书生·浦语大模型--第一节课
发布时间:2024年01月09日
目标:掌握大语言模型开发和应用技能
引言
大语言模型成为学术界和工业界的热门话题。
起源于2018年的GPT-1。
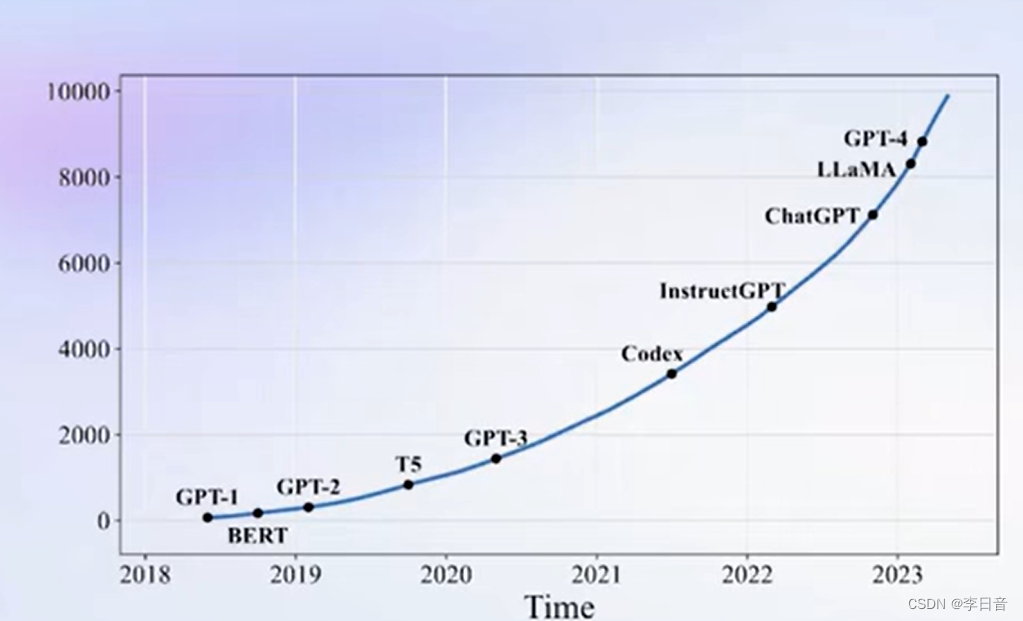
