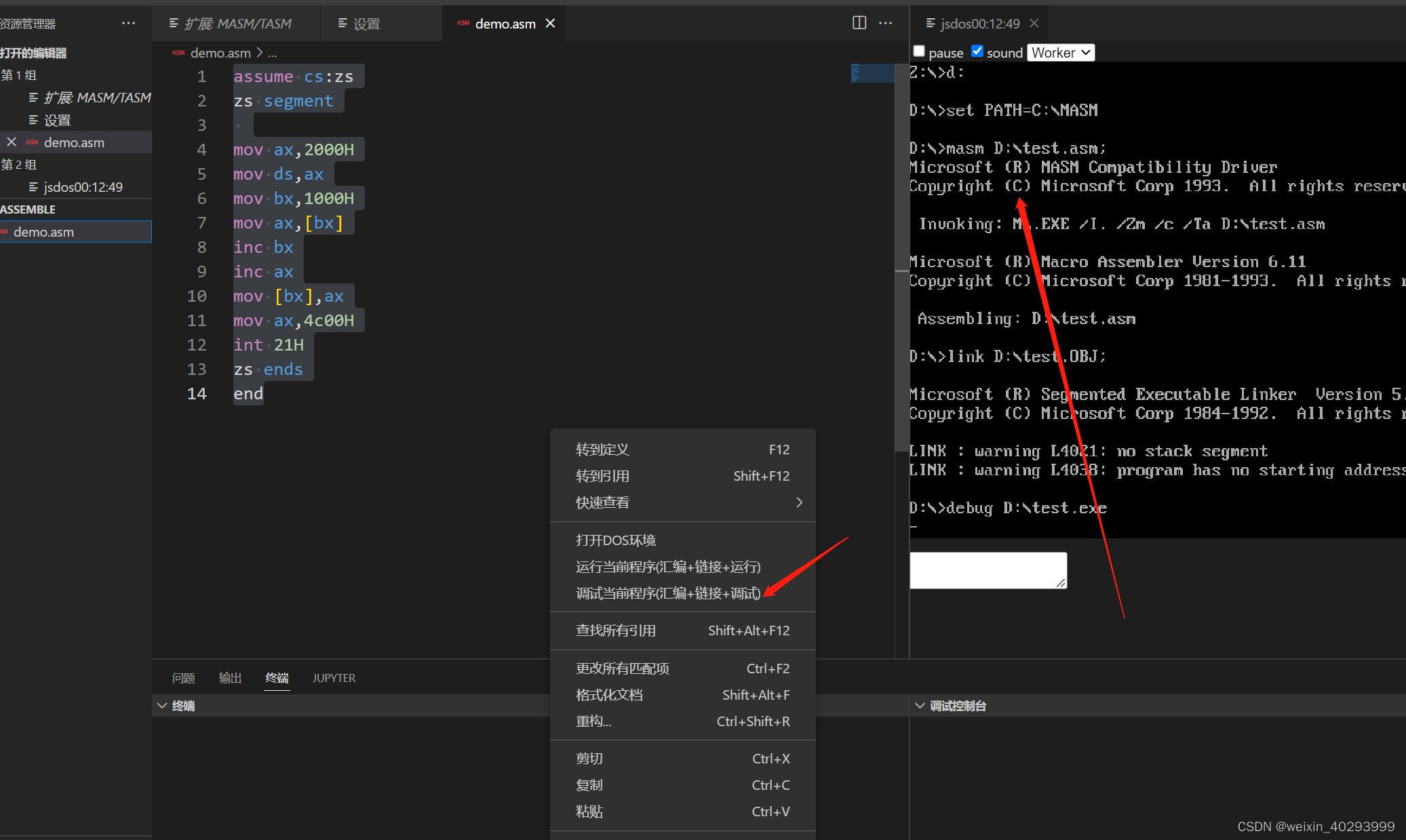
- DosBox
双击图标 挂载
mount c d:\masm
# 回到c盘 此时实际是在d:\masm下

访问寄存器和内存

对应王爽老师的第二章和第三章,比如0305 关于“段”的总结是3章的5节

vim p4-1.asm
assume cs:codesg
codesg segment
mov ax, 0123H
mov bx, 0456H
add ax, bx
add ax, ax
mov ax, 4c00h
int 21h
codesg ends
end
masm p4-1.asm
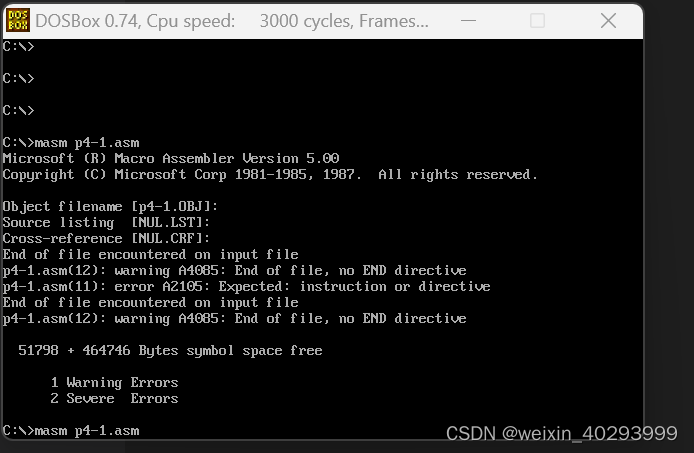
生成了p4-1.obj 目标文件 .LST 中间文件 和交叉引用文件(.CRF)同
列表文件一样,是编译器将源程序编译为目标文件过程中产生的中间结果。
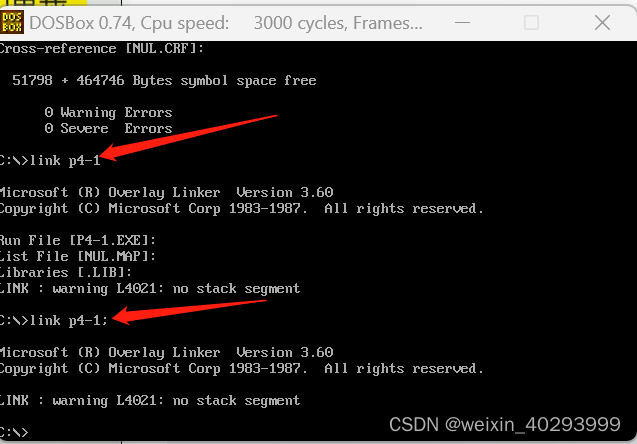
link xxx;分号可以简化链接过程
debug过程中
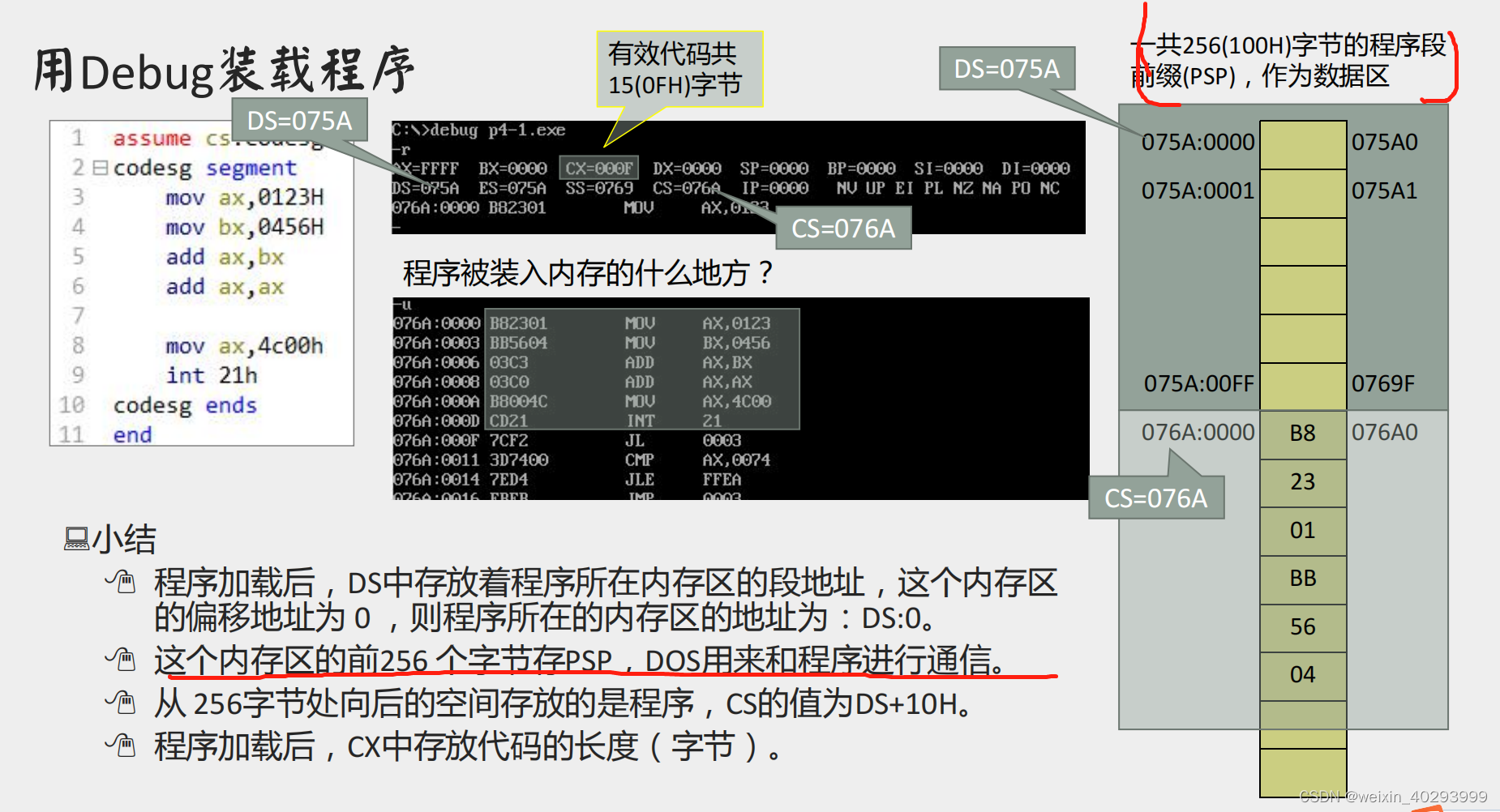
