【分布式技术】Elastic Stack部署,实操logstash的过滤模块常用四大插件
目录
一、Elastic Stack,之前被称为ELK Stack
步骤三:准备logstash的测试文件filebeat.conf
?步骤一:现在logstash的conf文件中进行filter模块的修改,添加grok插件
步骤三:filebeat与logstash对接? logstash与ES进行对接
?步骤二:准备logstash的conf文件,在filter模块中配置multiline插件
步骤一:先完成logstash的conf文件编写,完成语法检测以及启动
?编辑步骤三: 刷新nginx访问页面 在kibana页面验证效果
一、Elastic Stack,之前被称为ELK Stack
完成ELK与Filebeat对接
步骤一:安装nginx做测试
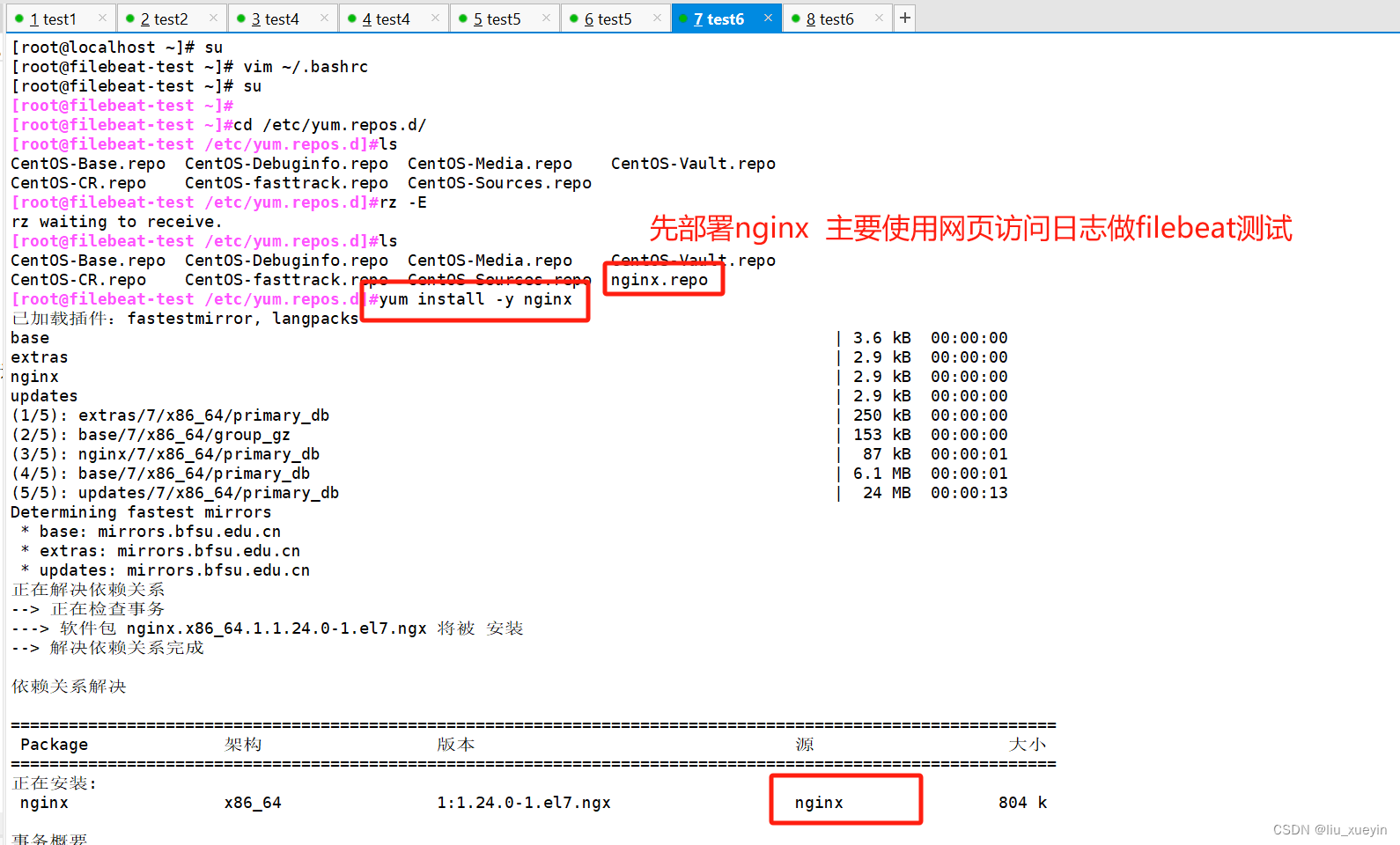
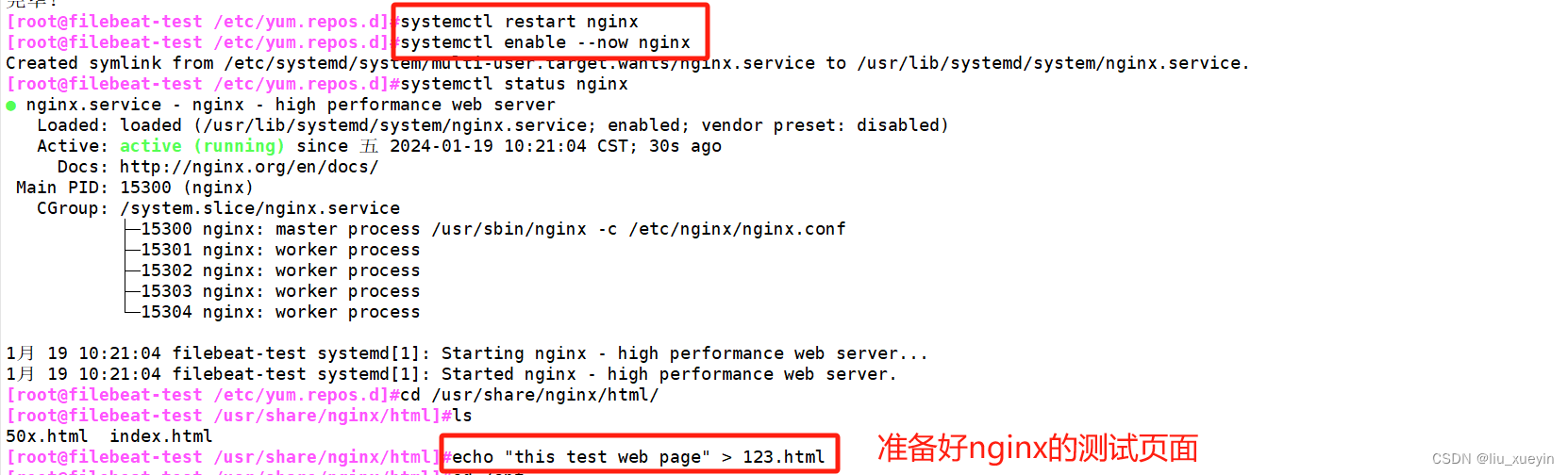 ?
?
