LLM之RAG实战(十八)| 使用Query转换来改进RAG效果
?? ? ? ?在本文中,我们将分析查询转换,以及如何使用路由器根据输入提示选择适当的转换。
? ? ? ?查询转换背后的想法是,检索器有可能从数据库中检索到与用户初始提示不相关的块。在这些情况下,我们可以在检索并将其提供给语言模型之前,修改查询以增加其与源的相关性。
? ? ? ?我们将从一个简单的RAG应用程序开始,首先加载关于尼古拉斯·凯奇、《最好的时代》(尼古拉斯·凯吉首次登台表演的电视试播)和莱昂纳多·迪卡普里奥的三个维基百科页面数据。
? ? ? ?然后,我们将把文档分割成256个字符的块,没有重叠。这些块将嵌入并索引在Vector Store中,默认情况下,Vector Store将所有内容存储在内存中。
WikipediaReader = download_loader("WikipediaReader")?loader = WikipediaReader()pages = ['Nicolas_Cage', 'The_Best_of_Times_(1981_film)', 'Leonardo DiCaprio']documents = loader.load_data(pages=pages, auto_suggest=False, redirect = False)?llm = OpenAI(temperature=0, model="gpt-3.5-turbo")gpt3 = OpenAI(temperature=0, model="text-davinci-003")?embed_model = OpenAIEmbedding(model= OpenAIEmbeddingModelType.TEXT_EMBED_ADA_002)service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 256, chunk_overlap=0, embed_model=embed_model)?index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)retriever = index.as_retriever(similarity_top_k=3)
? ? ? ?现在,我们必须确保模型只根据上下文进行回答,而不依赖于其训练数据,即使它以前可能已经学会了答案。
# The response from original promptfrom llama_index.prompts import PromptTemplate?template = ("We have provided context information below. \n""---------------------\n""{context_str}""\n---------------------\n""Given this information, please answer the question: {query_str}\n""Don't give an answer unless it is supported by the context above.\n")?qa_template = PromptTemplate(template)
? ? ? ?我们将使用两个更复杂的查询来测试刚刚创建的RAG应用程序。让我们来看看第一个。
问题1——“Who directed the pilot that marked the acting debut of Nicolas Cage?”
? ? ? ?该查询的问题需要参考多条信息:尼古拉斯·凯奇的表演处女作和这部电影的导演。提示中只提到了尼古拉斯·凯奇,而导演的名字却没有被涉及。由于该模型不知道凯奇首次亮相的电视试播节目《最好的时代》的名字,因此无法从我们索引的文件中检索到相关细节。
question = "Who directed the pilot that marked the acting debut of Nicolas Cage?"?contexts = retriever.retrieve(question)context_list = [n.get_content() for n in contexts]?prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)response = llm.complete(prompt)?print(str(response))

问题2——“Compare the education received by Nicolas Cage and Leonardo DiCaprio.”
? ? ? ?对于该查询,检索器只选择有关莱昂纳多·迪卡普里奥教育的相关文本块,而尼古拉斯·凯奇的块内容是不相关的,因此无法进行准确的比较。
question = "Compare the education received by Nicolas Cage and Leonardo DiCaprio."?contexts = retriever.retrieve(question)?context_list = [n.get_content() for n in contexts]?prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)?response = llm.complete(prompt)print(str(response))