汇编语言中对PSP区和程序区的一些理解,看王爽《汇编语言(第三版)》的时候,第4.9章 有一处我一直无法理解
PSP区和程序区虽然物理地址相连,却又不同的段地址。
一开始我死活想不通这句话是什么意思,找了百度百科也没解释清楚。后来看到一个网友的回答,瞬间就想明白了,但是他表达的意思可能还是有点隐晦难懂,所以我在这里试着能不能解释得更通俗易懂一点。
书中在讲PSP区时提到:
从这段内存区的256字节处开始(在PSP的后面),将程序装入,程序的地址被设为SA+10H : 0;
……
所以,有了这样的地址安排:
空闲内存区: SA : 0
PSP区: SA : 0
程序区: SA+10H : 0
这里的关键就是为什么256字节和10H(即16)扯上了关系?难道不是应该和100H(即256)有关么?你说对了,就应该和100H有关,那怎么样能让它们扯上关系呢?不知道这个公式大家还记不记得:
物理地址=段地址×10H+偏移地址
明白了吧?PSP区的物理地址就是SA×10H,程序区的物理地址就是(SA+10H)×10H,即SA×10H+100H,刚好比PSP高了100H(即256)个字节。其实就是把偏移地址本来应该负责的100H的偏移量转移到了段地址上面,这样就能尽可能扩充程序区的大小了。
所以我们可以看出来,其实上面这个公式相当重要,它贯穿了全书,在不同的章节看到它都会有不同的体会,掌握它也会让我们更加容易地理解很多问题。
文章来源:https://blog.csdn.net/weixin_40293999/article/details/135211612
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SQL Yog 连接MySQL的时候出现 错误码 2058的问题
- 暗藏危险,警惕钓鱼邮件!
- 4、内网安全-隧道&内网穿透上线&Ngrok&FRP&NPS&SPP&EW项目
- STL之stack
- python&Pandas六:时间序列数据处理
- 20231227在Firefly的AIO-3399J开发板的Android11的挖掘机的DTS配置单后摄像头ov13850
- parser
- 利用 Python 进行数据分析实验(七)
- 2023年值得推荐的免费AI艺术生成器
- PC+Wap仿土巴兔装修报价器源码 PHP源码