?步骤二:完成filebeat二进制部署



步骤三:准备logstash的测试文件filebeat.conf
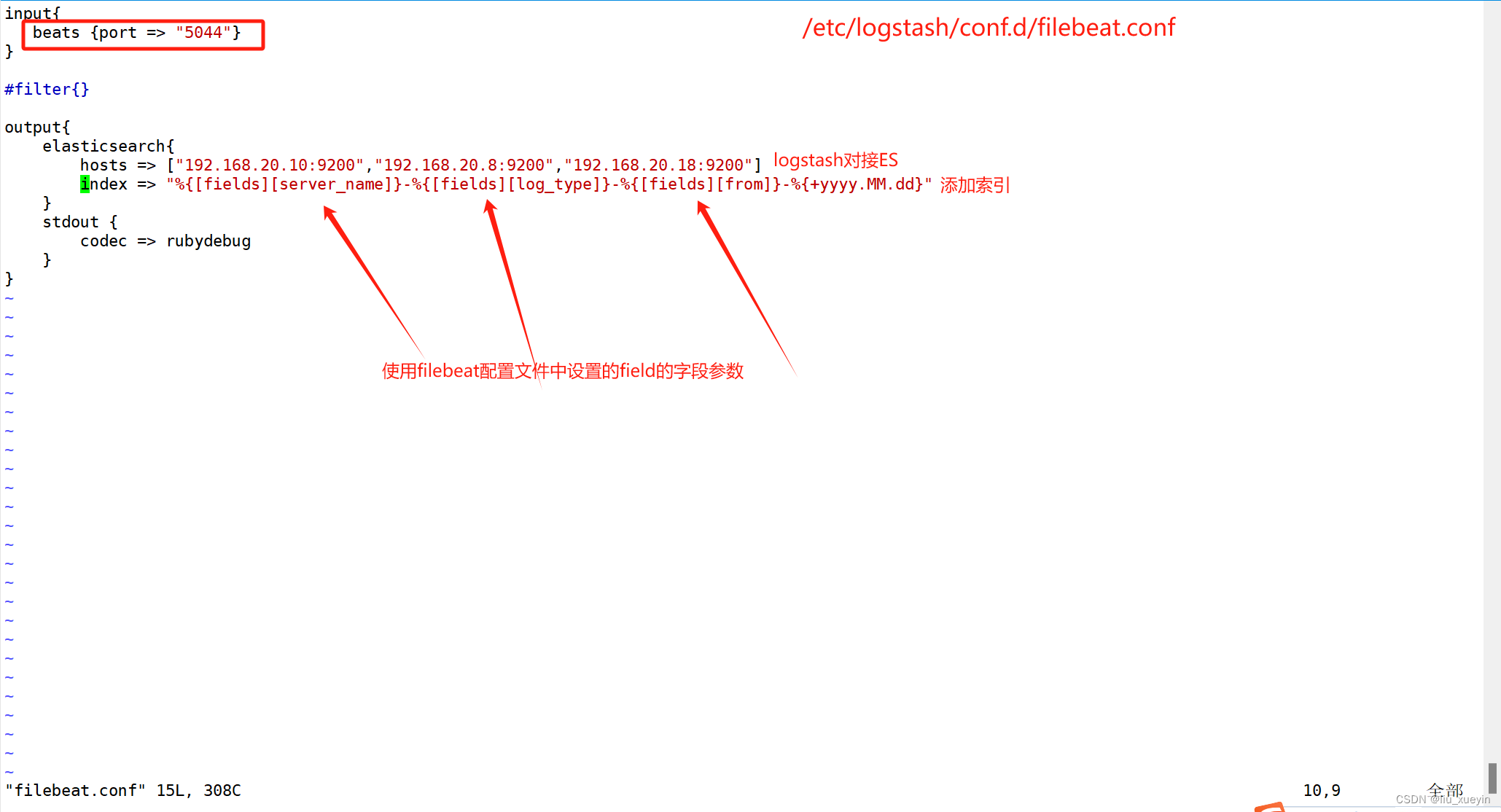
input{
beats {port => "5044"}
}
#filter{}
output{
elasticsearch{
hosts => ["192.168.20.10:9200","192.168.20.8:9200","192.168.20.18:9200"]
index => "%{[fields][server_name]}-%{[fields][log_type]}-%{[fields][from]}-%{+yyyy.MM.dd}"
}
stdout { ##表示测试的时候,如果屏幕输出内容了,那么表示logstash与ES对接成功,如果没有输出内容,那么可能filebeat与logstash对接失败
codec => rubydebug
}
}

[root@nginx-test conf.d]#logstash -f filebeat.conf -t
##语法检测?
步骤四:完成实验测试
[root@filebeat-test /usr/local/filebeat]#./filebeat -e -c filebeat.yml
##完成filebeat与logstash对接 注意命令的位置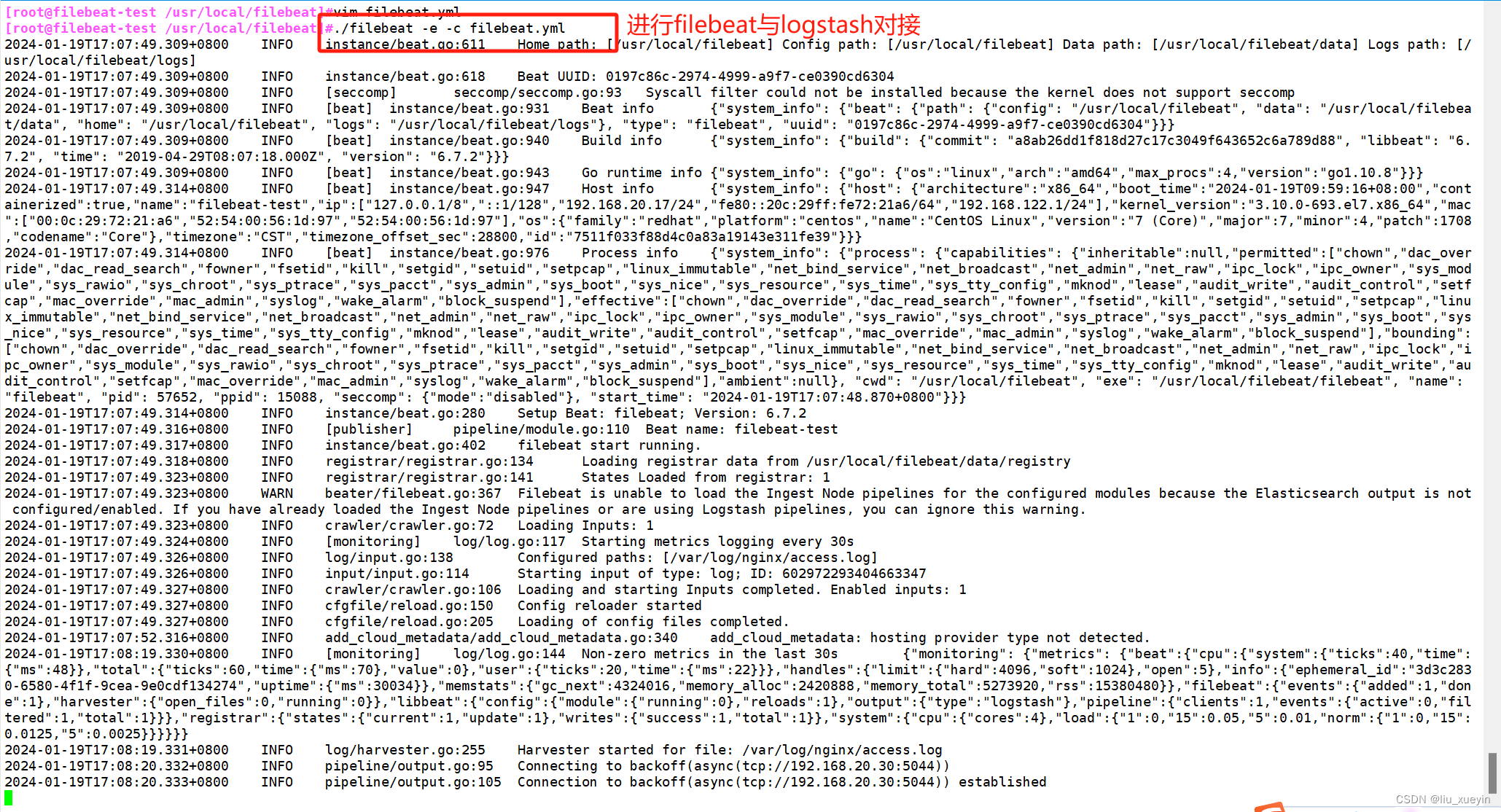
?
[root@nginx-test conf.d]#logstash -f filebeat.conf
##完成logstash与ES集群对接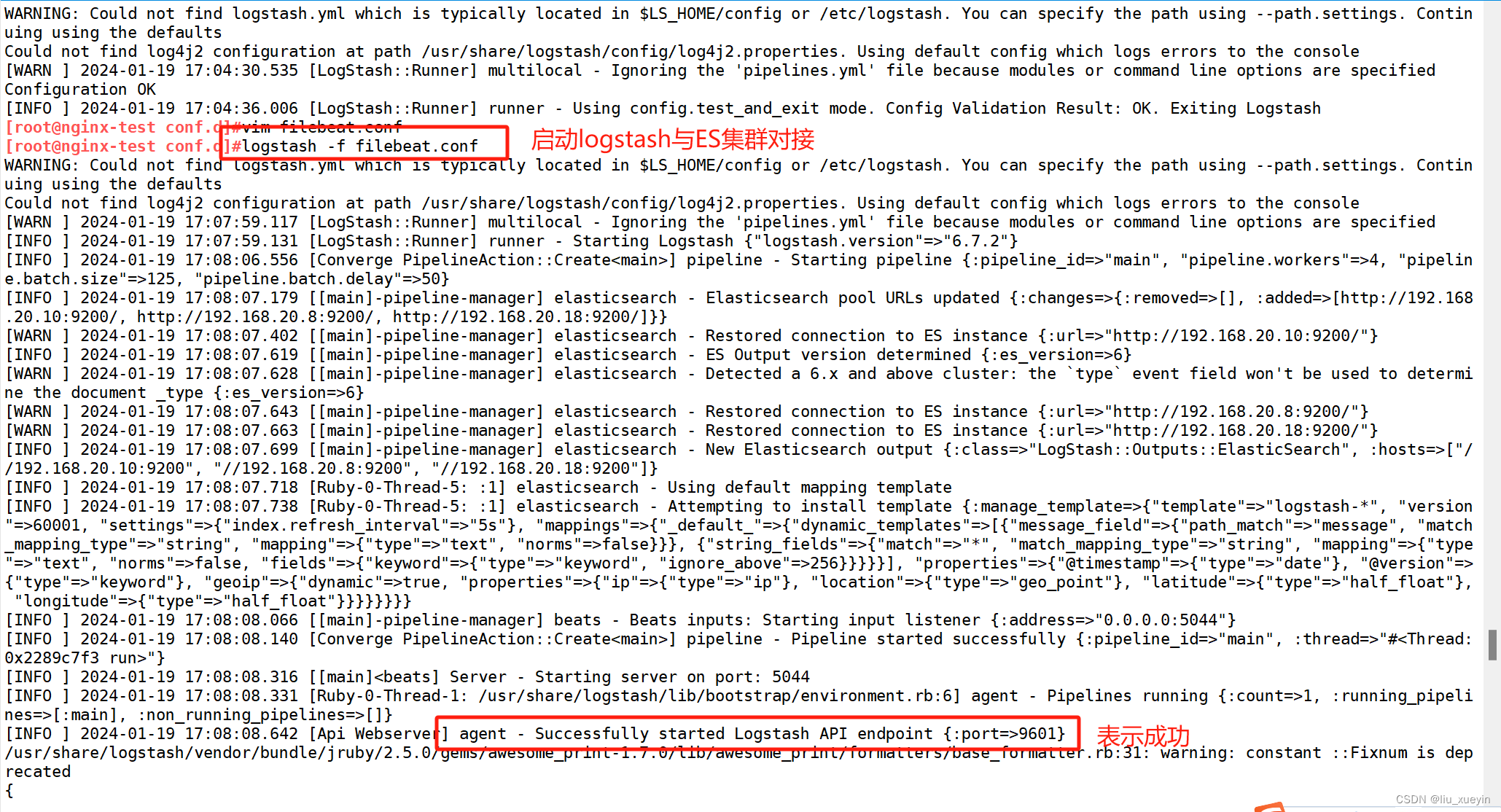 ?