大模型是发展通用人工智能的重要途径,可以应对多任务、多模态。
书生·浦语大模型
发展历程
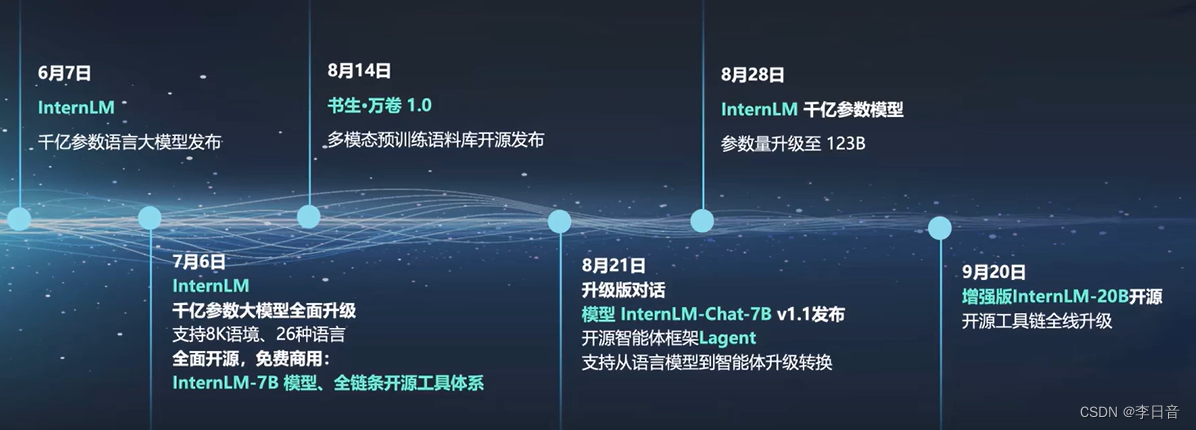
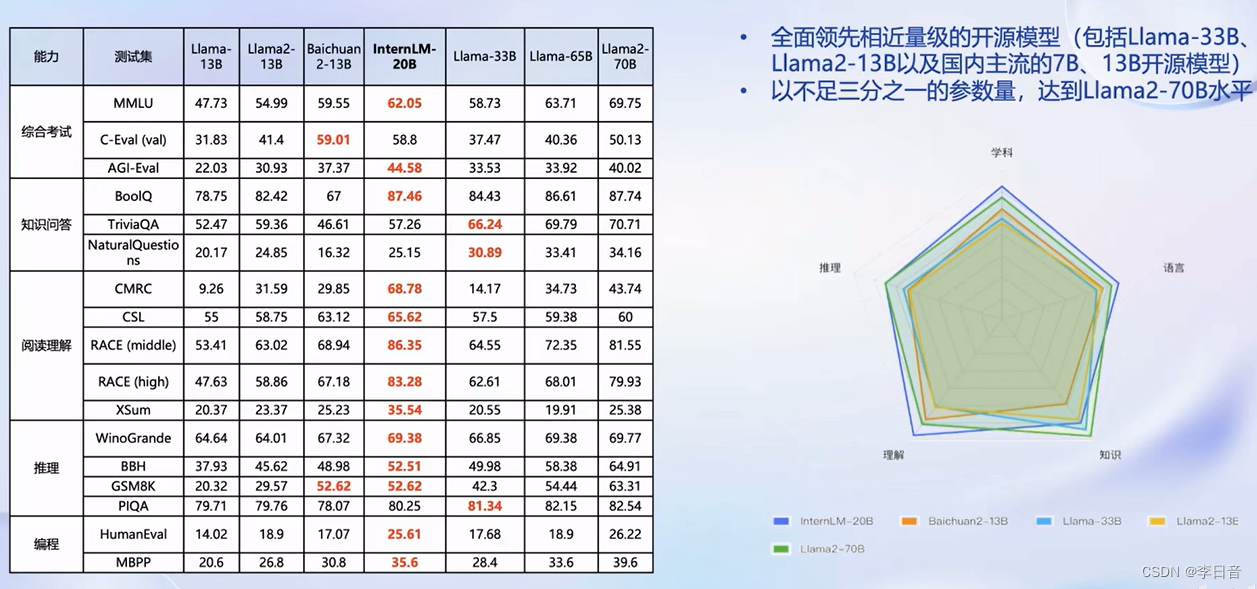
覆盖轻量级、中量级、重量级的应用。7B、20B已开源可用

