Mysql索引的结构——B++ Tree
前言
索引是Mysql中常用到的一个功能,可以大大加快查询速度,同时面试中也是经常碰到。本文是学习Mysql索引的归纳总结。
索引采用的数据结构——B+树
本部分主要是参考自小林Coding
B+树的由来
二分查找可以每次缩减一半,从而提高查找效率。
但是二分查找,若使用线性结构,每次插入,都是需要移动其余剩下的全部元素,消耗巨大。
因此有了二分查找树。
但是二叉树若每次插入的都比其父节点大,则会演变为链表,从而使查询复杂度从 O(logn)降低为 O(n)。
因此有了自平衡二叉树,诸如AVL树或红黑树,其都是这样的自平衡二叉树。
但由于其本质还是一棵二叉树,所以会随着数据量增大,导致层数增加, IO操作增多(每一层IO多一次)。
因此有了B树。其每个节点允许有M个子节点,M是B树的阶,假设M为3,那就是阶为3的B树,其每个节点最多有2(M-1)个数据和3(M)个子节点。若超过,则分裂节点。
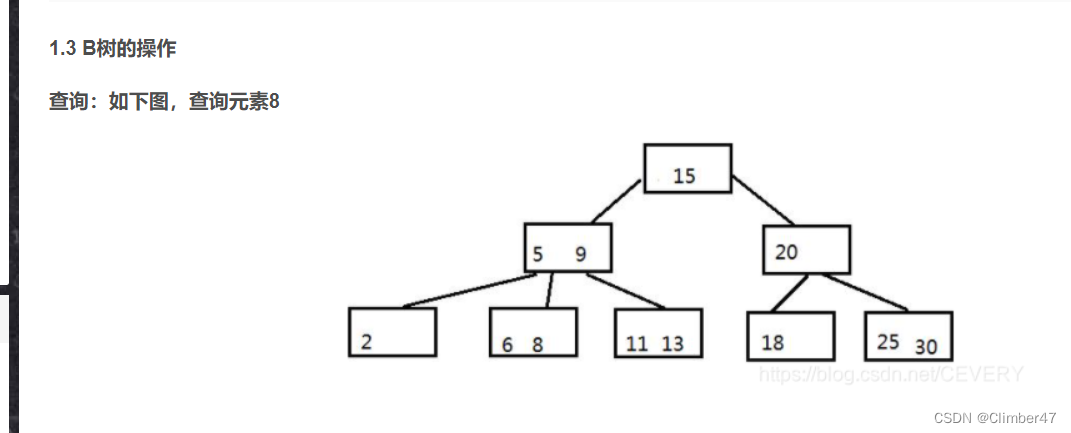
但是 B 树的每个节点都包含数据(索引+记录),每次IO都会需要查询到节点上记录的内容。若数据量大于索引的大小,那么在读取底层节点索引的时候,就会导致较多的IO操作。从而使性能受到巨大影响。
因此有了B+ 树,B+树和B树的结构其实相似,只是仅将数据存储在底层叶子节点。其余的子节点仅存储索引。从而解决了数据大、影响IO的问题。
