工具系列:PyCaret介绍_Fugue 集成_Spark、Dask分布式训练
工具系列:PyCaret介绍_Fugue 集成_Spark、Dask分布式训练
Fugue 是一个低代码的统一接口,用于不同的计算框架,如 Spark、Dask。PyCaret 使用 Fugue 来支持分布式计算场景。
目录
1、分布式计算示例:
(1)分类
(2)回归
(3)时间序列
2、应用技巧
(1)在设置中使用lambda而不是dataframe
(2)保持确定性
(3)设置n_jobs
(4)设置适当的批量大小
(5)显示进度
(6)自定义指标
(7)Spark设置
(8)Dask设置
(9)本地并行化
(10)如何开发
1、分布式计算场景
(1)分类
让我们从最标准的例子开始,代码与本地版本完全相同,没有任何魔法。
# 导入所需的库
from pycaret.datasets import get_data # 导入获取数据的函数
from pycaret.classification import * # 导入分类模型
# 使用get_data函数获取名为"juice"的数据集,并设置verbose参数为False,表示不显示详细信息
data = get_data("juice", verbose=False)
# 设置目标变量为'Purchase',n_jobs参数为1表示使用单个进程
setup(data=data, target='Purchase', n_jobs=1)
# 获取前5个模型的名称,并存储在test_models变量中
test_models = models().index.tolist()[:5]
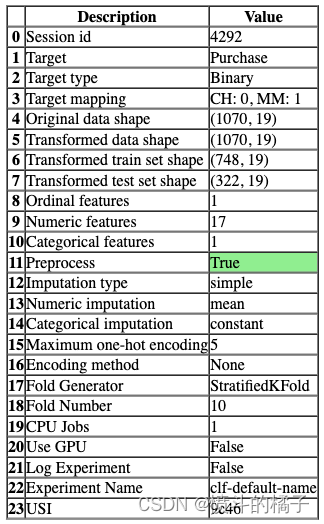
compare_model如果您不想使用分布式系统,也完全相同。
# 比较模型函数
compare_models(include=test_models, n_select=2)
Processing: 0%| | 0/26 [00:00<?, ?it/s]
[LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=4292, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=4292, splitter='best')]
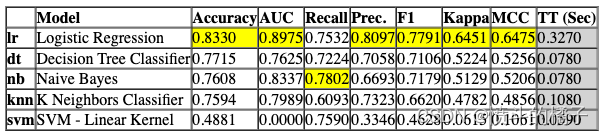
现在让我们将其分布式,作为一个玩具案例,在dask上。唯一改变的是一个额外的参数parallel_backend。
# 导入所需的库
from pycaret.parallel import FugueBackend
# 使用FugueBackend作为并行计算的后端
# compare_models函数用于比较多个模型的性能
# include参数指定要比较的模型列表
# n_select参数指定要选择的最佳模型数量
# parallel参数指定使用的并行计算后端,这里使用FugueBackend("dask")表示使用Dask作为并行计算后端
compare_models(include=test_models, n_select=2, parallel=FugueBackend("dask"))
[LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=4292, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=4292, splitter='best')]
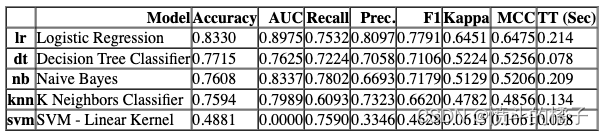
为了使用Spark作为执行引擎,您必须能够访问一个Spark集群,并且必须拥有一个SparkSession,让我们初始化一个本地的Spark会话。
# 导入SparkSession模块
from pyspark.sql import SparkSession
# 创建或获取SparkSession对象
spark = SparkSession.builder.getOrCreate()
现在只需将parallel_backend更改为此会话对象,即可在Spark上运行。您必须明白这只是一个玩具案例。在实际情况中,您需要拥有一个指向真实Spark集群的SparkSession,才能享受Spark的强大功能。
# 调用 compare_models 函数,传入参数 include=test_models、n_select=2 和 parallel=FugueBackend(spark)
compare_models(include=test_models, n_select=2, parallel=FugueBackend(spark))
[LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=4292, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=4292, splitter='best')]
