04 双向链表
目录
1.双向链表
2.实现
3.OJ题
4.链表和顺序表对比
1. 双向链表
前面写了单向链表,复习一下
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多作为其他数据结构的子结构,如哈希桶、图的邻接等。另外这种结构在笔试面试中出现多
带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构, 都是带头双向循环链表。另外这个结构虽然复杂,但是使用代码实现以后发现会带来很多优势,实现反而简单了
2. 实现
头文件
#pragma once
//数据类型
typedef int DataType;
//结构
typedef struct _SListNode
{
DataType data;
struct _SListNode* pNext;
}SListNode;
//插入
void PushFront(SListNode** pHead, DataType data);
void PushBack(SListNode** pHead, DataType data);
//pos之前插入
void Insert(SListNode** pHead, SListNode* pPos, DataType data);
//pos之后插入
void InsertAfter(SListNode** pHead, SListNode* pPos, DataType data);
//查找
SListNode* Find(SListNode* pHead, DataType data);
//删除
void PopFront(SListNode** pHead);
void PopBack(SListNode** pHead);
void Erase(SListNode** pHead, SListNode* pos);
// 删除pos位置后面的值
void EraseAfter(SListNode* pos);
//打印
void PrintList(SListNode* pHead);
//销毁
void Destory(SListNode** pHead);
插入只需要修改新节点的前后节点,新节点前后节点的链接,注意顺序,不能覆盖后面需要的值
插入和删除可以复用insert和erase的函数,所以也可以只写这两个,然后来实现头插尾插这些
#include "List.h"
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
List* BuyNode(DATATYPE data)
{
List* newnode = (List*)malloc(sizeof(List));
if (newnode == NULL)
{
perror("mallco");
return NULL;
}
//初始化数据
newnode->data = data;
newnode->pre = NULL;
newnode->next = NULL;
return newnode;
}
List* Init()
{
List* head = BuyNode(-1);
if (head == NULL)
{
perror("mallco");
}
head->pre = head;
head->next = head;
return head;
}
void PrintList(List* head)
{
List* cur = head->next;
while (cur != head)
{
printf("->%d ", cur->data);
cur = cur->next;
}
printf("\r\n");
}
void PushFront(List* head, DATATYPE data)
{
assert(head);
//创建节点
List* newnode = BuyNode(data);
newnode->pre = head;
newnode->next = head->next;
head->next->pre = newnode;
head->next = newnode;
/*
List* first = head->next;
head->next = newnode;
newnode->pre = head;
newnode->next = first;
first->pre = newnode;
*/
//Insert(head->next, data);
}
void PushBack(List* head, DATATYPE data)
{
assert(head);
//创建节点
List* newnode = BuyNode(data);
List* tail = head->pre;
newnode->pre = tail;
newnode->next = head;