其次,其底层叶子节点之间,既存了索引也存了记录。叶子节点之间通过链表连接起来。从而对于范围查询,可以大大提升效率。
B+树的结构
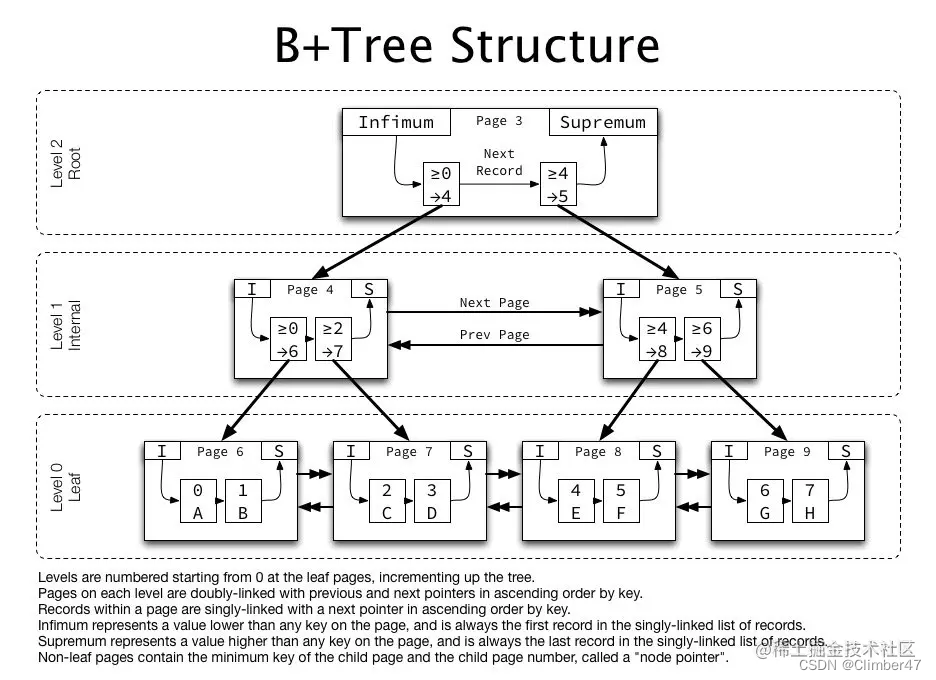
关于B++树的结构看图就好了。
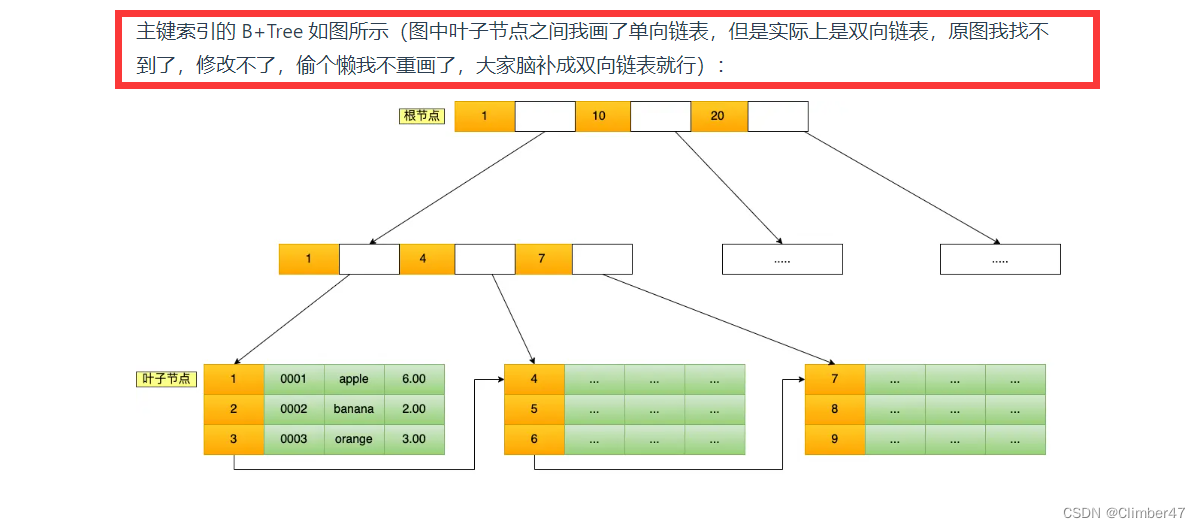
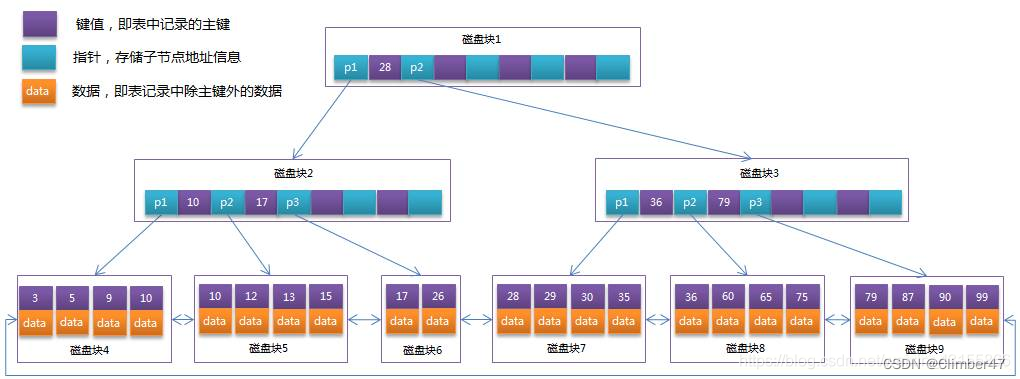
B+树的叶子节点是单链表还是双向链表
网上很多探讨针对于“其叶子节点是单向链表还是双向链表”,包括小林也是做出了一次纠正。
在此文发现了一些结论与有趣的探讨。
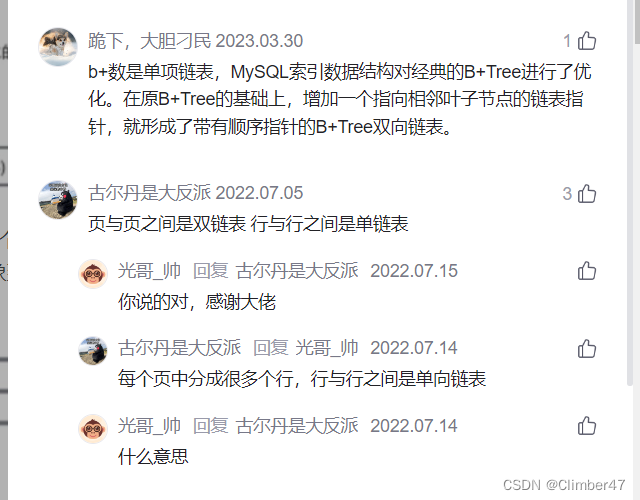
顺着此,找到了一个结论——B+ 树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。
为什么选用了B+ 树
这里直接复制小林的结论了。
B+ 树 vs B 树
B+Tree 只在叶子节点存储数据,而 B 树 的非叶子节点也要存储数据,所以 B+Tree 的单个节点的数据量更小,在相同的磁盘 I/O 次数下,就能查询更多的节点。
另外,B+Tree 叶子节点采用的是双链表连接,适合 MySQL 中常见的基于范围的顺序查找,而 B 树无法做到这一点。
B+ 树 vs 二叉树
对于有 N 个叶子节点的 B+Tree,其搜索复杂度为O(logdN),其中 d 表示节点允许的最大子节点个数为 d 个。