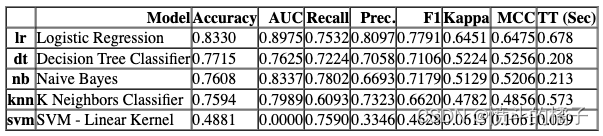
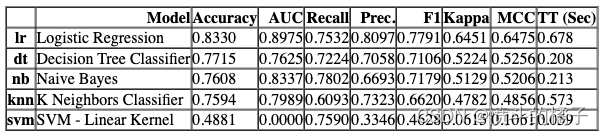
最后,你可以使用pull命令来获取指标表格。
pull()
(2)回归
回归问题与分类问题遵循相同的模式。
# 导入所需的库
from pycaret.datasets import get_data # 导入获取数据的函数
from pycaret.regression import * # 导入回归模型
# 设置数据和目标变量
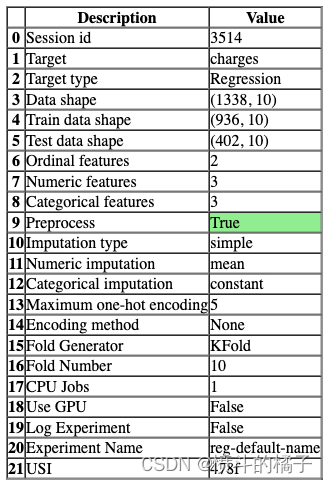
setup(data=get_data("insurance", verbose=False), target='charges', n_jobs=1)
# 获取前5个模型
test_models = models().index.tolist()[:5]
compare_model如果您不想使用分布式系统,也完全相同。
# 比较模型性能的函数
# 参数:
# include: 需要比较的模型列表
# n_select: 需要选择的模型数量
# sort: 按照哪个指标进行排序,默认为平均绝对误差(MAE)
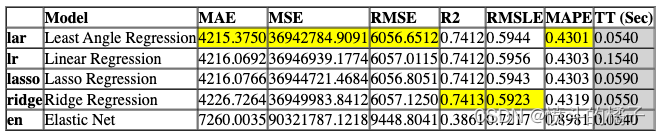
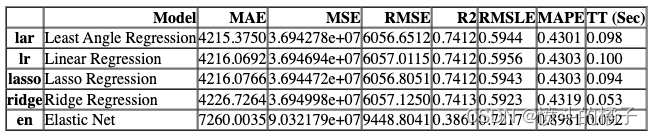
compare_models(include=test_models, n_select=2, sort="MAE")
Processing: 0%| | 0/26 [00:00<?, ?it/s]
[Lars(copy_X=True, eps=2.220446049250313e-16, fit_intercept=True, fit_path=True,
jitter=None, n_nonzero_coefs=500, normalize='deprecated',
precompute='auto', random_state=3514, verbose=False),
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1,
normalize='deprecated', positive=False)]
现在让我们将其分布式,作为一个玩具案例,在dask上。唯一改变的是一个额外的参数parallel_backend。
# 导入所需的库
from pycaret.parallel import FugueBackend
# 使用FugueBackend作为并行计算的后端
# compare_models函数用于比较多个模型的性能,并选择性能最好的几个模型
# include参数指定要比较的模型列表
# n_select参数指定要选择的模型数量
# sort参数指定按照哪个指标进行排序,这里选择按照平均绝对误差(MAE)进行排序
# parallel参数指定使用的并行计算后端,这里选择使用FugueBackend("dask")作为并行计算的后端
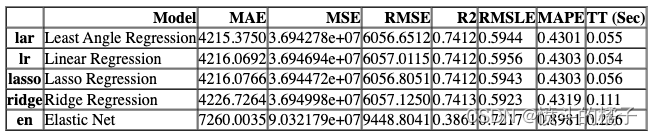
compare_models(include=test_models, n_select=2, sort="MAE", parallel=FugueBackend("dask"))
[Lars(copy_X=True, eps=2.220446049250313e-16, fit_intercept=True, fit_path=True,
jitter=None, n_nonzero_coefs=500, normalize='deprecated',
precompute='auto', random_state=3514, verbose=False),
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1,
normalize='deprecated', positive=False)]
为了使用Spark作为执行引擎,您必须能够访问一个Spark集群,并且必须拥有一个SparkSession,让我们初始化一个本地的Spark会话。
# 导入SparkSession模块
from pyspark.sql import SparkSession
# 创建或获取一个SparkSession对象
spark = SparkSession.builder.getOrCreate()
现在只需将parallel_backend更改为此会话对象,即可在Spark上运行。您必须明白这只是一个玩具案例。在真实情况下,您需要拥有一个指向真实Spark集群的SparkSession,才能享受Spark的强大功能。