20B性能比较,值得一提的是参数量小,可以达到Llama2-70B水平
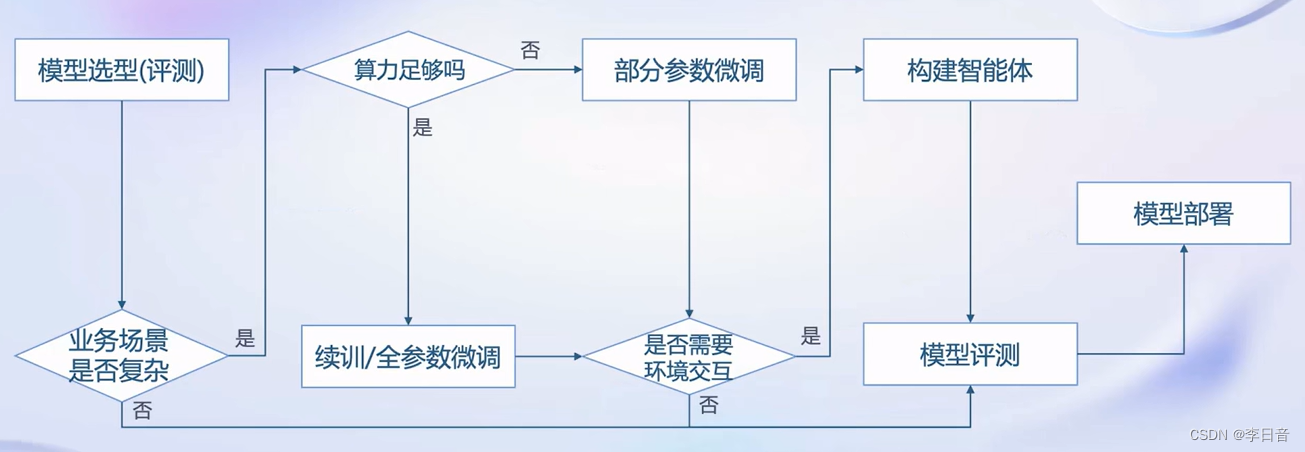
大模型的应用
需要考虑业务场景、算力、环境交互的因素
模型部署:更少的资源、提升吞吐量
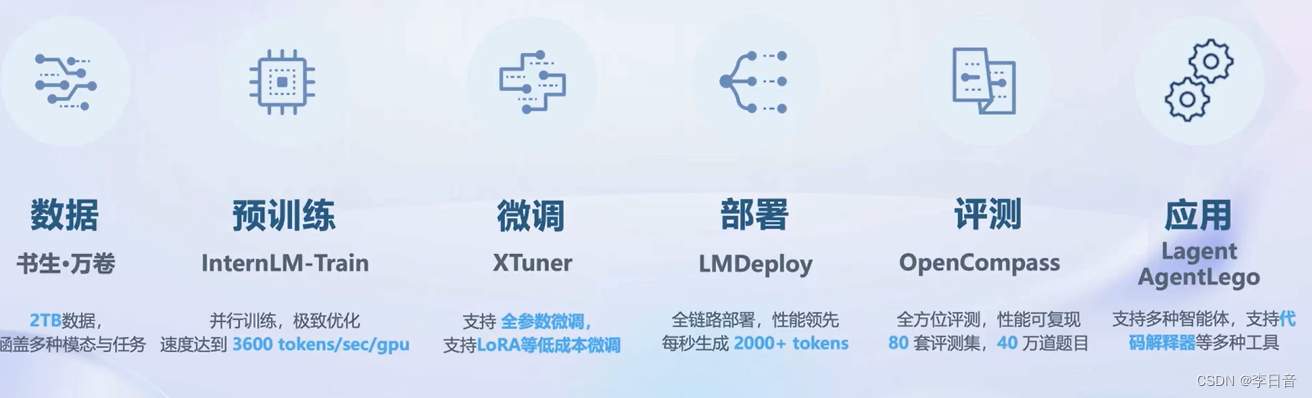
全链条开放体系
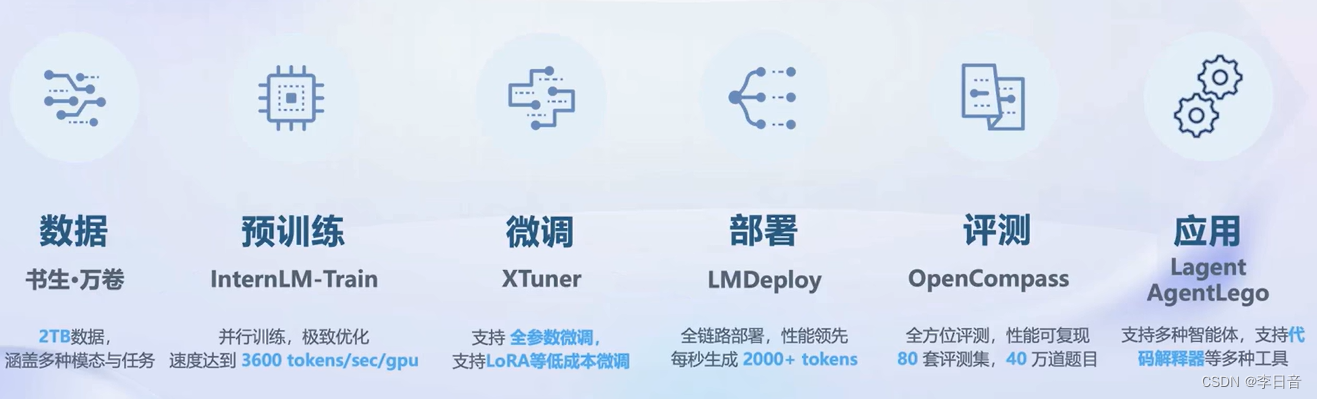
数据开源
涵盖不同领域,包含积累的技术和数据。对齐中国主流价值观