tail->next = newnode;
head->pre = newnode;
//Insert(head, data);
}
void Insert(List* pos, DATATYPE data)
{
assert(pos);
//创建节点
List* newnode = BuyNode(data);
List* prev = pos->pre;
newnode->pre = pos->pre;
newnode->next = pos;
prev->next = newnode;
pos->pre = newnode;
}
void PopFront(List* head)
{
assert(head);
assert(!Empety(head));
List* del = head->next;
head->next = del->next;
del->next->pre = head;
free(del);
/*
List* first = head->next;
List* second = first->next;
head->next = second;
second->pre = head;
free(first);
*/
//erase(head->next)
}
void PopBack(List* head)
{
assert(head);
assert(!Empety(head));
List* del = head->pre;
//保留尾节点前一个
List* tailpre = del->pre;
tailpre->next = head;
head->pre = tailpre;
free(del);
//erase(head->pre)
}
void Erase(List* pos)
{
assert(pos);
List* posPre = pos->pre;
List* posNext = pos->next;
posPre->next = posNext;
posNext->pre = posPre;
free(pos);
}
List* FindNode(List* head, DATATYPE data)
{
assert(head);
List* cur = head->next;
while (cur != head)
{
if (cur->data == data)
return cur;
cur = cur->next;
}
return NULL;
}
bool Empety(List* head)
{
assert(head);
return head->next == head;
}
void Destory(List* head)
{
assert(head);
List* cur = head->next;
while (cur != head)
{
List* next = cur->next;
free(cur);
cur = next;
}
free(head);
}
主文件
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include "List.h"
int main()
{
List* list = Init();
PushFront(list, 3);
PushFront(list, 2);
PushFront(list, 1);
PushBack(list, 4);
PushBack(list, 5);
PrintList(list);
PopFront(list);
PopBack(list);
PrintList(list);
List* pos = FindNode(list, 3);
if (pos != NULL)
{
Insert(pos, 1);
PrintList(list);
}
Erase(pos);
PrintList(list);
Destory(list);
return 0;
}
3. OJ题
链表的复制
https://leetcode.cn/problems/copy-list-with-random-pointer/description/

思路
直接思路,拷贝一个一模一样的链表,关键是复制random对应的节点值,要遍历看原链表指向的random是在第几个,将新链表的random链接到对应位置,这种方法时间复杂度较高
另一种思路。在原链表每个节点后面插入一个拷贝出来的原链表值。重点在random的链接,这样新链表的random就是原链表对应的rand节点的下一个位置。然后再创建一个新链表,将每个拷贝节点尾插并还原原链表
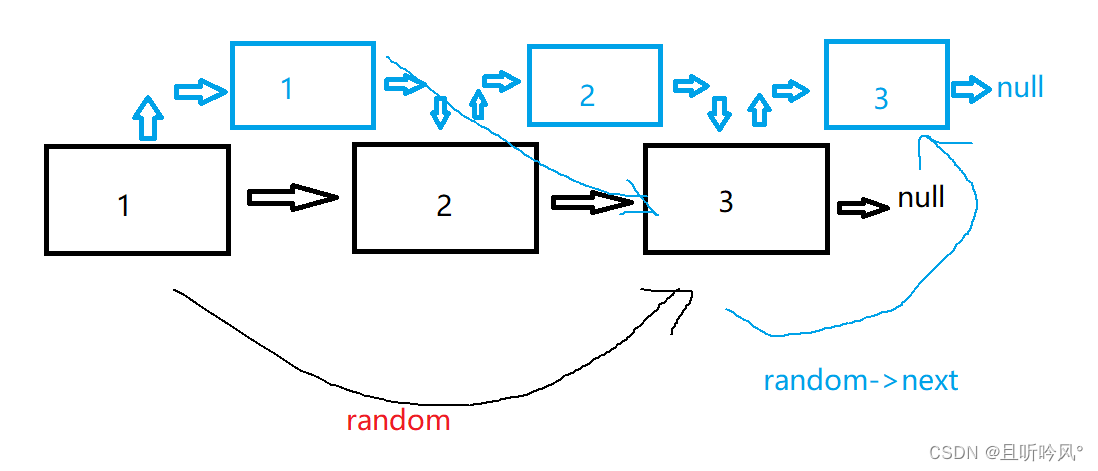
如图,原链表指向是1->2->3->null,插入蓝色的新拷贝链表,1->蓝1->2->蓝2->3->蓝3->null,原1的random指向3,那么拷贝链表的random指向就应该是3的next,就是拷贝链表的3
解绑过程如下图