# 调用compare_models函数,传入参数include=test_models、n_select=2、sort="MAE"和parallel=FugueBackend(spark)
compare_models(include=test_models, n_select=2, sort="MAE", parallel=FugueBackend(spark))
[Lars(copy_X=True, eps=2.220446049250313e-16, fit_intercept=True, fit_path=True,
jitter=None, n_nonzero_coefs=500, normalize='deprecated',
precompute='auto', random_state=3514, verbose=False),
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1,
normalize='deprecated', positive=False)]
最后,你可以使用pull命令来获取指标表格。
pull()
(3)时间序列
它遵循与分类相同的模式。
# 导入所需的库和模块
from pycaret.datasets import get_data # 导入获取数据的函数
from pycaret.time_series import * # 导入时间序列模块
# 创建时间序列预测实验对象
exp = TSForecastingExperiment()
# 设置实验参数
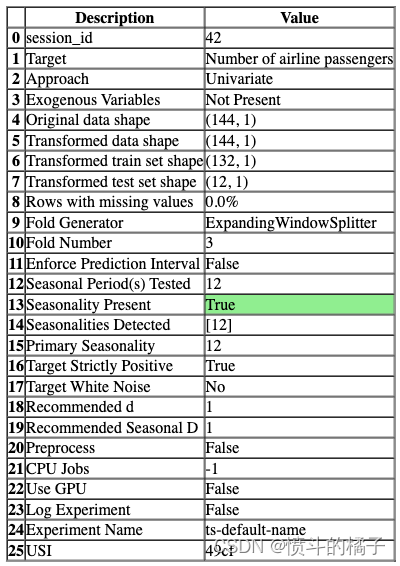
exp.setup(
data=get_data('airline', verbose=False), # 获取数据集,此处使用航空数据集
fh=12, # 设置预测的未来时间步数为12
fold=3, # 设置交叉验证的折数为3
fig_kwargs={'renderer': 'notebook'}, # 设置绘图参数,此处使用notebook作为渲染器
session_id=42 # 设置随机种子为42,保证实验的可重复性
)
# 获取前5个模型的名称
test_models = exp.models().index.tolist()[:5]
# 比较模型性能并选择最佳模型
# 使用exp.compare_models函数比较模型性能,并选择最佳的3个模型作为基准模型
# 参数include=test_models表示只比较test_models中的模型
# 参数n_select=3表示选择性能最好的3个模型作为最佳基准模型
best_baseline_models = exp.compare_models(include=test_models, n_select=3)
best_baseline_models

Processing: 0%| | 0/27 [00:00<?, ?it/s]
[ARIMA(maxiter=50, method='lbfgs', order=(1, 0, 0), out_of_sample_size=0,
scoring='mse', scoring_args=None, seasonal_order=(0, 1, 0, 12),
start_params=None, suppress_warnings=False, trend=None,
with_intercept=True),
NaiveForecaster(sp=12, strategy='last', window_length=None),
PolynomialTrendForecaster(degree=1, regressor=None, with_intercept=True)]
# 导入所需的模块
from pycaret.parallel import FugueBackend
# 使用FugueBackend作为并行计算的后端
# FugueBackend是一个用于分布式计算的后端,可以使用Dask或Ray来实现并行计算
# 这里使用了"Dask"作为FugueBackend的参数,表示使用Dask来进行并行计算
# 使用exp.compare_models函数比较模型性能,并选择最佳的3个模型
# include参数指定要比较的模型列表,test_models是一个包含待比较模型的列表
# n_select参数指定要选择的最佳模型的数量,这里选择了3个最佳模型
# parallel参数指定并行计算的后端,这里使用了之前创建的FugueBackend对象
# 将比较结果保存在best_baseline_models变量中,该变量将包含最佳的3个模型
best_baseline_models = exp.compare_models(include=test_models, n_select=3, parallel=FugueBackend("dask"))
best_baseline_models

[ARIMA(maxiter=50, method='lbfgs', order=(1, 0, 0), out_of_sample_size=0,