开放的数据平台

预训练工具

微调
增量续训和有监督微调。
增量续训:垂直领域、文章、数据、代码
有监督微调:数据量更少
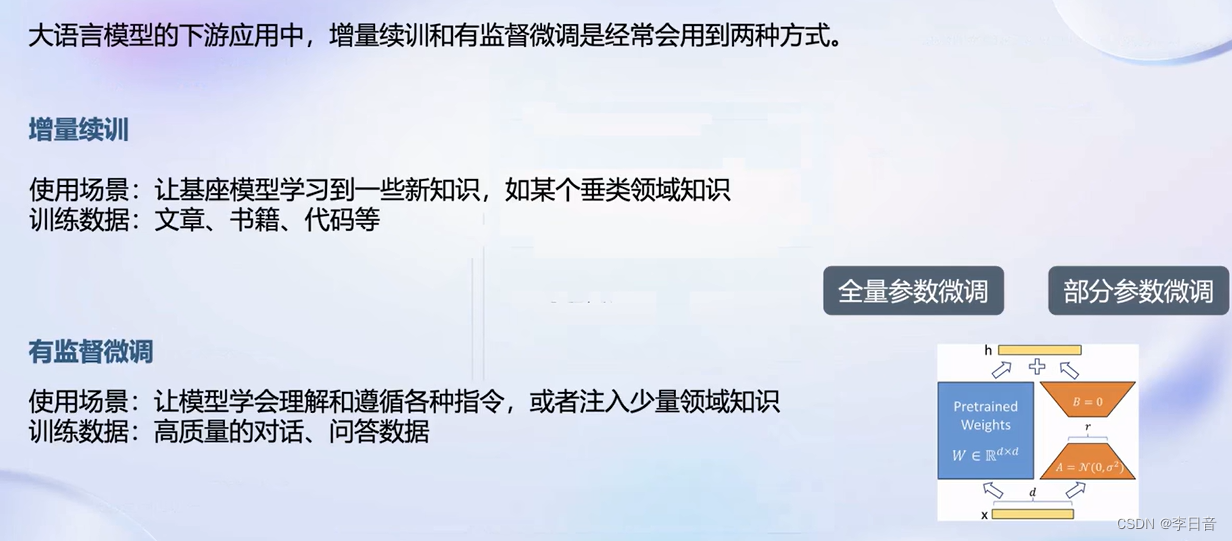
微调框架
只需要8G显存即可训练。第一个可以做到8G显卡训练。
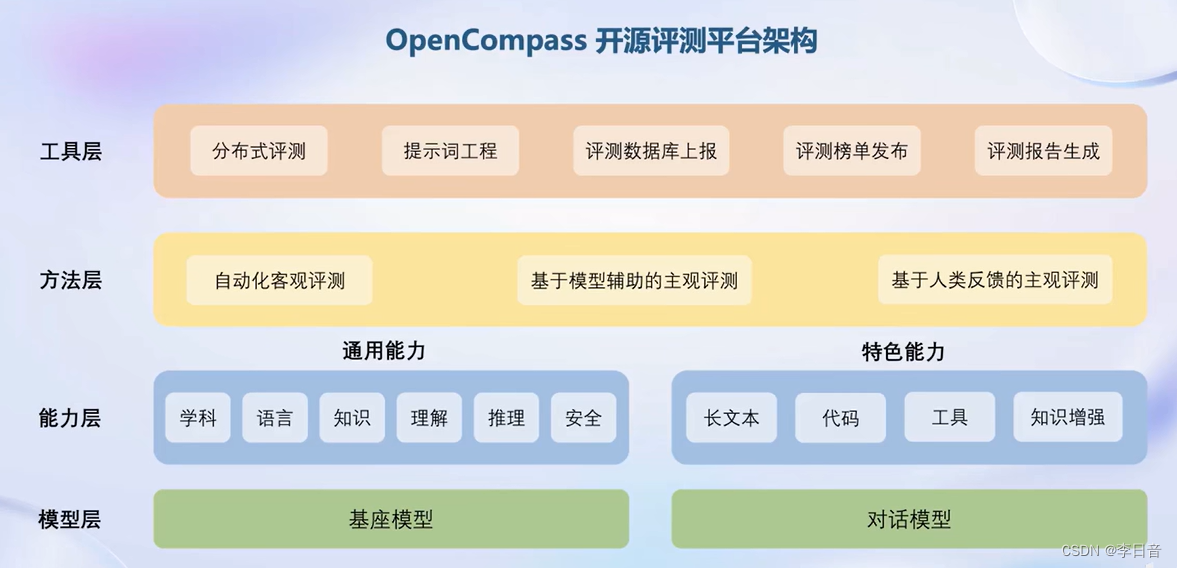
评测工具
主要还是考试做题,全面性不够

大维度评测,更全面

评测架构
优势:

部署:
参数巨大、内存开销

开源部署框架:全流程解决方案

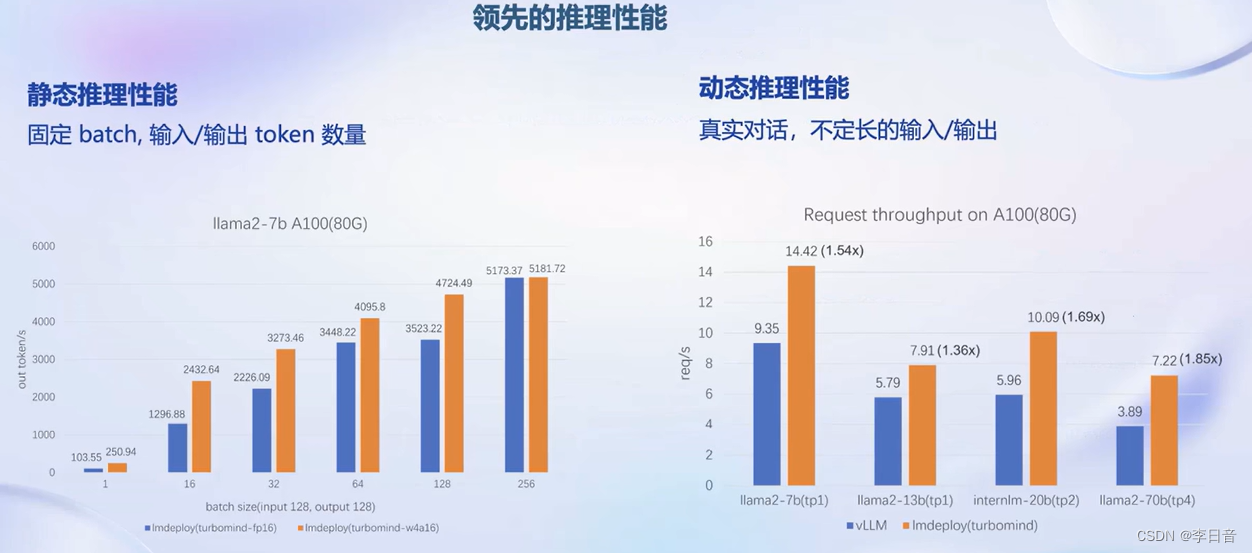
性能
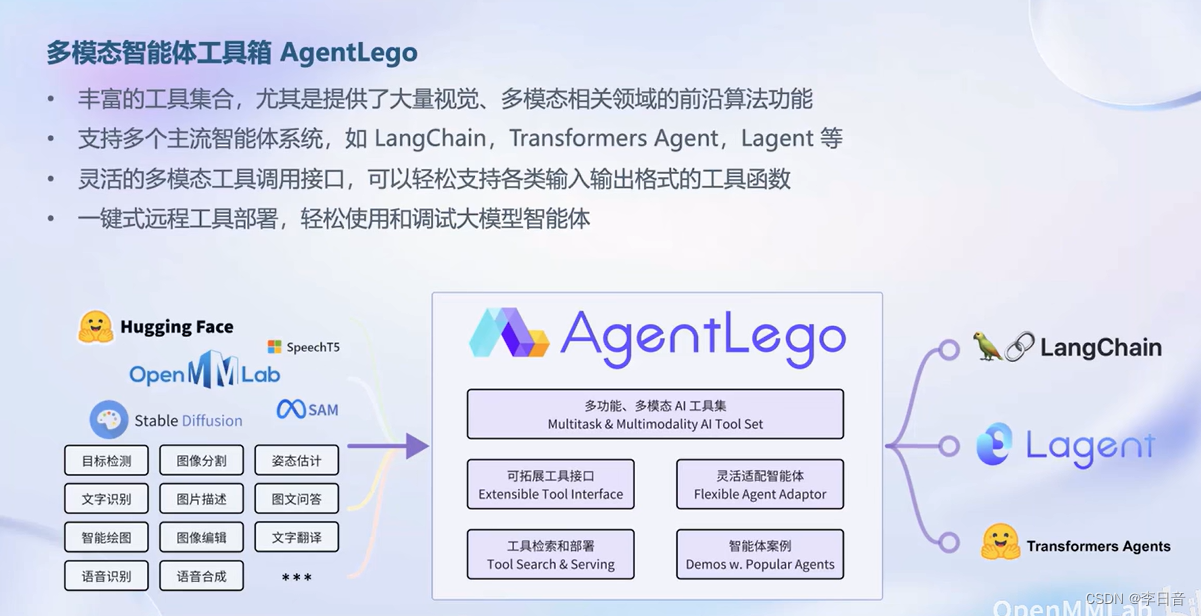
智能体应用
局限性:
- 最新信息和知识的获取
- 回复的可靠性
- 数学计算
- 工具使用和交互
框架

工具箱
提供工具集合
总结
参考链接
文章来源:https://blog.csdn.net/lalala12ll/article/details/135487885
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 透明OLED屏技术:开启全新视觉体验
- MyBatis XML 映射文件中的 SQL 语句可以分为动态语句和静态语句
- YYYY-MM-dd 与 yyyy-MM-dd 的区别
- C++11新特性:模板函数的默认模板参数
- 深入理解零拷贝技术
- 用Scala采集文库公开资料 一键搞定千万文章收集
- Jenkins自动化构建打包,部署
- Android MediaCodec 硬编码 H264 文件
- 12.1、2、3-同步状态机的结构以及Mealy和Moore状态机的区别
- DNS(域名系统)