?
 ?
?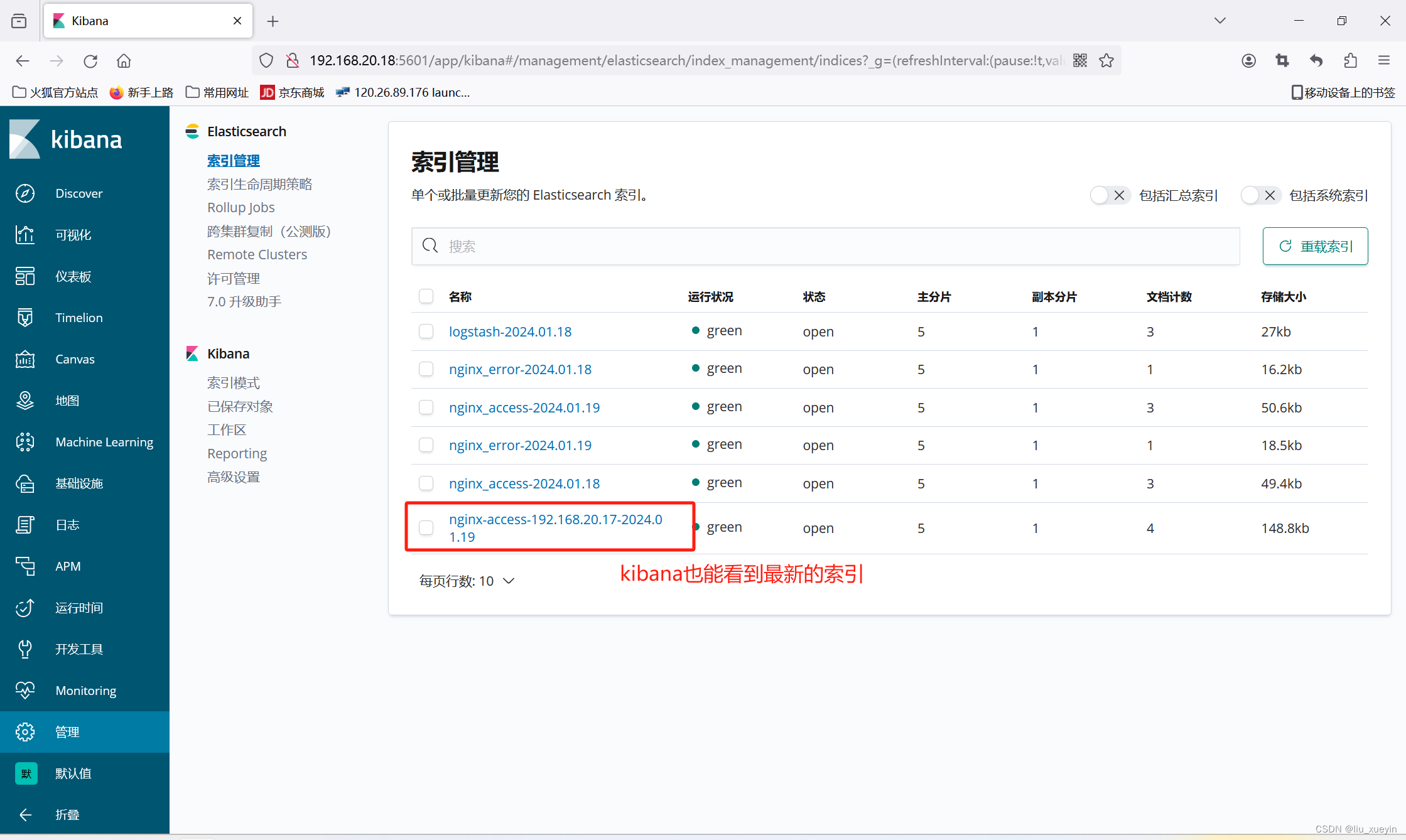
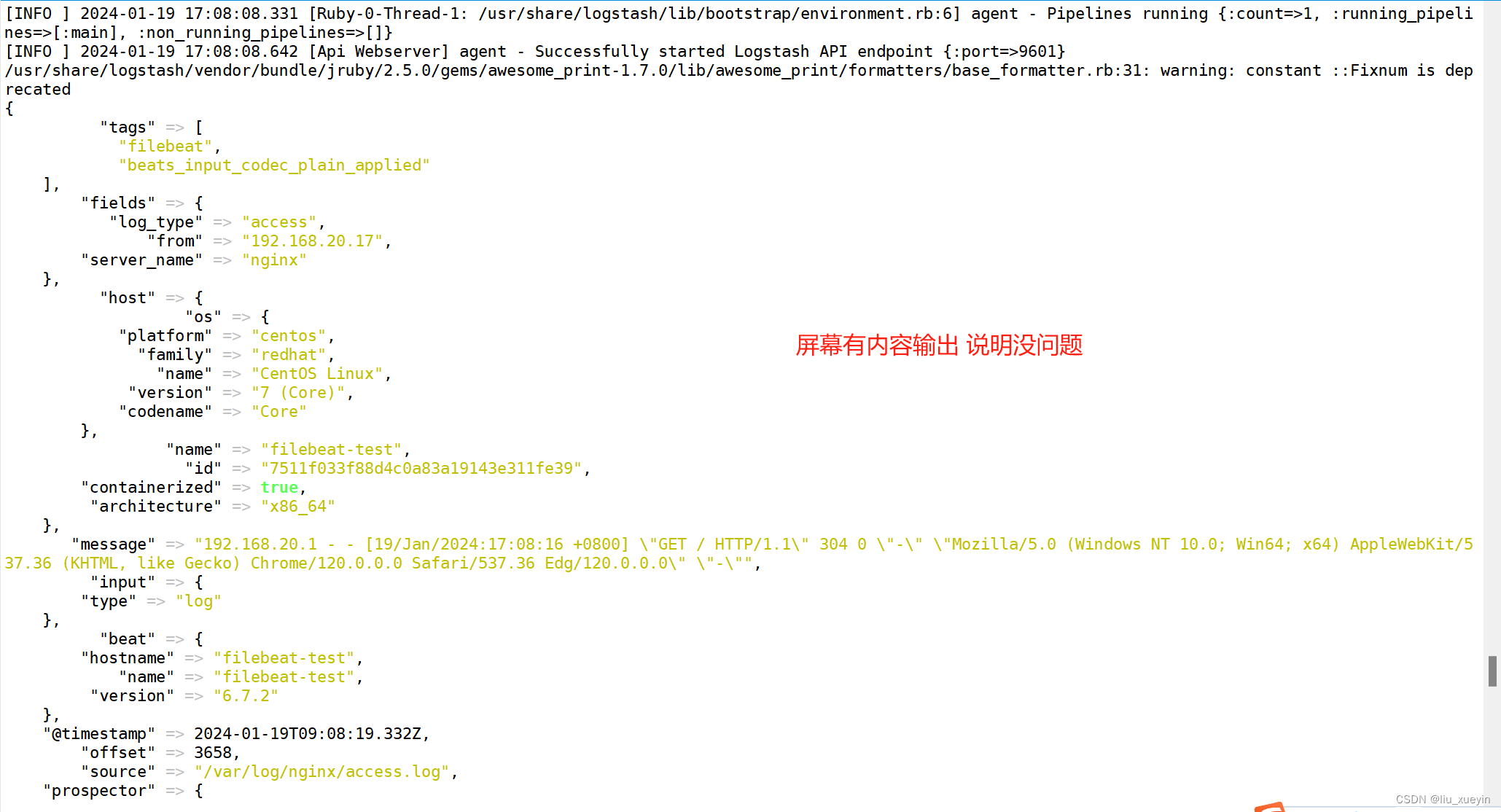
实验完成

 ?