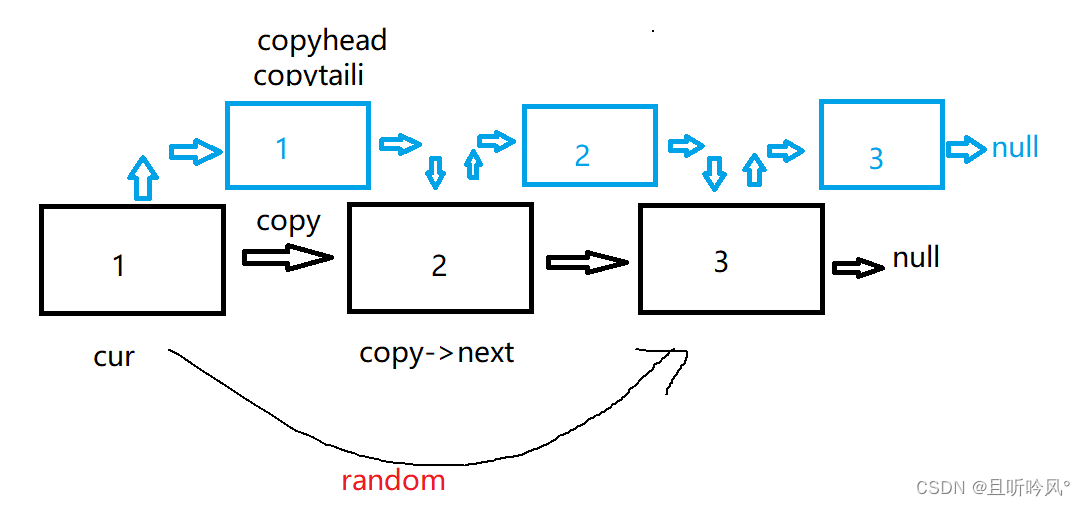
cur是当前节点,它的next是copy节点,首先链表头和尾本来是空,第一次置为第一个拷贝节点。将copy节点尾插到copytail链表,cur的next节点就是copy节点的下一个,然后将cur更新到copy的next,如下图
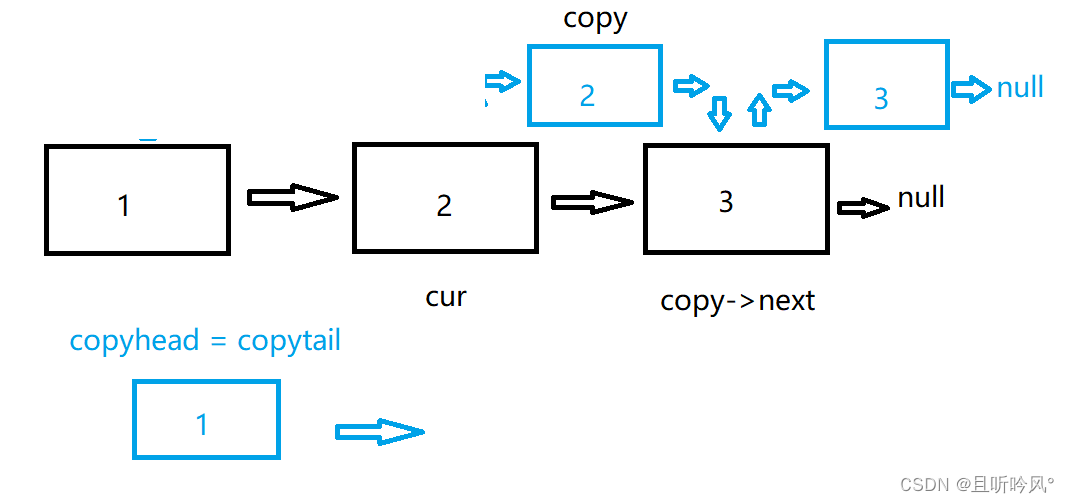 这样一直循环
这样一直循环
/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head) {
struct Node* cur = head;
//拷贝节点插入在原节点后面
while(cur != NULL)
{
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
copy->val = cur->val;
struct Node* next = cur->next;
//插入
cur->next = copy;
copy->next = next;
cur = next;
}
//控制拷贝节点的random
cur = head;
while(cur != NULL)
{
struct Node* copy = cur->next;
if(cur->random == NULL)
{
copy->random = NULL;
}
else{
//指向对应的拷贝链表
copy->random = cur->random->next;
}
cur = copy->next;
}
//尾插拷贝链表,还原原链表
struct Node* copyhead = NULL;
struct Node* copytail = NULL;
cur = head;
while(cur != NULL)
{
struct Node* copy = cur->next;
struct Node* next = copy->next;
//尾插
if(copyhead == NULL)
{
copyhead = copytail = copy;
}
else{
copytail->next = copy;
copytail = copytail->next;
}
//恢复原链表
cur->next = copy->next;
cur = next;
}
return copyhead;
}
4. 顺序表和链表对比
| 不同点 | 顺序表 | 链表 |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,物理上不一定 |
| 随机访问 | 支持O(1) | 不支持O(N) |
| 任意位置插入和删除元素 | 可能需要搬元素,O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够扩容 | 没有容量概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置频繁插入和删除 |
| 缓存利用率 | 高 | 低 |
链表
优点:
1.任意位置插入删除O(1)
2.按需申请释放空间
缺点:
1.不支持下标随机访问
2.CPU告诉缓存命中率更低
顺序表
优点:
1.尾插尾删效率不错
2.下标的随机访问
3.CPU告诉缓存命中率更高
缺点:
1.除过尾插尾删,效率低O(N),需要挪动元素
2.空间不够,需要扩容
3.扩容需要代价,一般伴随空间浪费
cpu存储分类 数据的存储从服务器到硬盘,再到内存。其中内存还有寄存器和告诉缓存部分,访问速度越网上越快,但代价也越高,空间也越小。寄存器中拿数据是最快的,但一般寄存器只有几十字节
数据的存储从服务器到硬盘,再到内存。其中内存还有寄存器和告诉缓存部分,访问速度越网上越快,但代价也越高,空间也越小。寄存器中拿数据是最快的,但一般寄存器只有几十字节
内存读取数据并不是需要多少读多少,它会将需要读取的数据后面的一部分也读入缓存中,因为这部分极有可能还会读取,这就是命中缓存,访问速度更快。所以顺序表式连续存储的,命中缓存的几率更高,速度也就更快
每个数据类型都各有优势,有不同的应用场景,不存在优劣
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Redis-网络模型
- 小米红米Note9 Pro 5G刷PixelOS,并安装kali nethunter
- 利用python进行数据分析 第十四章 14.5 2012联邦选举委员会数据库
- 【LLM】vLLM部署与int8量化
- 深度解析代理伺服器與端口的關係
- DevOps(7)
- Python中的复数
- 特斯拉推出Optimus-Gen 2人形机器人,马斯克:“Optimus机器人被严重低估了”
- 解决最长公共前缀问题
- 电脑mac怎么快速删除文件,CleanMyMaCX4.14.7轻松缓存垃圾和其他电脑垃圾