scoring='mse', scoring_args=None, seasonal_order=(0, 1, 0, 12),
start_params=None, suppress_warnings=False, trend=None,
with_intercept=True),
NaiveForecaster(sp=12, strategy='last', window_length=None),
PolynomialTrendForecaster(degree=1, regressor=None, with_intercept=True)]
# 导入SparkSession模块
from pyspark.sql import SparkSession
# 创建或获取SparkSession对象
spark = SparkSession.builder.getOrCreate()
# 导入所需的模块
from pycaret.parallel import FugueBackend
# 使用FugueBackend作为并行计算的后端
# 使用exp.compare_models函数来比较模型性能并选择最佳模型
# include参数指定要比较的模型列表,这里选择了test_models列表的前两个模型
# n_select参数指定要选择的最佳模型数量,这里选择了3个最佳模型
# parallel参数指定并行计算的后端,这里使用了FugueBackend(spark)
# 将比较结果保存在best_baseline_models变量中
best_baseline_models = exp.compare_models(include=test_models[:2], n_select=3, parallel=FugueBackend(spark))
best_baseline_models

[NaiveForecaster(sp=1, strategy='last', window_length=None),
NaiveForecaster(sp=1, strategy='mean', window_length=None)]
# 从exp对象中调用pull()方法
exp.pull()

2、分布式应用技巧
(1)一个更实际的案例
上面的例子都是纯粹的玩具,为了在分布式系统中使事情完美运行,你必须注意一些事情
(2) 在设置中使用lambda而不是dataframe
如果你直接在setup中提供一个dataframe,这个数据集将需要发送到所有的工作节点。如果dataframe是1G,你有100个工作节点,那么你的驱动机器可能需要发送高达100G的数据(取决于具体框架的实现),这个数据传输本身就成为了一个瓶颈。相反,如果你提供一个lambda函数,它不会改变本地计算的情况,但驱动程序只会将函数引用发送给工作节点,每个工作节点将负责自己加载数据,因此驱动程序端没有大量的流量。
(3) 保持确定性
你应该始终使用session_id来使分布式计算具有确定性。
(4) 设置n_jobs
在想要分布式运行某些任务时,明确设置n_jobs非常重要,这样它就不会过度使用本地/远程资源。这也可以避免资源争用,并加快计算速度。
# 导入所需的库
from pycaret.datasets import get_data # 导入获取数据的函数
from pycaret.classification import * # 导入分类模块
# 设置函数,用于获取数据
# 使用get_data函数获取名为"juice"的数据集,关闭冗长输出(verbose=False),关闭数据集的概要信息(profile=False)
# 设置目标变量为'Purchase'
# 设置会话ID为0,以确保结果的可重复性
# 设置使用的CPU核心数为1
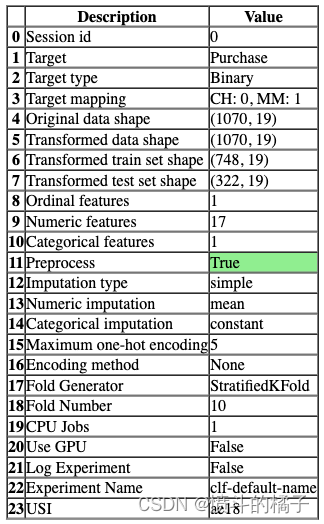
setup(data_func=lambda: get_data("juice", verbose=False, profile=False), target='Purchase', session_id=0, n_jobs=1);
(4)设置适当的批量大小
batch_size参数有助于在负载均衡和开销之间进行调整。对于每个批次,设置将只调用一次。所以
| 选择 | 负载均衡 | 开销 | 最佳情况 |
|---|---|---|---|
| 较小的批量大小 | 更好 | 更差 | 训练时间 >> 数据加载时间 或者 模型数量 ~= 工作进程数量 |
| 较大的批量大小 | 更差 | 更好 | 训练时间 << 数据加载时间 或者 模型数量 >> 工作进程数量 |
默认值设置为1,表示我们希望获得最佳的负载均衡。
(5) 显示进度
在开发中,您可以通过display_remote=True启用可视效果,但同时您还必须启用Fugue回调,以便驱动程序可以监视工作进度。但建议在生产环境中关闭显示。