? ? ? ?让我们分析一些查询转换技术,看看哪种技术在不同情况下效果最好。
一、HyDE
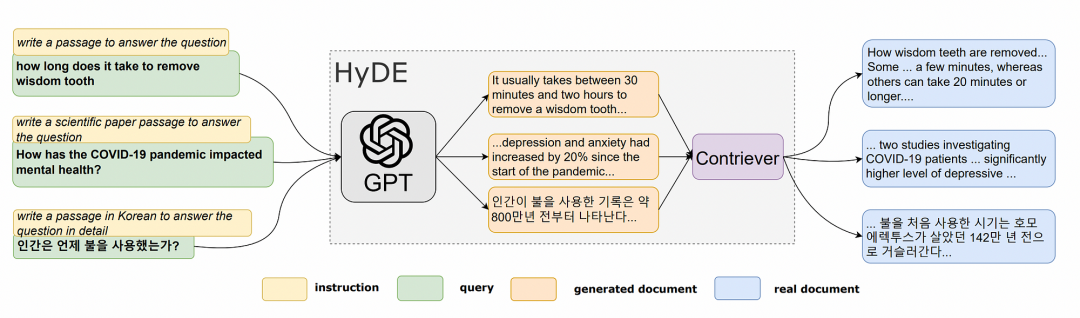
? ? ? ?Hypothetical Document Embeddings(HyDE)是一种生成文档嵌入以检索相关文档而不需要实际训练数据的技术。首先,LLM创建一个假设答案来响应查询。虽然这个答案反映了与查询相关的模式,但它包含的信息可能在事实上并不准确。
? ? ? ?接下来,查询和生成的答案都被转换为嵌入。然后,系统从预定义的数据库中识别并检索在向量空间中最接近这些嵌入的实际文档。
from llama_index.indices.query.query_transform import HyDEQueryTransformfrom llama_index.query_engine.transform_query_engine import (TransformQueryEngine,)?index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)query_engine = index.as_query_engine(similarity_top_k=3)?hyde = HyDEQueryTransform(include_original=True)hyde_query_engine = TransformQueryEngine(query_engine, hyde)
查询1
response = hyde_query_engine.query("Who directed the pilot that marked the acting debut of Nicolas Cage?")print(response)

? ? ? ?我们已经取得了部分进展——模型的答案仍然不正确,但它已经接近正确响应了。具体来说,它现在能够识别电视试播的名字(“Best of Times”)。让我们看看产生幻觉的答案是什么样子的。
query_bundle = hyde("Who directed the pilot that marked the acting debut of Nicolas Cage?")hyde_doc = query_bundle.embedding_strs[0]hyde_doc

? ? ? ?虽然弗朗西斯·科波拉执导的《The?Best of Times》不是真的,但至少幻觉中包括了电影的名字。
查询2
response = hyde_query_engine.query("Compare the education received by Nicolas Cage and Leonardo DiCaprio.")print(response)

? ? ? ?答案是正确的,因为产生幻觉的答案改善了输出。LLM在训练数据中已经包含了演员的教育信息。

二、子问题
? ? ? ?子问题技术使用分而治之的方法来处理复杂的问题。它首先分析问题,并将其分解为更简单的子问题,每个子问题会从提供部分答案的相关文件抽取答案。然后,收集这些中间结果,并将所有部分结果合成为最终响应。
# setup base query engine as toolquery_engine_tools = [QueryEngineTool(query_engine=vector_query_engine,metadata=ToolMetadata(name="Sub-question query engine",description="Questions about actors",),),]?query_engine = SubQuestionQueryEngine.from_defaults(query_engine_tools=query_engine_tools,service_context=service_context,use_async= False)
查询1


? ? ? ?通常会把问题分解成更简单的子问题,这样更容易回答。该模型试图生成一个子问题,但除了原始查询之外,没有提供任何额外的上下文,从而将计算浪费在无效的转换上。
查询2


? ? ? ?这一次,生成子问题非常有用,因为我们需要比较两条不同的信息——两个不同的人的教育背景,每个子问题都可以使用检索到的上下文独立回答。
三、多步骤查询转换

? ? ? ?多步骤查询转换方法基于自询问方法,即语言模型在回答原始问题之前向自己询问并回答后续问题,这有助于模型将其在预训练过程中分别学习到的事实和见解结合起来。
? ? ? ?最初的论文表明,LLM往往无法将两个事实组合在一起,即使它们独立地知道每一个事实。例如,一个模型可能知道事实a和事实B,但无法一起推导出a和B的含义。
? ? ? ?自我询问的方法旨在克服这一限制。在测试时,我们只需向模型提供提示和问题,它就会自动生成必要的后续问题,以连接事实,组成推理步骤,并决定何时停止。
query_engine = MultiStepQueryEngine(query_engine=query_engine,query_transform=step_decompose_transform_gpt3,index_summary=index_summary)
查询1
Don Mischer directed the pilot that marked the acting debut of Nicolas Cage
? ? ? 这是我们第一次对这个问题有正确的答案!让我们看看中间的问题。

