Redis为什么快?
参考文章:
渐进式rehash
Redis为什么快?
1.使用内存存储数据
2.单线程避免上下文切换。
3.Redis采用epoll做为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了事件,不在I/O上浪费过多的时间,使得Redis在网络 IO 操作中能并发处理大量的客户端请求,实现了高吞吐率。
4.渐进式Rehash
redis如何解决哈希冲突的?
Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2,我们知道存储hash那么一定会存在哈希冲突的问题。因此redis采用了链式存储+渐进式rehash的方法来减少哈希冲突的问题。
链式存储
这里和HashMap的存储结构类似。
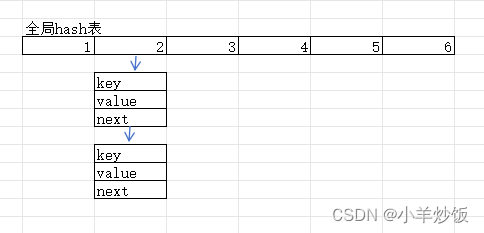
虽然数组+链表的形式能够减少hash冲突,但仍然会有弊端。当链表特别长的时候,效率仍然特别低。在HashMap中为了解决这个问题会将链表转换成红黑树,以及HashMap会有扩容的逻辑,redis中也类似,当桶中的节点数超过一定的数量时(已插入的元素数量是桶容量的5倍),就会进行相应的优化。
rehash
redis中rehash的核心思想是,增加现有的哈希桶数量,让逐渐增多的 entry 元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。(这里其实我感觉跟HashMap中的扩容逻辑很像)下面是它的大致流程:
为了使 rehash 操作更高效,Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
- 给哈希表 2 分配更大的空间,一般是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中(在hash表2下进行重新计算hash值);
- 释放哈希表 1 的空间。
这里和JVM垃圾回收中的复制算法很像。
那么这里同样会带来新的问题,当数组容量特别大的时候,如果发生rehash那么会移动大量的元素,这样仍然会导致redis线程阻塞。因此采用了渐进式rehash
渐进式rehash
渐进式,顾名思义,就是不一次性将所有的数据进行转移,而是一步一步的进行转移,直到最后全部完成。避免了一次性大批量的在两个全局hash表之间拷贝数据造成线程阻塞
渐进式 rehash:在上述第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 通过rehash放置到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。
渐进式rehash执行时,除了根据键值对的操作来进行数据迁移,Redis本身还会有一个定时任务在执行rehash,如果没有键值对操作时,这个定时任务会周期性地(例如每100ms一次)搬移一些数据到新的哈希表中,这样可以缩短整个rehash的过程。
综上所述:两种rehash的时机:
每次redis处理客户端发送的请求时:一次只搬迁1个桶
redis本身的定时任务:一次执行1毫秒,最少搬迁100个桶
思考:一个桶本来已经rehash了再有新增的entry该怎么办?
在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。 另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 傅立叶变换空间载波法在Matlab中恢复波面相位信息
- vue3使用特殊字符@、~代替路径src
- 深入了解JavaScript中的正则表达式构造函数和正则表达式字面量
- HarmonyOS第一课,运行helloWorld
- MySQL单表查询练习题
- 算法训练营Day35(贪心4)
- 无需手动搜索!轻松创建IntelliJ IDEA快捷方式的Linux教程
- 对象基础(总) - JS
- 2024华数杯国际赛A题B题思路及代码!
- TopAccess验证东芝刷卡打印机苹果电脑连接教程(适用于intel和苹果m芯片)