?
二、logstash拥有强大的过滤功能,常用四种插件
1、grok
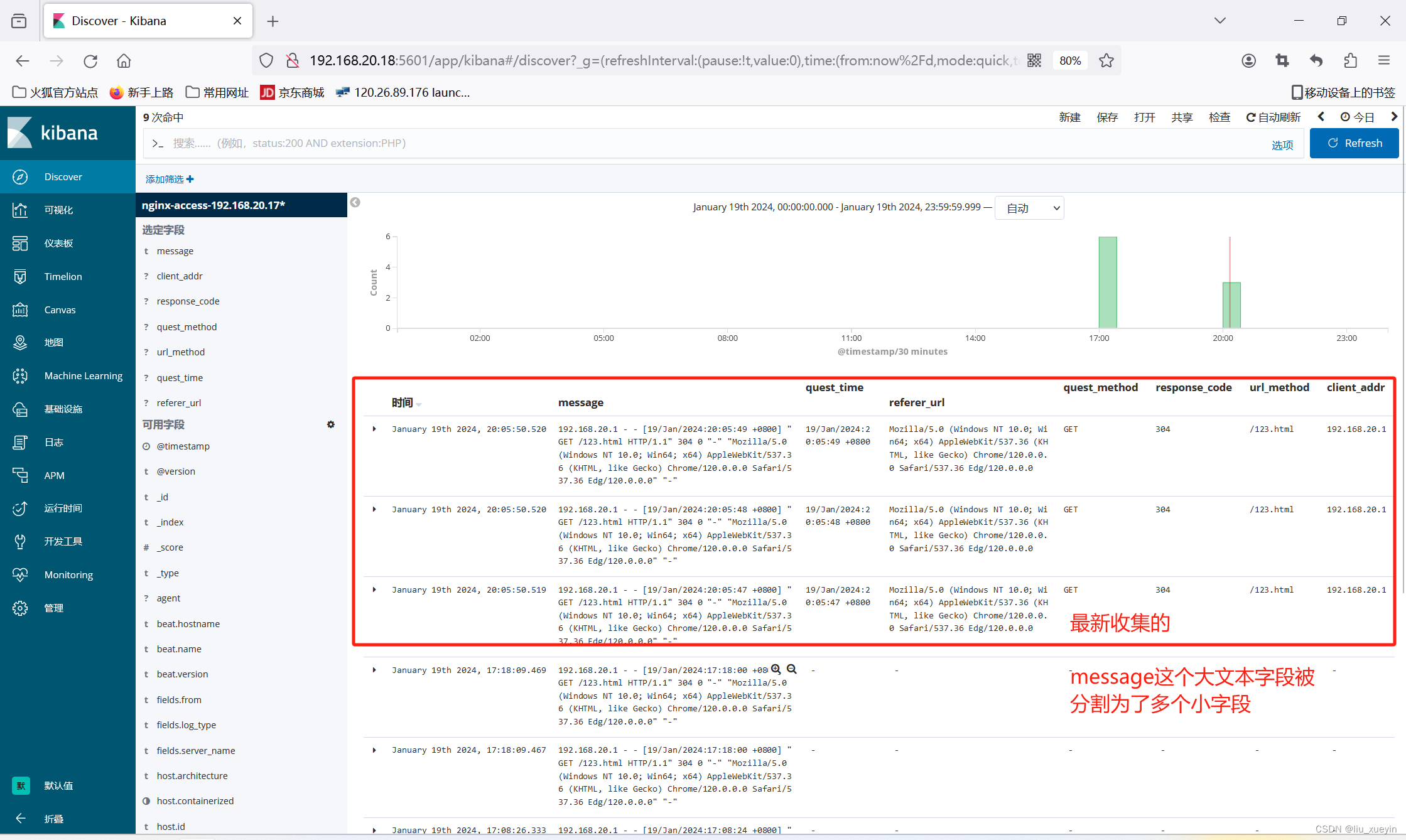
grok可以将大文本字段分片成若干的小字段,如刚刚的日志文件,一行的信息太多,需要将message这个大文本字段给分片成若干的小字段如访问ip、请求方法、URL、状态码等
grok有两种格式(并且支持混用)
内置正则匹配格式:%{内置正则表达式:自定义的小字段名称}
自定义正则匹配格式:(?<自定义的小字段名称>自定义的正则表达式)
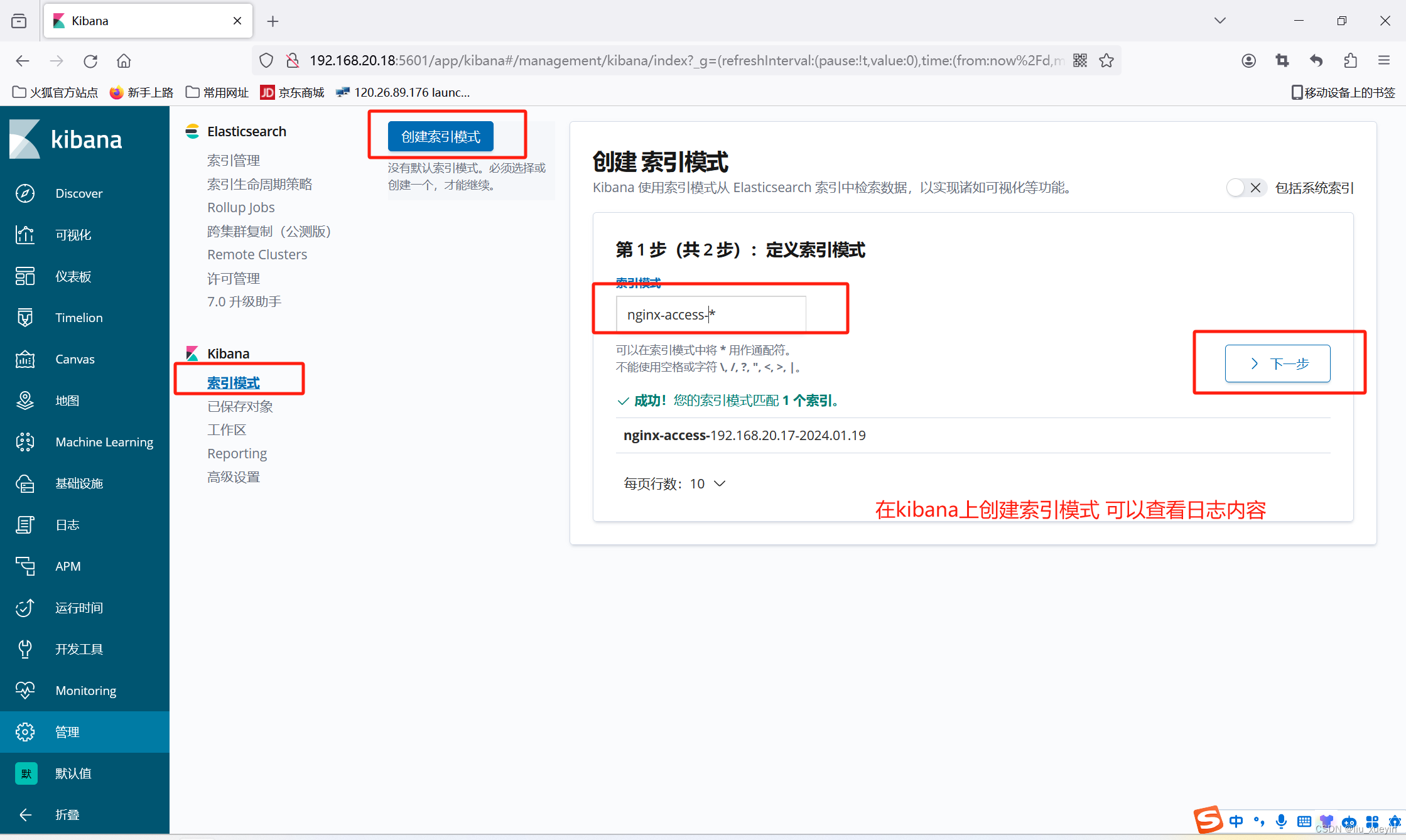
同时可以先在kibana的开发工具上做测试
192.168.20.1 - - [19/Jan/2024:17:08:24 +0800] "GET /123.html HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0" "-"
%{IP:client_addr}.*\[(?<quest_time>.*)\] "%{WORD:quest_method} %{URIPATHPARAM:url_method} .*" (?<response_code>\d+) .* "(?<referer_url>.*)" "(?<agent>.*)".*
##实际就是用正则表达式,表达这一整行的内容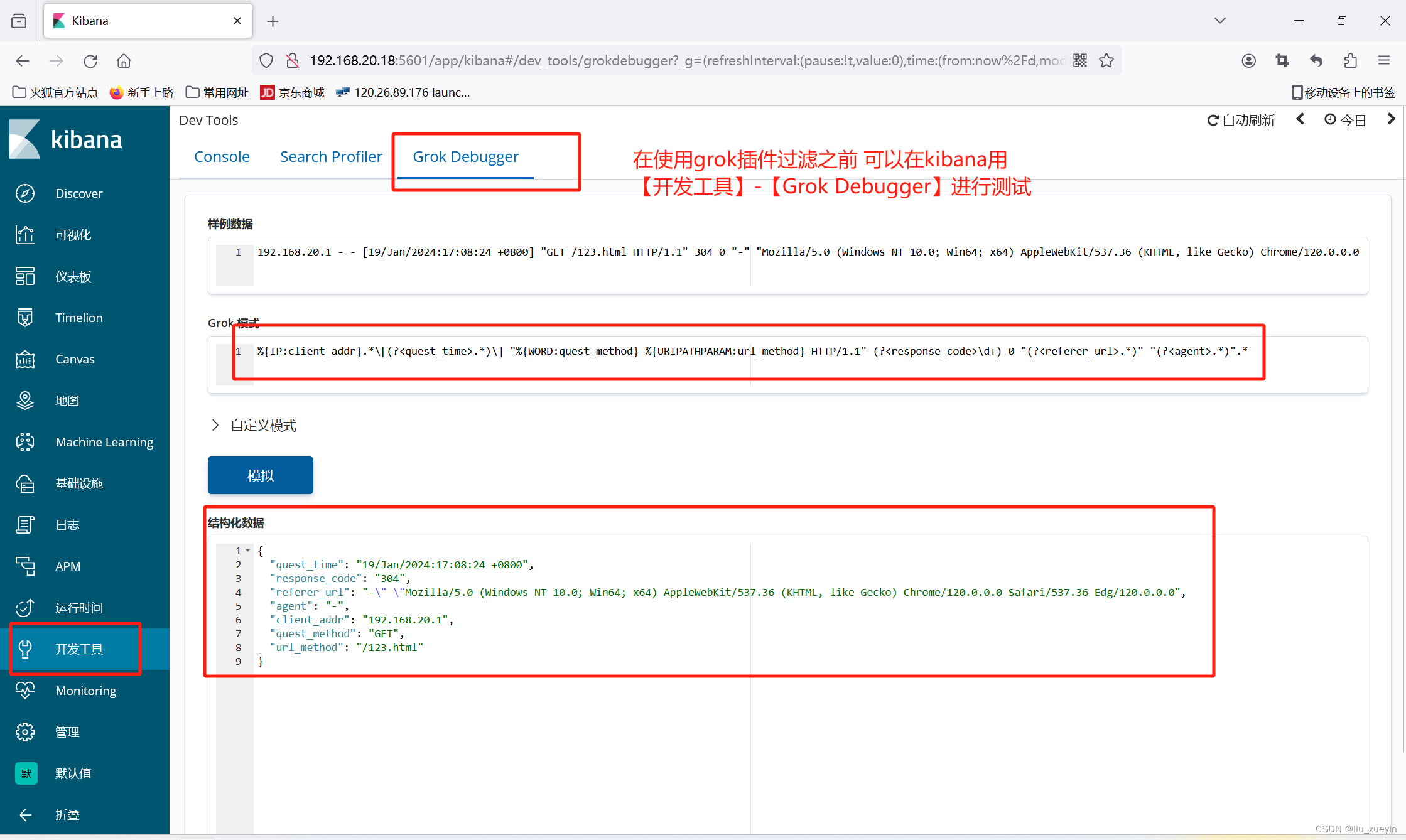

完成logstash测试
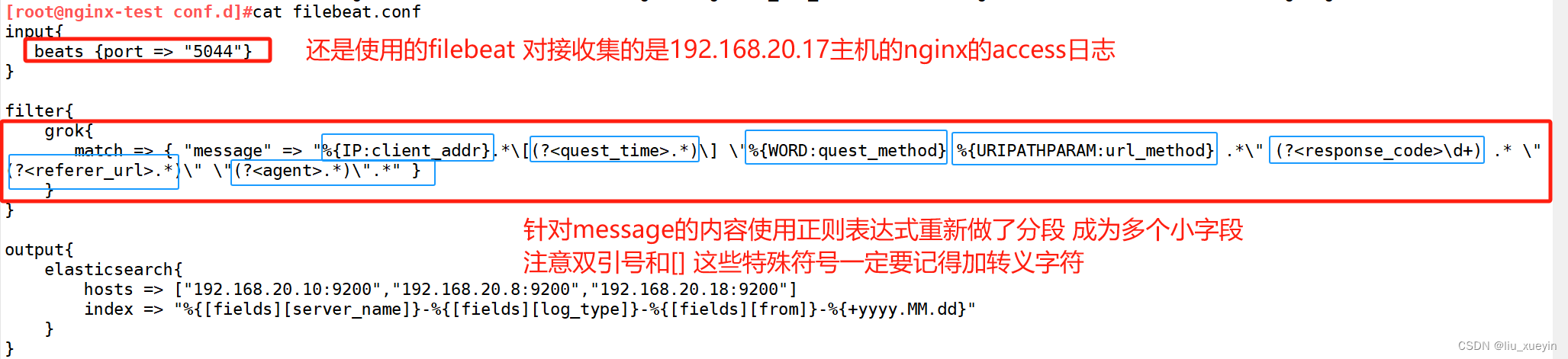
?步骤一:现在logstash的conf文件中进行filter模块的修改,添加grok插件