# 导入所需的模块
from pycaret.parallel import FugueBackend
# 定义配置参数
fconf = {
"fugue.rpc.server": "fugue.rpc.flask.FlaskRPCServer", # 保持该值不变
"fugue.rpc.flask_server.host": "0.0.0.0", # 驱动程序的 IP 地址,工作节点可以访问
"fugue.rpc.flask_server.port": "3333", # 驱动程序上的开放端口
"fugue.rpc.flask_server.timeout": "2 sec", # 工作节点与驱动程序通信的超时时间
}
# 创建 FugueBackend 对象
be = FugueBackend("dask", fconf, display_remote=True, batch_size=3, top_only=False)
# 使用 FugueBackend 对象进行模型比较
compare_models(n_select=2, parallel=be)
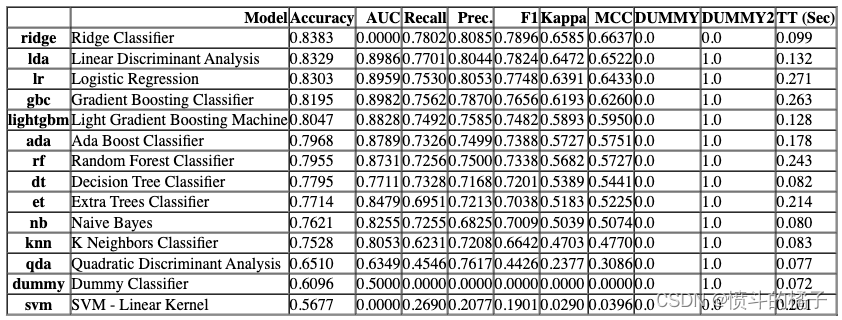
Processing: 0%| | 0/14 [00:00<?, ?it/s]
[RidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize='deprecated', positive=False,
random_state=0, solver='auto', tol=0.001),
LinearDiscriminantAnalysis(covariance_estimator=None, n_components=None,
priors=None, shrinkage=None, solver='svd',
store_covariance=False, tol=0.0001)]
(6)自定义指标
您可以像以前一样添加自定义指标。但是为了使评分器可分发,它必须是可序列化的。一个常见的函数应该没问题,但是如果在函数内部使用了一些不可序列化的全局变量(例如一个RLock对象),可能会引发问题。因此,请尽量使自定义函数独立于全局变量。
# 定义一个名为score_dummy的函数,用于计算模型的得分
# 参数y_true表示真实值,y_pred表示预测值,axis表示计算得分的轴
def score_dummy(y_true, y_pred, axis=0):
return 0.0
# 添加一个名为'mydummy'的指标
# 参数id表示指标的唯一标识符
# 参数name表示指标的名称
# 参数score_func表示计算指标得分的函数,这里使用之前定义的score_dummy函数
# 参数target表示指标的计算目标,这里是预测值
# 参数greater_is_better表示得分是否越大越好,这里设置为False,表示得分越小越好
add_metric(id='mydummy',
name='DUMMY',
score_func=score_dummy,
target='pred',
greater_is_better=False)
Name DUMMY
Display Name DUMMY
Score Function <function score_dummy at 0x7f8aa0dc0ca0>
Scorer make_scorer(score_dummy, greater_is_better=False)
Target pred
Args {}
Greater is Better False
Multiclass True
Custom True
Name: mydummy, dtype: object
在类实例中添加一个函数也是可以的,但是请确保类中的所有成员变量都是可序列化的。
# 获取模型列表的前5个模型
test_models = models().index.tolist()[:5]
# 比较模型
# include参数指定要比较的模型列表
# n_select参数指定要选择的模型数量
# sort参数指定排序方式,这里使用"DUMMY"表示不进行排序
# parallel参数指定使用的并行计算后端,这里使用Dask作为后端
compare_models(include=test_models, n_select=2, sort="DUMMY", parallel=FugueBackend("dask"))
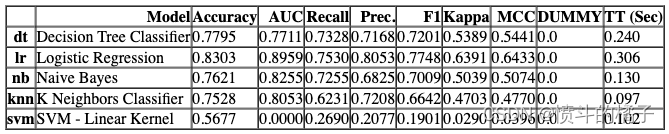
[DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=0, splitter='best'),
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=0, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)]