在实际的应用当中, d 值是大于100的,这样就保证了,即使数据达到千万级别时,B+Tree 的高度依然维持在 3~4 层左右,也就是说一次数据查询操作只需要做 3~4 次的磁盘 I/O 操作就能查询到目标数据。
而二叉树的每个父节点的儿子节点个数只能是 2 个,意味着其搜索复杂度为 O(logN),这已经比 B+Tree 高出不少,因此二叉树检索到目标数据所经历的磁盘 I/O 次数要更多。
B+ 树 vs Hash
Hash 在做等值查询的时候效率贼快,搜索复杂度为 O(1)。
但是 Hash 表不适合做范围查询,它更适合做等值的查询,这也是 B+Tree 索引要比 Hash 表索引有着更广泛的适用场景的原因。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【办公类-22-01】20240123 UIBOT逐一提取CSDN质量分
- Sqoop数据传输中的常见挑战及其解决方法
- 客户端、服务端在一个c++程序里
- mitmproxy抓包
- 基于ssm的课程在线教学平台设计与实现论文
- 医院患者满意度调查方案
- 异地组网的挑战与机遇:SDWAN技术的引领
- Google的Ndk-Sample学习笔记之一(hello-jniCallback)
- 【Hadoop】ZooKeeper数据模型Znode
- 游戏策划:游戏开发中的关键环节