[root@nginx-test conf.d]#cat filebeat.conf
input{
beats {port => "5044"}
}
filter{
grok{
match => { "message" => "%{IP:client_addr}.*\[(?<quest_time>.*)\] \"%{WORD:quest_method} %{URIPATHPARAM:url_method} .*\" (?<response_code>\d+) .* \"(?<referer_url>.*)\" \"(?<agent>.*)\".*" }
}
}
output{
elasticsearch{
hosts => ["192.168.20.10:9200","192.168.20.8:9200","192.168.20.18:9200"]
index => "%{[fields][server_name]}-%{[fields][log_type]}-%{[fields][from]}-%{+yyyy.MM.dd}"
}
}
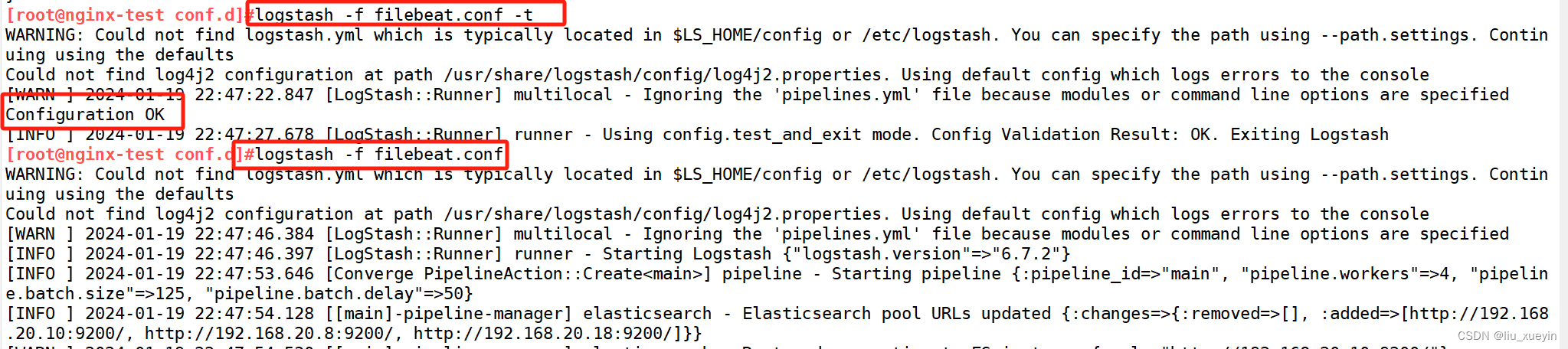
步骤二:完成语法测试,先测试完成
[root@nginx-test conf.d]#logstash -f filebeat.conf -t

步骤三:filebeat与logstash对接? logstash与ES进行对接

 ?
?
2、multiline
通常来讲,日志中一条信息以一行记录,但是有的java应用的日志会分为多行记录
那么multiline作用是将多行日志内容合并成一整行??