pull()
# 定义一个Scores类
class Scores:
# 定义一个名为score_dummy2的方法,用于计算得分
# 参数y_true表示真实标签,y_prob表示预测概率,axis表示轴
def score_dummy2(self, y_true, y_prob, axis=0):
return 1.0
# 创建一个Scores对象
scores = Scores()
# 添加一个指标
add_metric(
id='mydummy2', # 指标的唯一标识符
name='DUMMY2', # 指标的名称
score_func=scores.score_dummy2, # 指标的计算函数
target='pred_proba', # 指标的目标值,这里是预测概率
greater_is_better=True, # 指标的得分越大越好
)
Name DUMMY2
Display Name DUMMY2
Score Function <bound method Scores.score_dummy2 of <__main__...
Scorer make_scorer(score_dummy2, needs_proba=True, er...
Target pred_proba
Args {}
Greater is Better True
Multiclass True
Custom True
Name: mydummy2, dtype: object
# 调用compare_models函数,传入参数include=test_models、n_select=2、sort="DUMMY2"和parallel=FugueBackend("dask")
compare_models(include=test_models, n_select=2, sort="DUMMY2", parallel=FugueBackend("dask"))

[DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=0, splitter='best'),
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=0, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)]
# 这是一个函数定义,函数名为pull
def pull():
# 这是一个空函数,没有任何代码
pass

(7) Spark设置
强烈建议每个Spark执行器上只有一个worker,这样worker可以充分利用所有的CPU(设置spark.task.cpus)。当你这样做时,你应该明确地在setup中设置n_jobs为每个执行器的CPU数量。
executor_cores = 4
spark = SparkSession.builder.config("spark.task.cpus", executor_cores).config("spark.executor.cores", executor_cores).getOrCreate()
setup(data=get_data("juice", verbose=False, profile=False), target = 'Purchase', session_id=0, n_jobs=executor_cores)
compare_models(n_select=2, parallel=FugueBackend(spark))
(8) Dask
Dask有假分布式模式,例如默认的(多线程)和多进程模式。默认模式可以正常工作(但实际上是按顺序运行的),而多进程模式目前对PyCaret不起作用,因为它会干扰PyCaret的全局变量。另一方面,任何Spark执行模式都可以正常工作。
(9) 本地并行化
对于尝试非平凡数据和模型的实际用途,本地并行化(最简单的方法是使用上面显示的本地Dask作为后端)通常没有性能优势。因为在训练过程中很容易超载CPU,增加资源争用。本地并行化的价值在于验证代码,并让你相信分布式环境将在更短的时间内提供预期的结果。
(10) 如何开发
分布式系统很强大,但你必须遵循一些良好的实践来使用它们:
- 从小到大: 最初,你必须从一小组数据开始,例如在
compare_model中将你想尝试的模型限制为一小组廉价模型,当你验证它们工作正常后,可以切换到更大的模型集合。 - 从本地到分布式: 你应该按照这个顺序进行:先在本地验证小数据,然后在分布式环境下验证小数据,最后在分布式环境下验证大数据。当前的设计使过渡无缝。你可以按顺序进行这些操作:
parallel=None->parallel=FugueBackend()->parallel=FugueBackend(spark)。在第二步中,你可以替换为本地的SparkSession或本地的dask。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!