? ? ? ?第一个子问题的产出如下:
The Best of Times pilot that marked the acting debut of Nicolas Cage was not directed by anyone in the Coppola family. It was directed by Rod Amateau.
? ? ? ?在确定了pilot的名字后,第二个子问题具体询问有关导演的问题:
Who directed the Best of Times pilot that marked the acting debut of Nicolas Cage?
? ? ? ?这种多步骤的方法有助于模型建立在先前问题的额外背景之上,并引导我们找到正确的答案。
查询2
? ? ? ?尼古拉斯·凯奇在加州大学洛杉矶分校戏剧电影电视学院接受戏剧、电影和电视领域的教育。另一方面,莱昂纳多·迪卡普里奥就读于洛杉矶强化研究中心、种子小学和约翰·马歇尔高中。然而,迪卡普里奥高中辍学,后来获得了普通同等学历文凭。

? ? ? 在这种情况下,多步骤方法也很有用。我们的观点是,对于第二个查询,以前的子问题技术更适合,因为它可以并行化。这些问题是独立的,不需要建立在彼此之上。但是,多步骤的方法也是有用的。
四、路由器查询引擎
? ? ? ?事实证明,每个查询转换都适用于不同的情况。子问题分解最适用于可以分解为更简单的子问题的问题,例如比较尼古拉斯·凯奇和莱昂纳多·迪卡普里奥的教育。
? ? ? ?多步骤转换最适用于需要迭代探索上下文的查询,如链接信息的多个方面。
? ? ? ? 简单的查询可能根本不需要任何转换,应用它们将浪费资源。
? ? ? 为了在所有这些情况之间进行选择,我们可以使用RouterQueryEngine——我们为LLM提供了一组用于查询转换的工具,并让它根据输入提示来决定应用的最佳工具。
query_engine = RouterQueryEngine(selector=PydanticSingleSelector.from_defaults(),query_engine_tools=[simple_tool,multi_step_tool,sub_question_tool,],)
? ? ? ?我们创建了一个路由器,允许根据每个唯一查询的需要在无转换、子问题分解或多步骤转换之间进行选择。让我们来看看路由器是如何决定采取哪种方法的。
? ? ? ?首先,我们将选择一个不需要转换的非常简单的问题。
response_1 = query_engine.query("What is Nicolas Cage's profession?")
? ? ? ?路由器通过评估查询相对简单,做出了正确的选择。不需要查询转换来分解或扩展这个问题,因为它直接询问关于Nicolas Cage职业的单个事实。
response_2 = query_engine.query("Compare the education received by Nicolas Cage and Leonardo DiCaprio.")
? ? ? ?为了回答一个比较问题,路由器准确地将其分解为关于每个人的更简单的子问题。
response_3 = query_engine.query("Who directed the pilot that marked the acting debut of Nicolas Cage?")?

? ? ? ?对于第三个查询,路由器识别出正确回答需要链接多条上下文信息——具体来说,识别标志着凯奇首次表演的试播集,然后确定是谁导演了那个特定的试播。
五、结论
? ? ? ?如上述探索,通过高级查询转换增强RAG可以显著提高模型性能。
? ? ? ?查询转换是一种改进检索的技术,但它展示了将检索与LLM固有的推理能力相结合的定制分析的潜力和需求。
参考文献:
[1]?https://towardsdatascience.com/advanced-query-transformations-to-improve-rag-11adca9b19d1
[2]?https://arxiv.org/abs/2210.03350
[3]?https://arxiv.org/abs/2307.03172
[4]?https://arxiv.org/abs/2212.10496
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 20240102-持续低物欲
- 数据缓存(Redis, Spring Cache)——后端
- Unity-Shader-渲染队列,ZTest,ZWrite
- DockerCompose安装mysql及配置
- 闲聊软件项目实施失败的可能原因
- Java超高精度无线定位技术--UWB (超宽带)人员定位系统源码
- Unity VR Pico apk安装失败:INSTALL_FAILED_UPDATE_INCOMPATIBLE
- } expected.Vetur(1005)
- 探索世界,从一款好用的浏览器开始!
- 算法训练营day42(动态规划4)难点