- pattern:用来匹配文本的表达式,也可以是grok表达式
- negate:是否对pattern的结果取反。false:不取反,是默认值。true:取反。将多行事件扫描过程中的行匹配逻辑取反(如果pattern匹配失败,则认为当前行是多行事件的组成部分)
- what:如果pattern匹配成功的话,那么匹配行是归属于上一个事件,还是归属于下一个事件。previous: 归属于上一个事件,向上合并。next: 归属于下一个事件,向下合并
举例实操
现在有java日志在/opt/java.log中,如图
步骤一:准备测试日志文件


?步骤二:准备logstash的conf文件,在filter模块中配置multiline插件
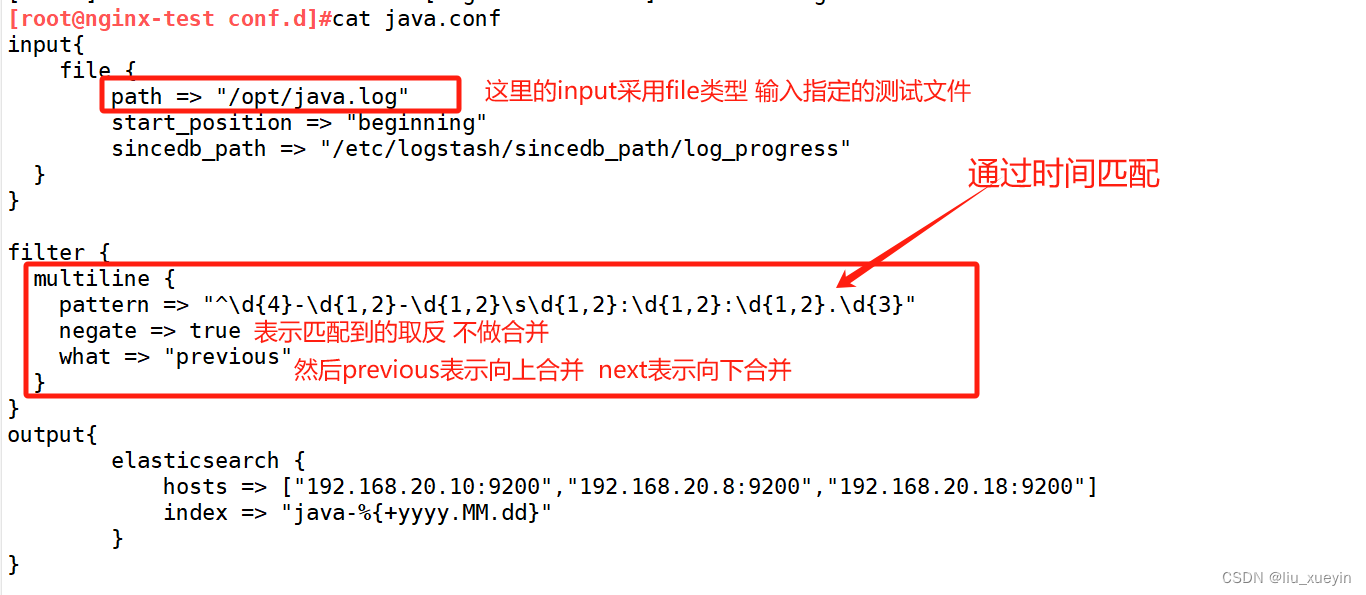
[root@nginx-test conf.d]#cat java.conf
input{
file {
path => "/opt/java.log"
start_position => "beginning"
sincedb_path => "/etc/logstash/sincedb_path/log_progress"
}
}
filter {
multiline {
pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}"
negate => true
what => "previous"
}
}
output{
elasticsearch {
hosts => ["192.168.20.10:9200","192.168.20.8:9200","192.168.20.18:9200"]
index => "java-%{+yyyy.MM.dd}"
}
}
步骤三:语法测试并启动logstash与ES对接


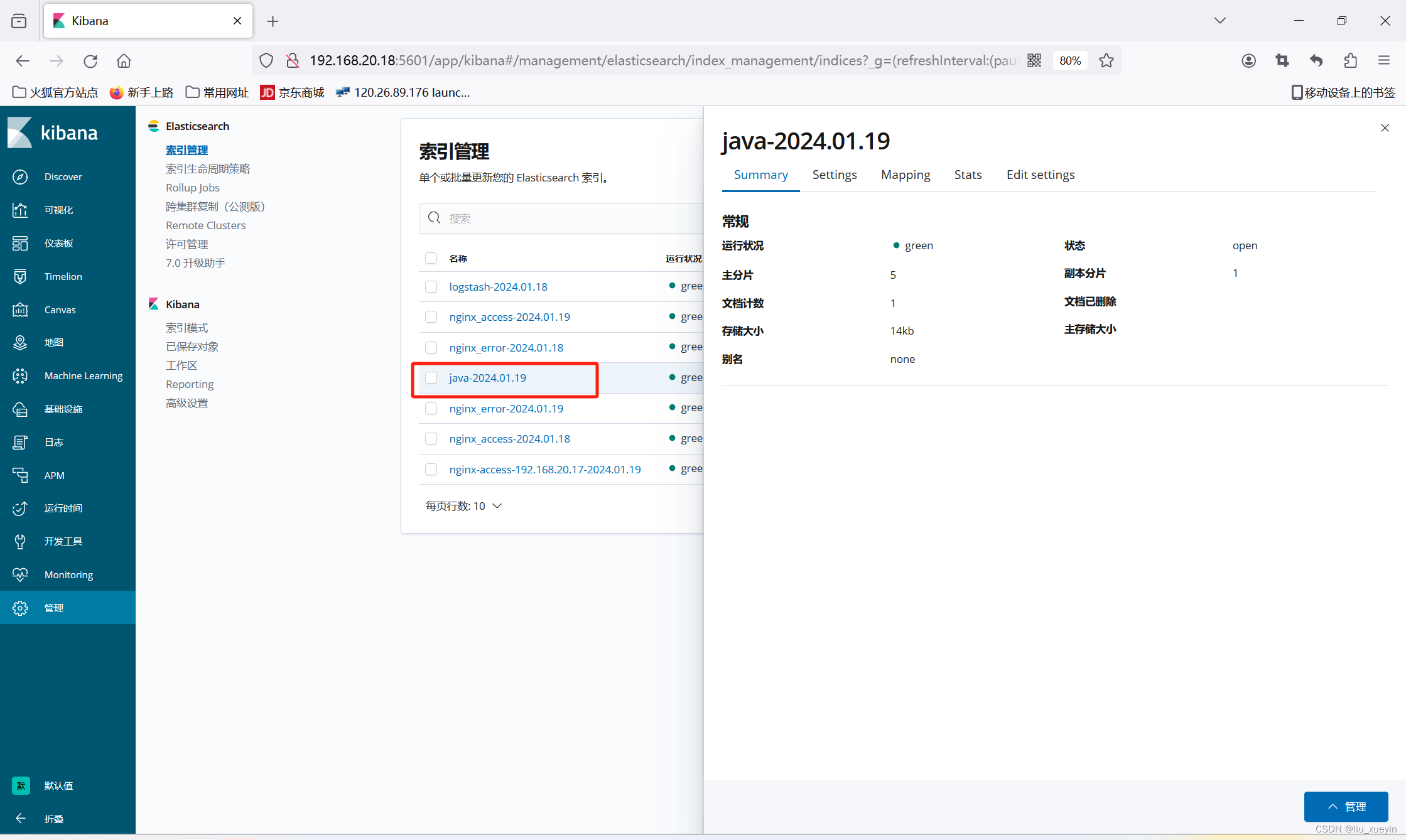
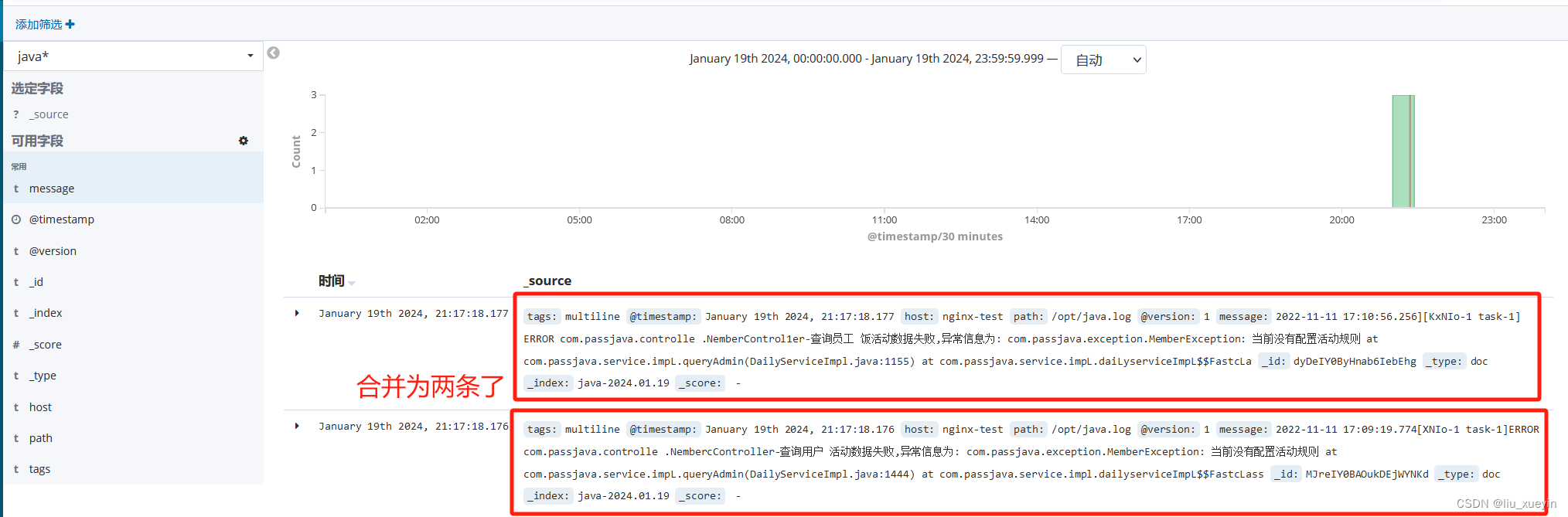
步骤五:查看kibana 进行验证
3、date
用于分析字段中的日期,然后使用该日期或时间戳作为事件的logstash时间戳。
痛点:
毕竟我这个url是静态的 相对动态请求比较快 而且字节数比较小。就这样的情况下 logstash接收时间与日志时间也是会有延迟的那么对于 生产中的 比如除 查询 当然是想统一一个标准 以日志时间为时间戳那么就需要用到date插件

比如还是刚刚的filebeat采集的nginx日志,现在想要实现访问的日志时间与logstash的时间一致
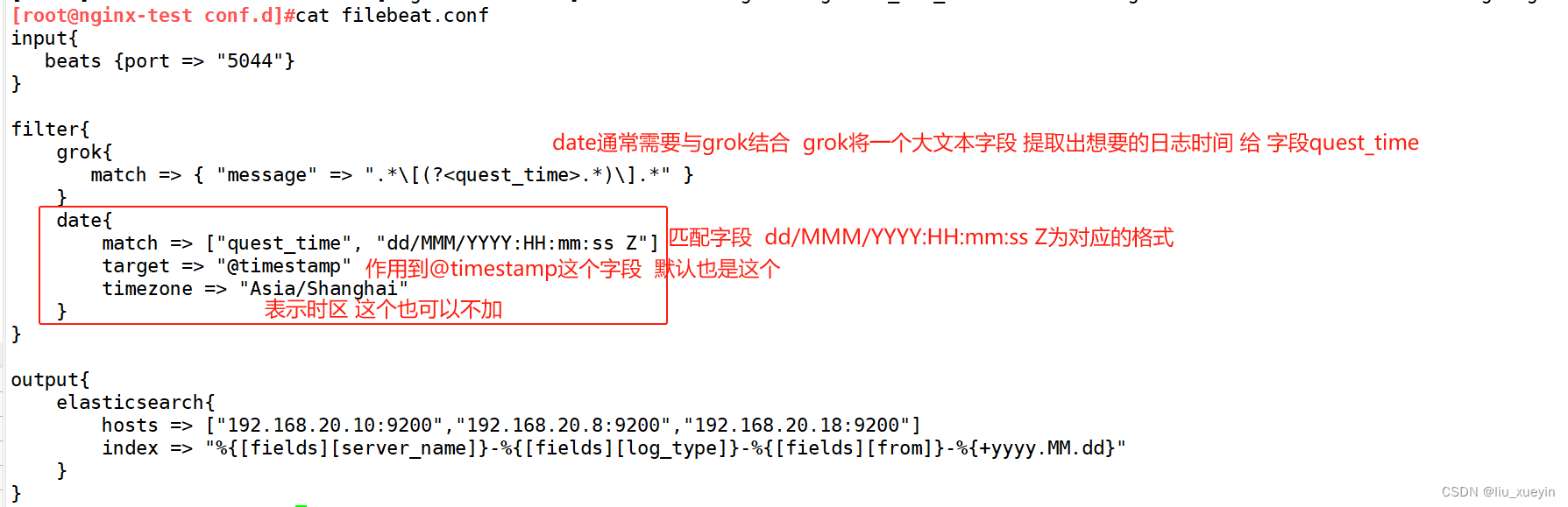
步骤一:先完成logstash的conf文件编写,完成语法检测以及启动
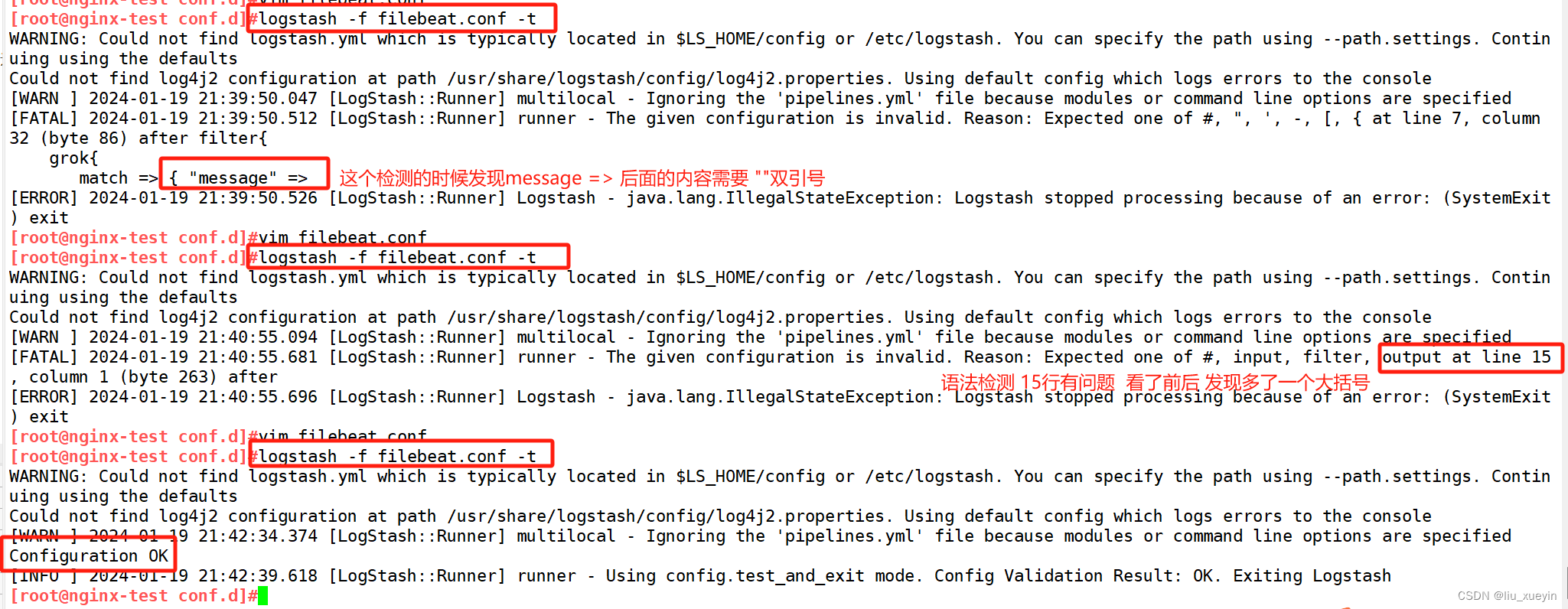
