Python中通过selenium简单操作及元素定位知识点总结
|
|
selenium的8种定位方式
6种靠单一的特征来找元素(id, calss_name, tag_name, name, link_text(2))
组合各种特征和关系来找元素(xpath, css)
1.id定位:唯一
find_element_by_id()
2.name定位:不唯一
find_element_by_name()
find_elements_by_name()
3.class定位:不唯一
find_element_by_class()
4.tag_name定位:不唯一
find_element_by_tag_name() # 单数,在DOM页面中,匹配到的第一个元素
find_elements_by_tag_name() # 复数,返回的是一个列表,元素为webElement对象,全部匹配的元素
5.文本匹配:/完全匹配/部分匹配
find_element_by_link_text()
find_element_by_partial_link_text()
Xpath定位:
1.通过自己来定位:
语法://标签名[@属性名=值]
例如:
//*[@id="mCon"]/span # *匹配所有元素
//*[@id="kw"]
2.通过文本来定位:
语法://标签名[text()="值"]
例如:
//h1[(text()= "第20期")] # 完全匹配
//h1[contains(text(), "第20期")] # 部分匹配,包含
3.层级定位:
如果找到的元素有两个或多个完全一样的元素,那么就通过他们不同的父级或父级的父级来定位
/ 绝对定位,单斜杠只能写子级,不能跳级写
// 相对定位,双斜杠可以写子级,子级的子级等等(推荐使用)
举例说明:
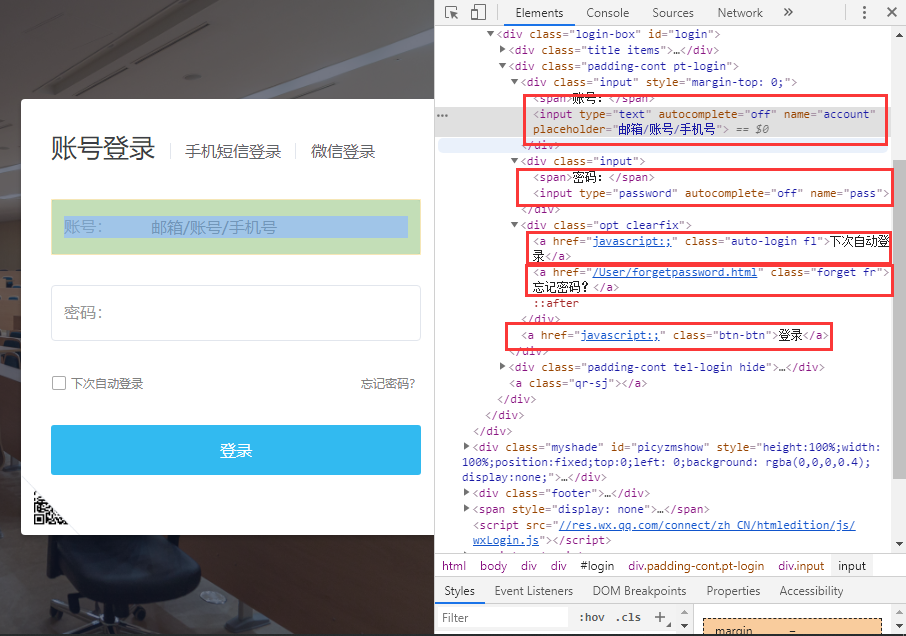
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
Xpath轴定位:
含义:通过同级目录来定位元素,叫做轴定位
轴运算:
ancestor:祖先节点,包括父节点
parent:父节点
preceding-sibling:当前元素节点标签之前的所有兄弟节点
following-sibling:当前元素节点标签之后的所有兄弟节点
preceding:当前元素节点标签之前的所有节点(HTML页面先后顺序)
following:当前元素节点标签之后所有的节点(HTML页面先后顺序)
轴定位语法:
/轴名称::标签名称[@属性名=值]
示例:例://div//table//td//preceding::td
应用场景:
页面显示为一个表格样式的数据列,需要通过组合来定位元素
以上就是本次介绍的全部知识点内容,感谢大家对脚本之家的支持。
?现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!?希望能帮助到你!【100%无套路免费领取】

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!