[root@nginx-test conf.d]#cat filebeat.conf
input{
beats {port => "5044"}
}
filter{
grok{
match => { "message" => ".*\[(?<quest_time>.*)\].*" }
}
date{
match => ["quest_time", "dd/MMM/YYYY:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
}
output{
elasticsearch{
hosts => ["192.168.20.10:9200","192.168.20.8:9200","192.168.20.18:9200"]
index => "%{[fields][server_name]}-%{[fields][log_type]}-%{[fields][from]}-%{+yyyy.MM.dd}"
}
}


步骤二:kibana前端界面验证

 ?
?

4、mutate数据修改插件
它提供了丰富的基础类型数据处理能力。可以重命名,删除,替换和修改事件中的字段。
//Mutate 过滤器常用的配置选项
| add_field?? | ?向事件添加新字段,也可以添加多个字段 |
| remove_field | ?从事件中删除任意字段,只能删掉logstash添加的字段 如果是filebeat设置的则不能删除 |
| add_tag?? | ?向事件添加任意标签,在tag字段中添加一段自定义的内容,当tag字段中超过一个内容的时候会变成数组?? |
| remove_tag?? | ?从事件中删除标签(如果存在) |
| convert?? | ?将字段值转换为另一种数据类型 |
| id?? | ?向现场事件添加唯一的ID |
| lowercase?? | ?将字符串字段转换为其小写形式 |
| replace?? | ?用新值替换字段 |
| strip?? | ?删除开头和结尾的空格 |
| uppercase?? | ?将字符串字段转换为等效的大写字母 |
| update?? | ?用新值更新现有字段 |
| rename?? | ?重命名事件中的字段 |
| gsub?? | ?通过正则表达式替换字段中匹配到的值 |
| merge?? | ?合并数组或hash事件 |
| split | 通过指定的分隔符分割字段中的字符串为数组 |
| rename?? ? ? ? ? ? ? ? | 重命名事件中的字段 |
| gsub?? ? ? ? ? ? ? ? | 通过正则表达式替换字段中匹配到的值 |
| merge?? ? ? ? ? ? ? ? | 合并数组或 hash 事件 |
| split ? ? ? ? ? ? ?? | 通过指定的分隔符分割字段中的字符串为数组 |
步骤一:准备测试文件filebeat.conf?
[root@nginx-test conf.d]#cat filebeat.conf
input{
beats {port => "5044"}
}
filter{
grok{
match => { "message" => "%{IP:client_addr}.*\[(?<quest_time>.*)\] \"%{WORD:quest_method} %{URIPATHPARAM:url_method} .*\" (?<response_code>\d+) .* \"(?<referer_url>.*)\" \"(?<agent>.*)\".*" }
}
mutate{
remove_field => ["message","@version","beat.name"]
add_field => {
"f1" => "one"
"f2" => "two"
}
rename => {"source" => "log_path"}
replace => { "agent" => "computer" }
gsub => ["response_code", "", "状态码" ]
}
date{
match => ["quest_time", "dd/MMM/YYYY:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
}
output{
elasticsearch{
hosts => ["192.168.20.10:9200","192.168.20.8:9200","192.168.20.18:9200"]
index => "%{[fields][server_name]}-%{[fields][log_type]}-%{[fields][from]}-%{+yyyy.MM.dd}"
}
}

步骤二:完成语法检测和启动对接
 步骤三: 刷新nginx访问页面 在kibana页面验证效果
步骤三: 刷新nginx访问页面 在kibana页面验证效果
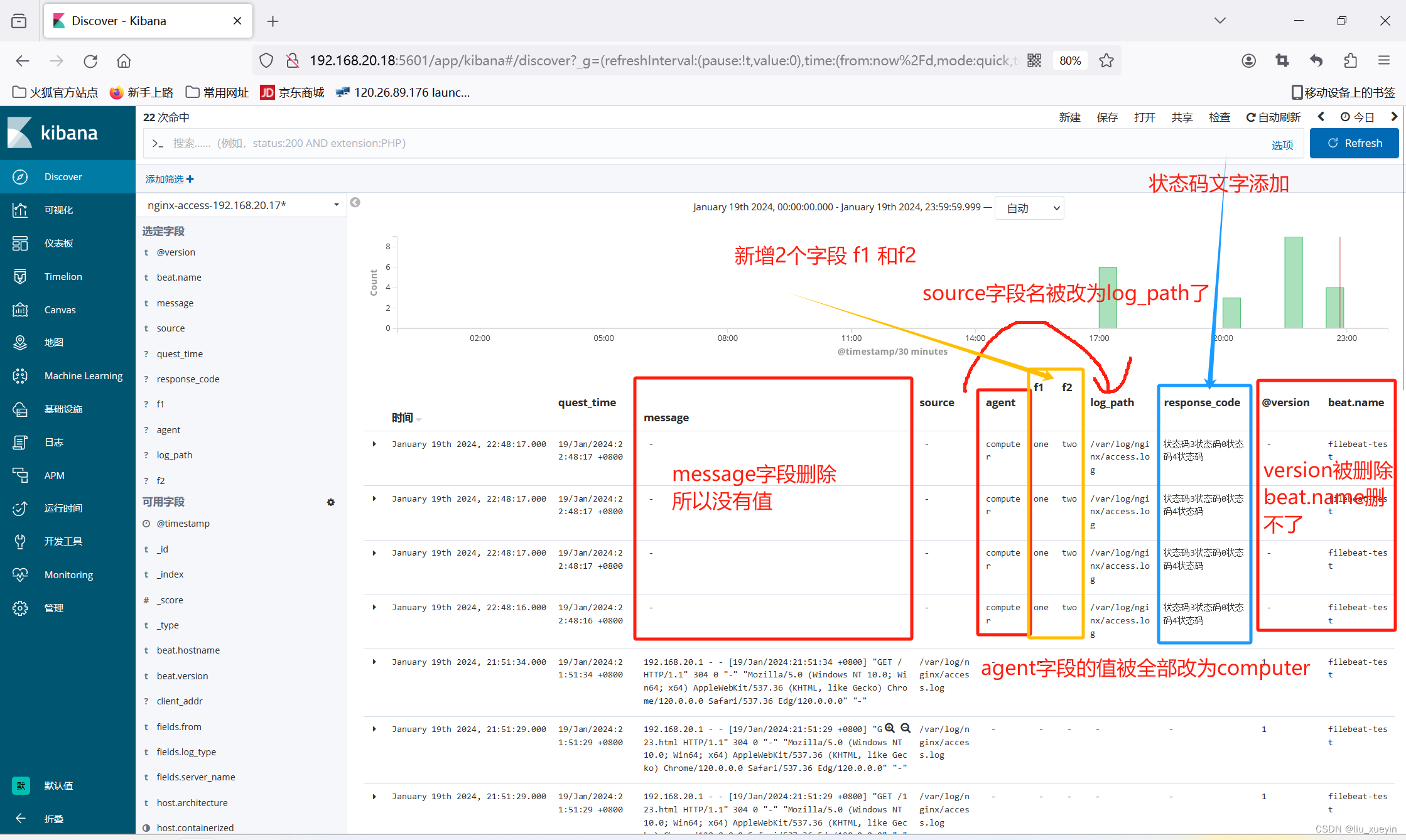
拓展?

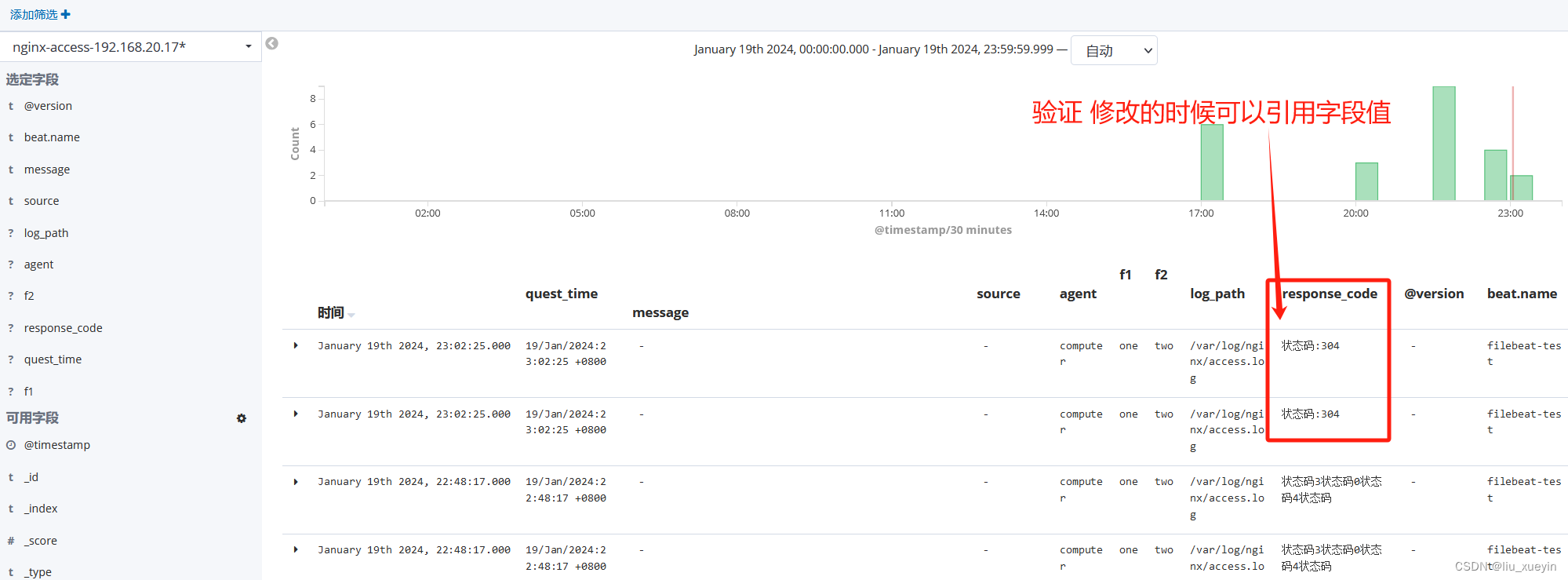
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2.3_6 用信号量实现进程互斥、同步、前驱关系
- Java SE总结(初级)
- leetcode 每日一题 2024年01月06日 在链表中插入最大公约数
- 基于ssm中小型餐厅网站的设计与实现论文
- 【C语言】linux内核ipoib模块 - ipoib_start_xmit
- 【HTML】使用canvas添加水印
- 鸿蒙开发系列教程(二)--基础应用
- Python高级数据类型
- Selenium安装WebDriver:ChromeDriver与谷歌浏览器版本快速匹配_最新版120
- 游戏开发小结——创建wave系统